Positional Encodingとは?RoPEでLLMが語順を扱う仕組みを理解する
Positional Encodingは、Attention中心のTransformerにtokenの順序情報を渡すための仕組みです。
3文要約
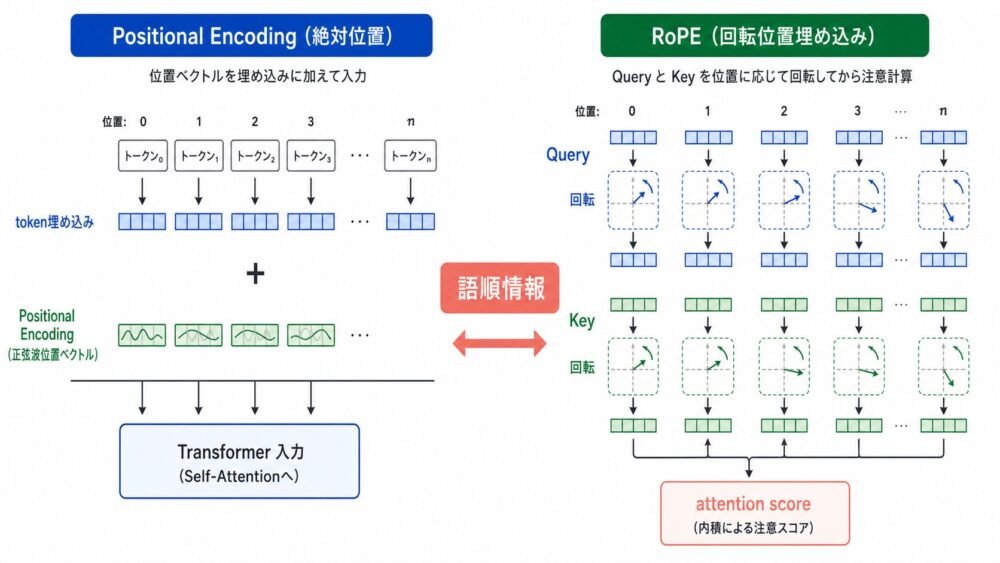
Self-Attention(同じtoken列の中でtoken同士の関係を計算する仕組み)は、位置情報を別に与えなければ、同じtoken集合の並び順を区別しにくい計算です。
そのためTransformer論文ではsin/cosで作るPositional Encodingを入力埋め込みへ足し、RoFormer論文ではQueryとKeyを位置に応じて回転させるRoPE(Rotary Position Embedding、回転で位置を表す方法)を提案しました。
RoPEの要点は、Attention scoreに絶対位置を注入しながら、QueryとKeyの内積が位置差に依存する形を作り、長い入力でも語順と距離をAttentionで扱いやすくすることです。
論文情報
| 項目 | 内容 |
|---|---|
| 論文タイトル | RoFormer: Enhanced Transformer with Rotary Position Embedding |
| 著者 | Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, Yunfeng Liu |
| 初版公開日 | 2021年4月20日 |
| 最終改訂 | 2023年11月27日 v5 |
| 分野 | Computation and Language |
| arXiv | RoFormer: Enhanced Transformer with Rotary Position Embedding |
| DOI | 10.48550/arXiv.2104.09864 |
| 関連論文 | Attention Is All You Need |
なぜTransformerに位置情報が必要なのか
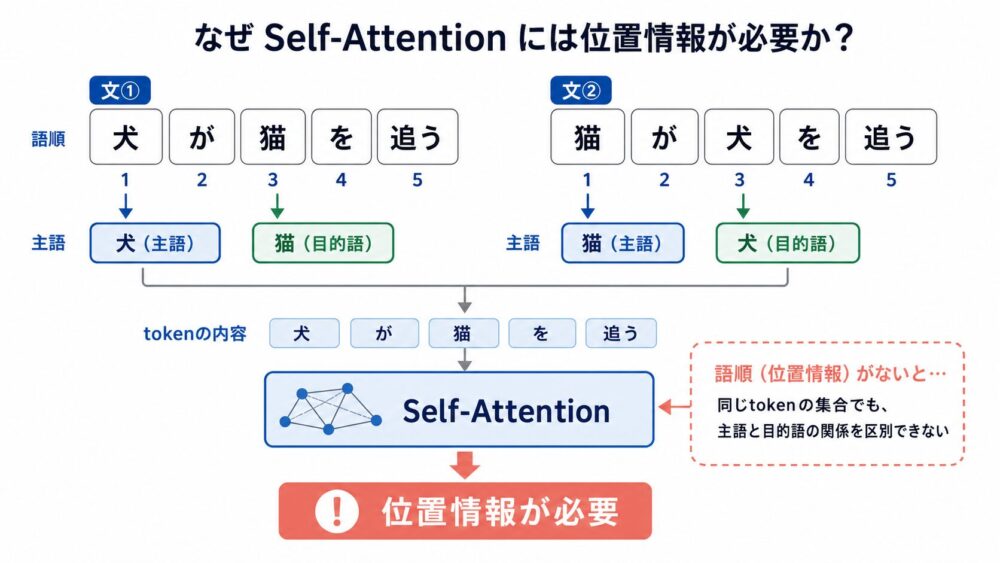
先ほどのSelf-Attention編では、QueryとKeyの内積から「どのtokenを見るか」を決める流れを整理しました。
この計算は、token同士をまとめて比較しやすい一方で、RNN(前の状態を次へ渡しながら系列を読むニューラルネットワーク)のように処理順そのものへ語順が埋め込まれているわけではありません。
たとえば、次の2文はtokenの並び順が違います。
| 文 | token列 | 意味の違い |
|---|---|---|
| 文A | 犬 が 猫 を 追う |
犬が追う側 |
| 文B | 猫 が 犬 を 追う |
猫が追う側 |
tokenの内容だけを見て順序を無視すると、主語と目的語の関係を誤解しやすくなります。
そこでTransformerでは、各tokenに「何番目に現れたか」という情報を添えます。
これにより、LLMは長文の入力を受け取ったときでも、文字やtokenの順序を手がかりにして、正しく注目すべき語彙へAttentionを向けやすくなります。
位置情報が弱いと、同じ語彙が何度も出てくる長い文脈で「どの語が、どの語に対応しているのか」を学習しづらくなります。
つまりPositional Encodingは、単なる補助情報ではなく、Attentionの重みを語順に沿って学習するための重要な仕組みです。
位置情報の入れ方には複数の選択肢があります。
| 方式 | 位置情報を入れる場所 | 強み | 注意点 |
|---|---|---|---|
| 学習可能なabsolute position embedding | token embeddingへ足す | 実装が単純で学習データに適応しやすい | 学習済み範囲外の長さへそのまま一般化しにくい |
| sinusoidal Positional Encoding | sin/cosベクトルをtoken embeddingへ足す | 位置ベクトルを固定式で作れる | Attention scoreで相対位置を直接設計する方式ではない |
| 相対位置表現 | Attention scoreやValueへ位置差を反映する | token間の距離を扱いやすい | 実装や計算形が方式ごとに異なる |
| RoPE | QueryとKeyを回転してから内積を取る | 内積へ相対位置差を自然に残せる | 回転を適用する次元分割と実装を理解する必要がある |
RoPEは、この中で「Attentionの照合部分に位置を入れる」発想に近い方式です。
Attentionだけだと、token集合の並び順を区別しにくいという課題があります。
Transformer論文のsin/cos Positional Encodingは入力表現へ位置ベクトルを足す方式でしたが、RoFormer論文はQueryとKeyの内積そのものに回転位置を入れることで、Attention scoreに絶対位置を注入しながら、相対位置差も扱える形を提案しました。
この設計により、従来の入力加算型の位置表現だけでは直接表しにくかった「どの位置にあるtoken同士が、どれだけ離れているか」をAttention score側で扱いやすくなります。
Transformerのsin/cos Positional Encoding
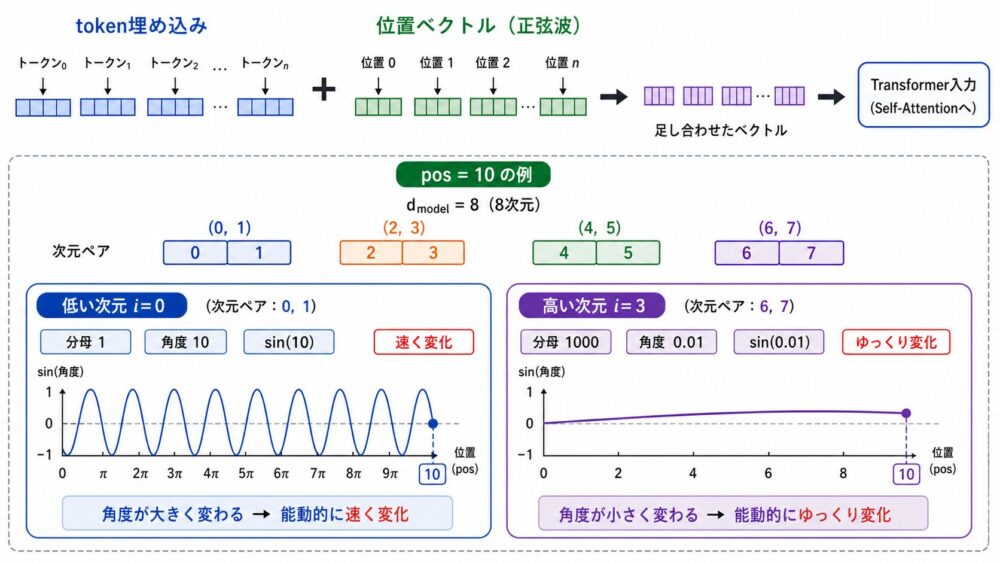
Transformer論文では、入力のtoken embeddingへPositional Encoding(位置情報を表すベクトル)を足します。
偶数次元と奇数次元には、それぞれsinとcosを使います。
補足:ここでいう偶数次元・奇数次元は、「2番目、4番目に出現したtoken」という意味ではありません。 1つのtoken embeddingは、たとえば512次元のようなベクトルです。 そのベクトルの中の0番目、2番目、4番目の成分にsinを使い、1番目、3番目、5番目の成分にcosを使う、という意味です。 つまりtokenの出現順は \(pos\) が表し、偶数・奇数は各tokenが持つベクトル成分の番号を表します。
\[
PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d_{\mathrm{model}}}}\right)
\]
\[
PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{\mathrm{model}}}}\right)
\]
\(pos\) はtoken位置、\(i\) は次元ペアの番号、\(d_{\mathrm{model}}\) はモデルの隠れ次元です。
補足:たとえば \(d_{\mathrm{model}}=8\) とすると、次元ペアは \((0,1)\)、\((2,3)\)、\((4,5)\)、\((6,7)\) の4組になります。このとき、\(i=0\) のペアは \(\sin(pos)\) と \(\cos(pos)\) に近い速く変化する波になり、\(i\) が大きいペアほど分母が大きくなるため、\(pos\) が1つ進んでも値の変化がゆっくりになります。具体的には、\(d_{\mathrm{model}}=8\) のとき、\(i=0\) では分母が \(1\)、\(i=3\) では分母が \(10000^{6/8}=1000\) になります。そのため、\(pos=10\) に対して、低い次元では \(\sin(10)\) のように大きく位相が進み、高い次元では \(\sin(10/1000)\) のようにほとんど変化しない値になります。
低い次元では速く変化する波、高い次元ではゆっくり変化する波を使うため、位置ごとに異なるパターンを作れます。
| 観点 | sinusoidal Positional Encodingの見方 |
|---|---|
| 入力 | token embeddingに足す |
| パラメータ | 位置ベクトル自体は固定式 |
| 直感 | 各位置へ複数周期の波形指紋を付ける |
| 役割 | Attention層へ入る前に順序の手がかりを渡す |
この方式はTransformerの基礎を理解するうえで重要です。
一方でRoFormer論文は、Attention scoreに相対位置を反映する観点から別の構成を考えます。
absolute positionとrelative positionの違い
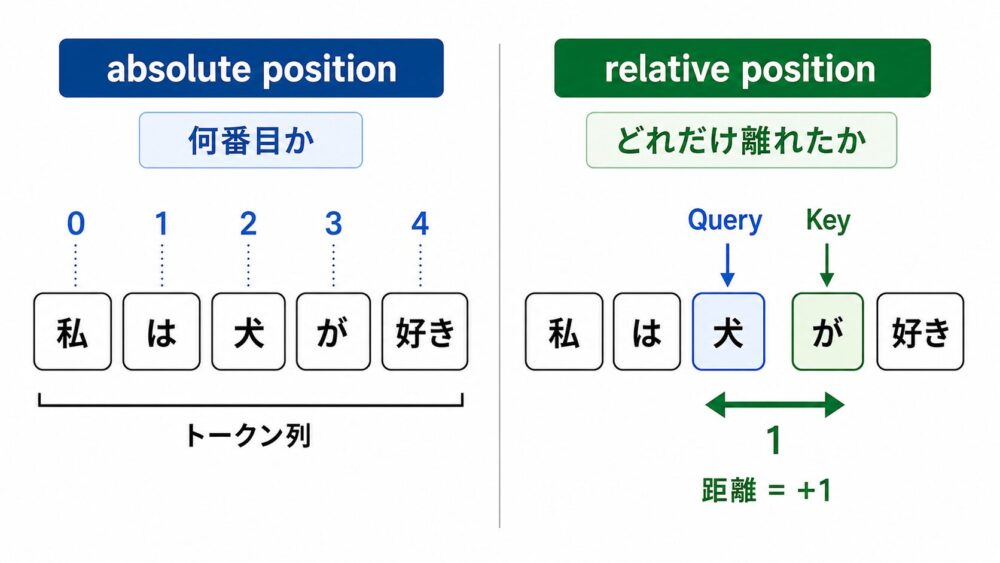
absolute position(絶対位置)は、「このtokenは系列の3番目」のように各token単体の場所を表します。
relative position(相対位置)は、「Query位置からKey位置まで2 token離れている」のようにtokenペアの位置差を表します。
| 観点 | absolute position | relative position |
|---|---|---|
| 問い | tokenは何番目か | token同士はどれだけ離れているか |
| 例 | 追う は4番目 |
追う から 犬 は3 token前 |
| Attentionとの関係 | 入力表現へ位置を足す方式が多い | score計算へ距離を入れる方式が多い |
| 長文で気になる点 | 位置番号の範囲をどう扱うか | 遠距離関係をどう表すか |
LLMで位置表現を考えるときは、「どの位置か」と「どれだけ離れたか」を分けると整理しやすくなります。
LLMは、位置情報を正確に扱えないと、推論結果に大きな影響を受けます。
特に長い文脈では、同じ語や似た表現が何度も現れるため、Attentionが「近い語を見るべきか」「遠くの対応語を見るべきか」を学習しづらくなります。
そのため、token単体の場所を表すabsolute positionと、token同士の距離を表すrelative positionを分けて設計することが重要になります。
RoPEは、位置 \(m\) のQueryと位置 \(n\) のKeyを回転させ、内積には位置差が現れるように設計します。
RoPEの直感:位置ごとにベクトルを回転する
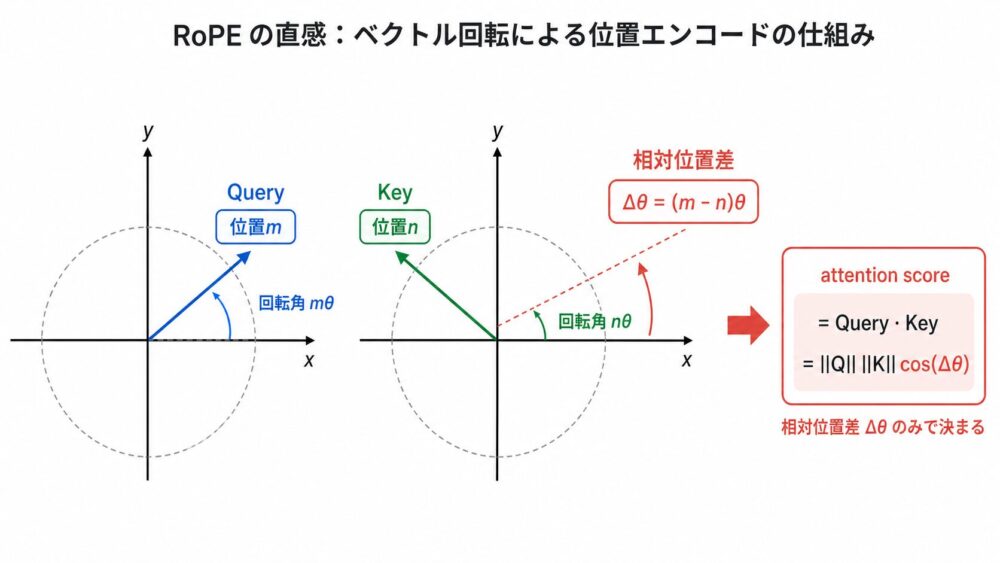 位置mと位置nでQueryとKeyを回転し相対角度差を内積へ残す流れ
位置mと位置nでQueryとKeyを回転し相対角度差を内積へ残す流れ
Attentionでは、QueryとKeyの内積を取ることで類似度を計算し、各tokenがどこに着目すればよいかを学習していきます。
RoPEでは、この内積にベクトルの回転も考慮させることで、絶対位置と相対位置という概念をAttention scoreへ取り入れます。
LLMが実際に扱う高次元ベクトルの回転をそのまま考えると難しいため、まずは2次元平面上の回転として直感的に見ていきます。
位置 \(m\) の2次元ベクトルを角度 \(m\theta\) だけ回す回転行列は、次のように書けます。
\[
R_{\Theta,m}^{(2)} =
\begin{pmatrix}
\cos(m\theta) & -\sin(m\theta) \\
\sin(m\theta) & \cos(m\theta)
\end{pmatrix}
\]
QueryとKeyへ同じ考え方の回転を適用すると、位置 \(m\) のQueryと位置 \(n\) のKeyの類似度は、回転差 \(\Delta\theta\) に依存します。
\[
\left(R_{\Theta,n}^{d} k\right)^T
\left(R_{\Theta,m}^{d} q\right)
=
k^T R_{\Theta,m-n}^{d} q
\]
式の右辺には、位置差 \(m-n\) が残っています。
これは画像の \(\Delta\theta=(m-n)\theta\) と同じ向きで書いた形です。
Attention実装では通常 \(q_m^T k_n\) と書くため、同じスカラーを \(q^T R_{\Theta,n-m}^{d} k\) と表すこともできます。
どちらも同じ内積を別の向きから書いたもので、重要なのは絶対位置 \(m\) と \(n\) そのものではなく、回転差 \(\Delta\theta\)、つまり位置差がAttention scoreに残る点です。
つまりRoPEは、各tokenの絶対位置を使って回転を決めながら、Attentionの照合では相対位置差を使いやすい形を作ります。
これにより、入力へ位置ベクトルを足すだけの方式よりも、Attention scoreの中で絶対位置と相対位置を同時に考慮しやすくなります。
| たとえ | RoPEで対応するもの |
|---|---|
| ベクトルの向き | QueryやKeyの特徴 |
| 回転角 | token位置に応じた位相 |
| 2本の矢印の角度差 | token間の相対位置差 |
| 内積 | Attention scoreの材料 |
RoPEの数式を多次元で見る
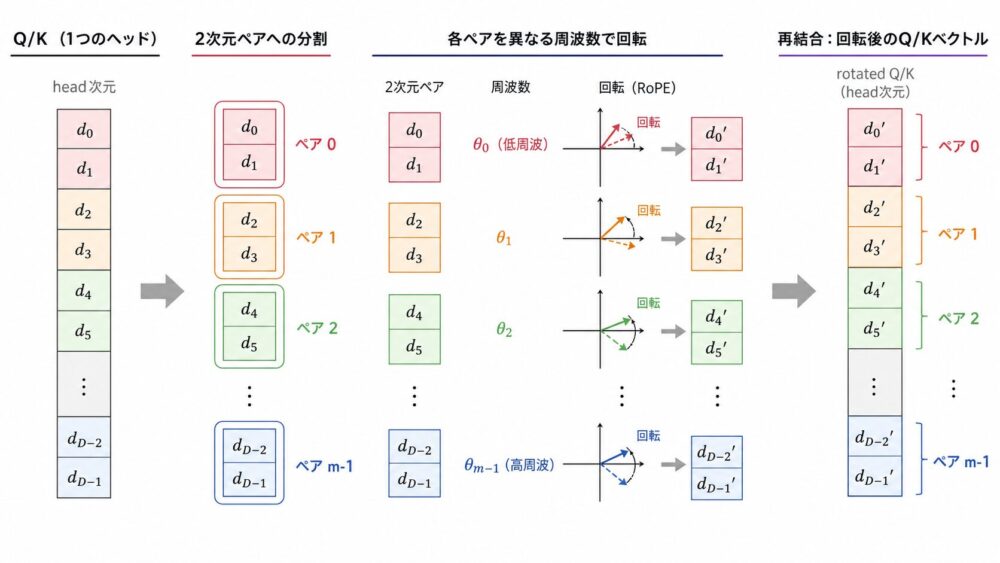
実際のAttention headは2次元ではありません。
RoFormer論文では、head次元 \(d\) が偶数であることを前提に、ベクトル成分を \((0,1)\)、\((2,3)\)、\((4,5)\) のような2次元ペアへ分けます。
補足:ここで偶数次元というのは「偶数番目のtoken」ではなく、「head_dimが2で割り切れる」という意味です。各ペアの1つ目と2つ目の成分を、2次元平面の \(x\) 成分と \(y\) 成分のように扱い、位置に応じて回転させます。\(d_0\) がQueryで \(d_1\) がKeyという対応ではありません。 QueryもKeyも、それぞれ同じhead次元を持つベクトルであり、その各ベクトルの中に2次元ペアがあります。RoPEは、位置 \(m\) にあるQueryには \(m\) に応じた回転を、位置 \(n\) にあるKeyには \(n\) に応じた回転を適用します。周波数そのものは次元ペアごとに固定された設計値で、任意に学習される回転ではありません。位置が変わると、固定された周波数に位置番号を掛けた角度が変わるため、QueryとKeyの位置差がAttention scoreへ反映されます。
周波数は次の形で置かれます。
\[
\theta_i = 10000^{-2(i-1)/d}, \quad i \in [1, 2, \ldots, d/2]
\]
補足:この \(10000\) はTransformerのsinusoidal Positional Encodingでも使われている周波数スケールの設計値です。学習で更新されるパラメータではなく、低い次元から高い次元まで異なる周期の波を広く用意するための固定定数です。実装によっては、この値を
baseやrope_thetaとして変更できることがあります。
位置 \(m\) のtoken表現 \(x_m\) から作ったQueryまたはKeyは、次のように表せます。
\[
f_{\{q,k\}}(x_m, m) = R_{\Theta,m}^{d} W_{\{q,k\}} x_m
\]
ここで \(x_m\) は位置 \(m\) にあるtokenの特徴表現です。
\(W_q\) と \(W_k\) は、その特徴表現からQuery用ベクトルとKey用ベクトルを作るための学習済み重み行列です。
つまり、同じtoken表現 \(x_m\) を「探す側の手がかり」であるQueryと、「照合される側の手がかり」であるKeyへ変換します。
\(R_{\Theta,m}^{d}\) は位置 \(m\) に応じた回転を表します。
Keyが位置 \(n\) にある場合は、同じ式で \(m\) を \(n\) に置き換え、\(R_{\Theta,n}^{d} W_k x_n\) として回転させます。
そのため、Query側の絶対位置だけでなく、Key側の絶対位置も考慮され、最終的な内積には両者の位置差が現れます。
論文では、\(R_{\Theta,m}^{d}\) をそのまま密行列で掛けるのではなく、sin/cosと要素の組み替えで効率よく計算できる形も示しています。
RoPEで押さえたいポイントは次の3つです。
- QueryとKeyに適用する。
- head次元を2次元ペアとして回転する。
- 回転は固定された周波数とtoken位置で決まり、その後の内積が位置差を含むAttention scoreになる。
実装イメージ:PyTorchでRoPEを適用する
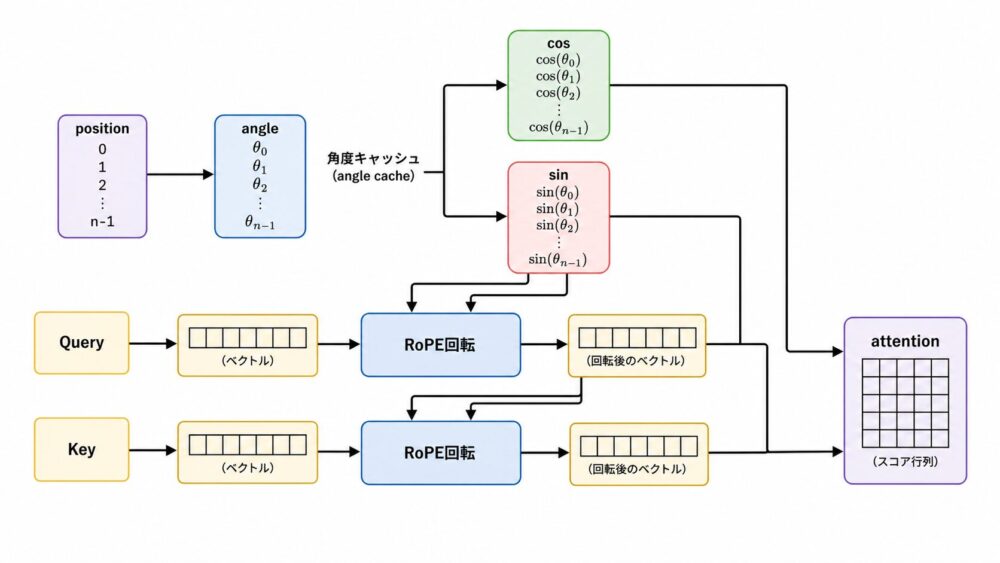
以下は、RoPEの回転部分だけを追うための最小例です。
実際のモデルでは、cos/sinをキャッシュしたり、head次元の並べ方に合わせて実装を最適化したりします。
import logging
from typing import Tuple
import torch
from torch import Tensor
logger = logging.getLogger(__name__)
def build_rope_cache(
sequence_length: int,
head_dim: int,
device: torch.device,
base: float = 10000.0,
) -> Tuple[Tensor, Tensor]:
"""Build cosine and sine caches for rotary position embedding.
Args:
sequence_length: Number of token positions to encode.
head_dim: Per-head hidden dimension. It must be even.
device: Device where the cache tensors should be allocated.
base: Frequency base used by the rotary schedule.
Returns:
A pair `(cos, sin)` with shape `(1, 1, sequence_length, head_dim / 2)`.
Raises:
ValueError: If `sequence_length` is less than 1.
ValueError: If `head_dim` is not a positive even number.
ValueError: If `base` is not greater than 1.
Example:
>>> cos, sin = build_rope_cache(4, 8, torch.device("cpu"))
>>> cos.shape
torch.Size([1, 1, 4, 4])
"""
if sequence_length < 1:
logger.error("sequence_length must be positive")
raise ValueError("sequence_length must be positive")
if head_dim < 2 or head_dim % 2 != 0:
logger.error("head_dim must be a positive even number")
raise ValueError("head_dim must be a positive even number")
if base <= 1:
logger.error("base must be greater than 1")
raise ValueError("base must be greater than 1")
pair_indices: Tensor = torch.arange(0, head_dim, 2, device=device)
inverse_frequencies: Tensor = base ** (-pair_indices / head_dim)
positions: Tensor = torch.arange(sequence_length, device=device)
angles: Tensor = positions[:, None] * inverse_frequencies[None, :]
logger.debug(
"built rope cache",
extra={"sequence_length": sequence_length, "head_dim": head_dim},
)
return angles.cos()[None, None, :, :], angles.sin()[None, None, :, :]
def apply_rope(x: Tensor, cos: Tensor, sin: Tensor) -> Tensor:
"""Rotate Attention vectors with rotary position embedding.
Args:
x: Tensor with shape `(batch, heads, sequence_length, head_dim)`.
cos: Cosine cache broadcastable to the even/odd dimension pairs of `x`.
sin: Sine cache broadcastable to the even/odd dimension pairs of `x`.
Returns:
Tensor with the same shape as `x`.
Raises:
ValueError: If the last dimension of `x` is not even.
ValueError: If `cos` and `sin` do not have matching shapes.
Example:
>>> q = torch.randn(2, 4, 3, 8)
>>> cos, sin = build_rope_cache(3, 8, q.device)
>>> apply_rope(q, cos, sin).shape
torch.Size([2, 4, 3, 8])
"""
if x.size(-1) % 2 != 0:
logger.error("RoPE requires an even head dimension")
raise ValueError("x must have an even last dimension")
if cos.shape != sin.shape:
logger.error("cos and sin caches must match")
raise ValueError("cos and sin must have matching shapes")
even: Tensor = x[..., 0::2]
odd: Tensor = x[..., 1::2]
# 2次元ペアを保つことで、回転行列を密に作らず同じ幾何を実装できるためです。
rotated_even: Tensor = even * cos - odd * sin
rotated_odd: Tensor = even * sin + odd * cos
rotated: Tensor = torch.stack((rotated_even, rotated_odd), dim=-1)
logger.debug("applied rope rotation", extra={"shape": tuple(x.shape)})
return rotated.flatten(-2)Attentionへ入れるときは、QueryとKeyを回転し、Valueは通常そのままにします。
rotated_query: Tensor = apply_rope(query, cos, sin)
rotated_key: Tensor = apply_rope(key, cos, sin)この位置が、入力埋め込みへベクトルを足すsinusoidal Positional Encodingとの大きな違いです。
RoFormer論文の実験結果をどう読むか
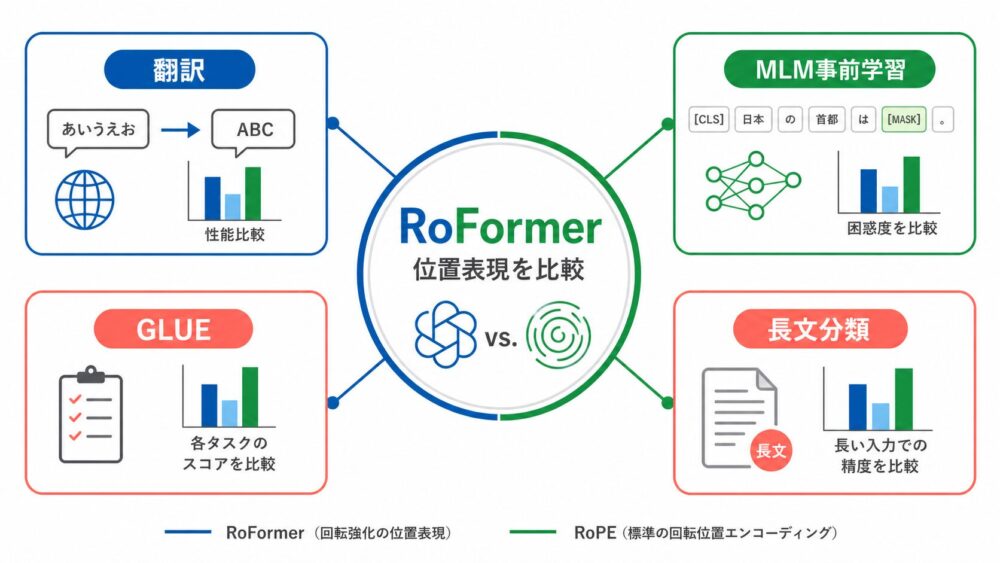
RoFormer論文は、RoPEを位置表現の提案だけで終わらせず、複数のタスクで比較しています。
| 実験 | 比較の観点 | 論文での読みどころ |
|---|---|---|
| WMT14 English-German翻訳 | 位置表現を入れたTransformerとの比較 | RoPEを持つRoFormerが既存の位置表現と競合する結果を報告 |
| MLM事前学習 | BERT、BERT+位置方式、RoFormer | 事前学習曲線と下流GLUE評価を比較 |
| GLUE | 事前学習済みモデルの下流性能 | 平均スコアでRoFormerが比較対象を上回る表を提示 |
| 長文中国語テキスト分類 | 学習時より長い文への一般化 | train 512 tokenからtest 1024 tokenへ伸ばす設定で評価 |
たとえばGLUE表では、RoFormerがAverage 78.8を報告し、同表のBERT 75.8、BERT+Sinusoidal 76.8、BERT+Relative 77.4を上回っています。
長文中国語分類では、512 tokenで学習したモデルを1024 token評価へ広げた表で、RoFormerはIFLYTEKとCMeEEの双方で比較対象より高い値を報告しています。
ただし、これらはRoFormer論文内の実験条件で得られた結果です。
RoPEを採用すれば任意のLLMが無条件に長文へ強くなる、と読むのは行き過ぎです。
長いコンテキストでは、位置表現だけでなく学習長、データ、Attention計算、KV Cache、推論実装も効いてきます。
よくある誤解
| 誤解 | 正確な見方 |
|---|---|
| Attentionだけで語順は自然に分かる | Attention中心のモデルでは位置情報を別に渡す必要がある |
| Positional Encodingはtoken IDを並べるだけ | ベクトル表現へ位置の手がかりを加える設計全体を指す |
| sinusoidal Positional EncodingとRoPEは同じ場所に入る | 前者は入力埋め込みへ足す基本形、RoPEはQueryとKeyの回転として使う |
| RoPEはrelative positionしか使わない | 回転角は各絶対位置で決まり、内積に相対位置差が現れる構成 |
| RoPEで長文問題は完全に解決する | 論文は外挿性を評価しているが、長文性能は学習条件や実装にも依存する |
| Valueにも必ずRoPEを掛ける | Attention scoreの位置関係を作る基本形ではQueryとKeyへ適用する |
まとめ
Transformerでは、Self-Attentionの強みを活かすために位置情報を別途与える必要があります。
sin/cos Positional Encodingは、固定式で作った位置ベクトルをtoken embeddingへ足すTransformerの基本方式です。
RoPEは、QueryとKeyを位置ごとに回転し、Attention scoreへ相対位置差が現れる構造を作ります。
2次元の回転をhead次元のペアへ拡張すると、RoPEの式と実装は追いやすくなります。
RoFormer論文は翻訳、事前学習、GLUE、長文分類でRoPEを評価していますが、その結果は位置表現以外の条件も含む実験として読む必要があります。
次にDecoder-only Transformerを見ると、RoPEのような位置表現がcausal Self-Attentionの中でどこに効くかを結び付けやすくなります。
関連技術
| 技術 | Positional Encoding / RoPEとの関係 |
|---|---|
| Self-Attention | 位置情報を使ってtoken間の関係を計算する中心部 |
| Multi-Head Attention | 各headのQueryとKeyへRoPEを適用する実装が現れる |
| Relative Position Encoding | token間の位置差をAttentionへ反映する考え方 |
| Decoder-only Transformer | causal Self-Attentionと位置表現を組み合わせるGPT系構造 |
| Long Context | 長い系列で位置表現、学習長、推論実装を一緒に考える領域 |
次に読むべき記事
- GPT系LLMの構造とは?Decoder-only Transformerをやさしく解説
- KV Cacheとは?LLMの生成を高速化する仕組み
- FlashAttentionとは?Attentionを高速化する技術
- Long Contextとは?LLMが長文を扱う仕組み

コメント