 AI関連論文
AI関連論文 保護中: GPUとNPUの違いとは?アーキテクチャと行列演算のデータフローを比較
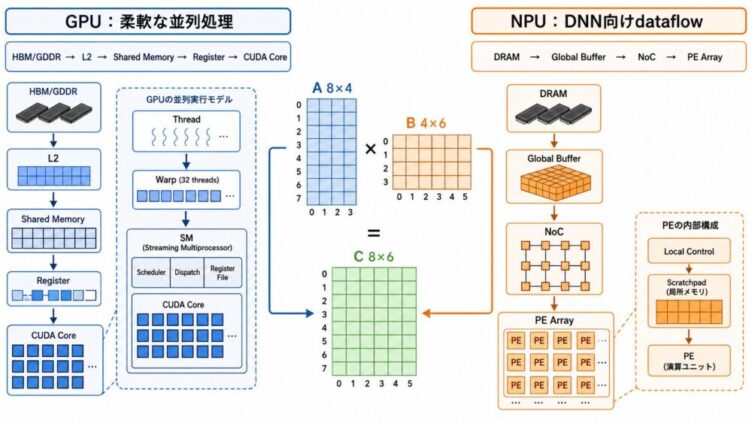
GPUとNPUの違いを、回路構成と同じ8×4×6行列のデータフローで比較。SM、warp、Shared Memory、Global Buffer、NoC、PE Array、Systolic Array、EyerissのRow Stationary、電力効率を一次資料ベースで解説します。
AI関連論文  AI関連論文
AI関連論文  AI関連論文
AI関連論文  AI関連論文
AI関連論文 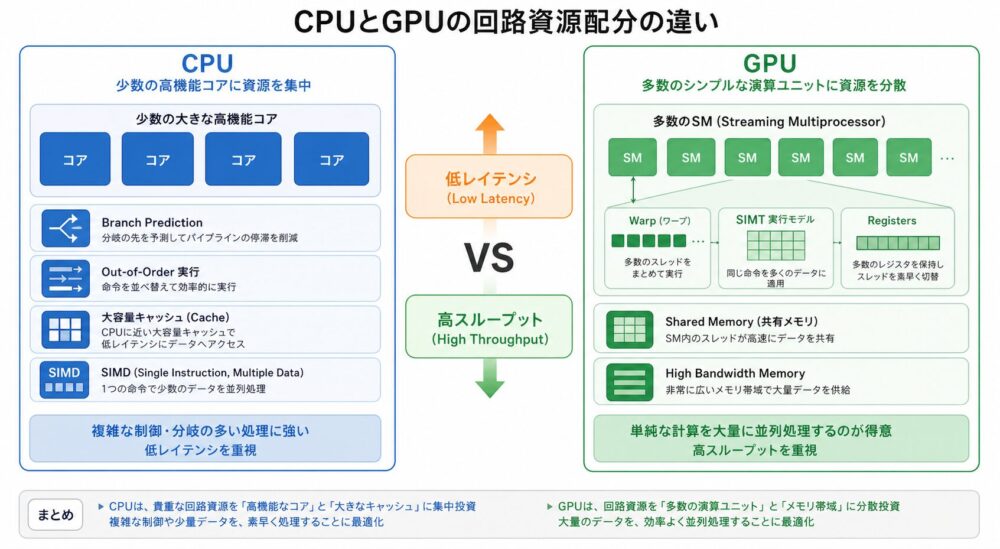 AI関連論文
AI関連論文 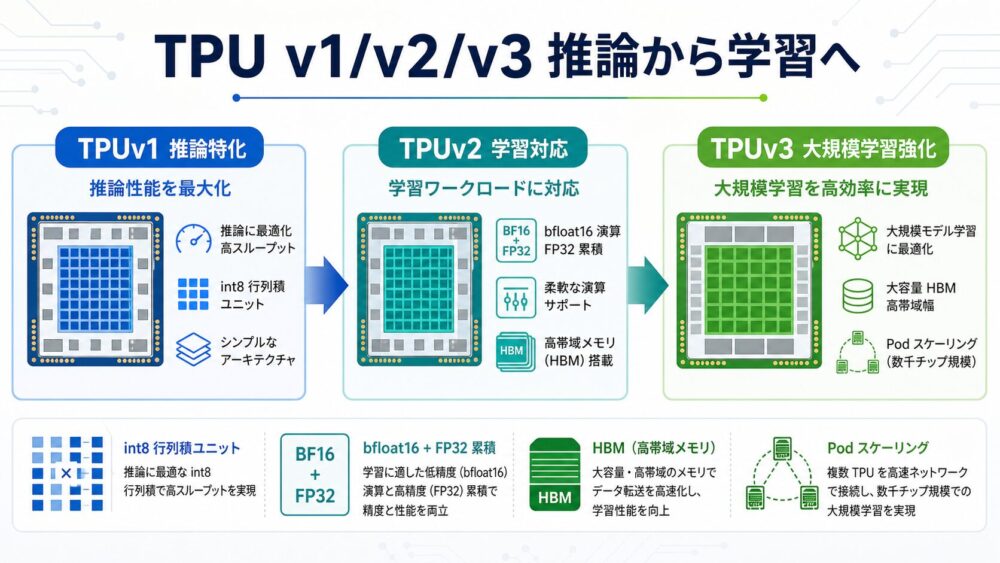 AI関連論文
AI関連論文 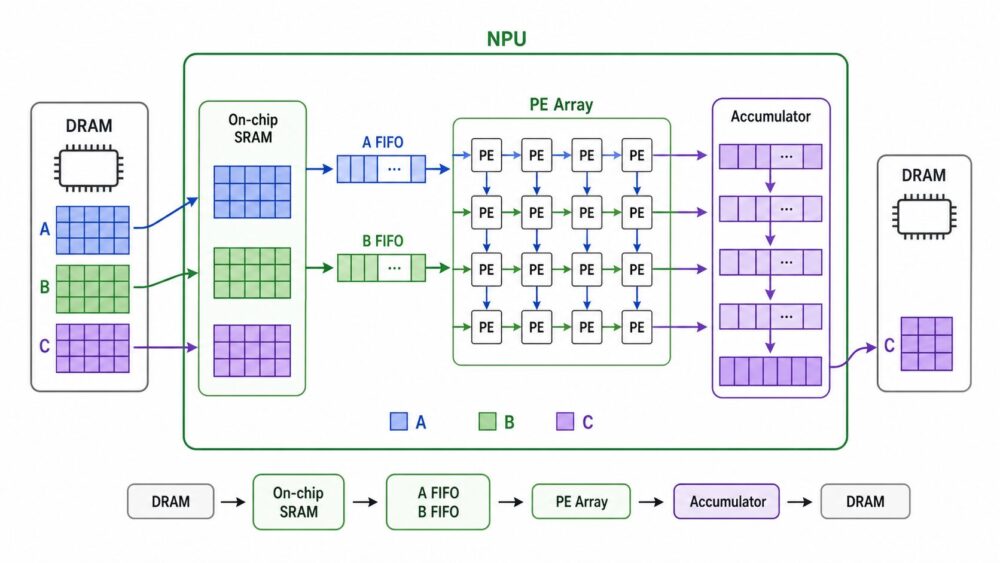 AI関連論文
AI関連論文 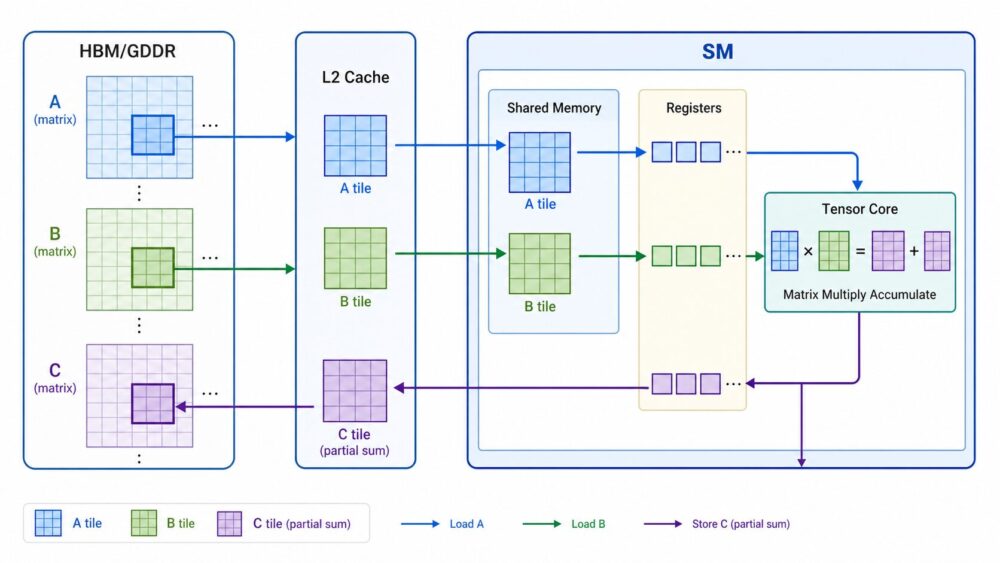 AI関連論文
AI関連論文 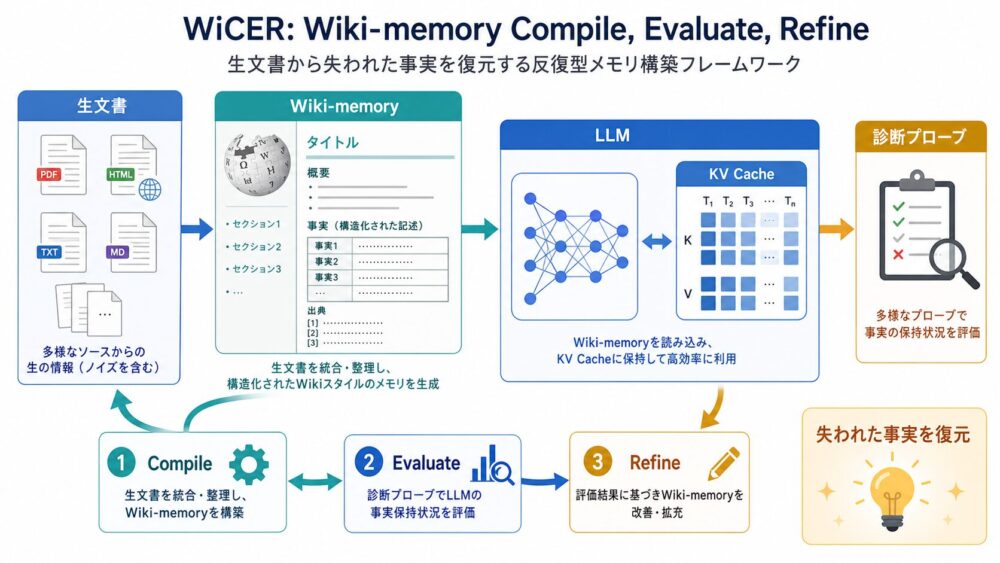 AI関連論文 AI関連論文 AI関連論文 AI関連論文 AI関連論文 AI関連論文 AI関連論文 AI関連論文 AI関連論文 AI関連論文
AI関連論文 AI関連論文 AI関連論文 AI関連論文 AI関連論文 AI関連論文 AI関連論文 AI関連論文 AI関連論文 AI関連論文  カメラ
カメラ  カメラ
カメラ  カメラ
カメラ  カメラ
カメラ  カメラ
カメラ  カメラ
カメラ  カメラ
カメラ  カメラ
カメラ  カメラ
カメラ  カメラ
カメラ  映画
映画  映画
映画  かぐや様は告らせたい~天才たちの恋愛頭脳戦~
かぐや様は告らせたい~天才たちの恋愛頭脳戦~  BLUE GIANT
BLUE GIANT  かぐや様は告らせたい~天才たちの恋愛頭脳戦~
かぐや様は告らせたい~天才たちの恋愛頭脳戦~  かぐや様は告らせたい~天才たちの恋愛頭脳戦~
かぐや様は告らせたい~天才たちの恋愛頭脳戦~  BLUE GIANT
BLUE GIANT