【論文解説】LLMはなぜ日本文化に寄りがちなのか?CROQで見る文化・地域バイアス
3文要約
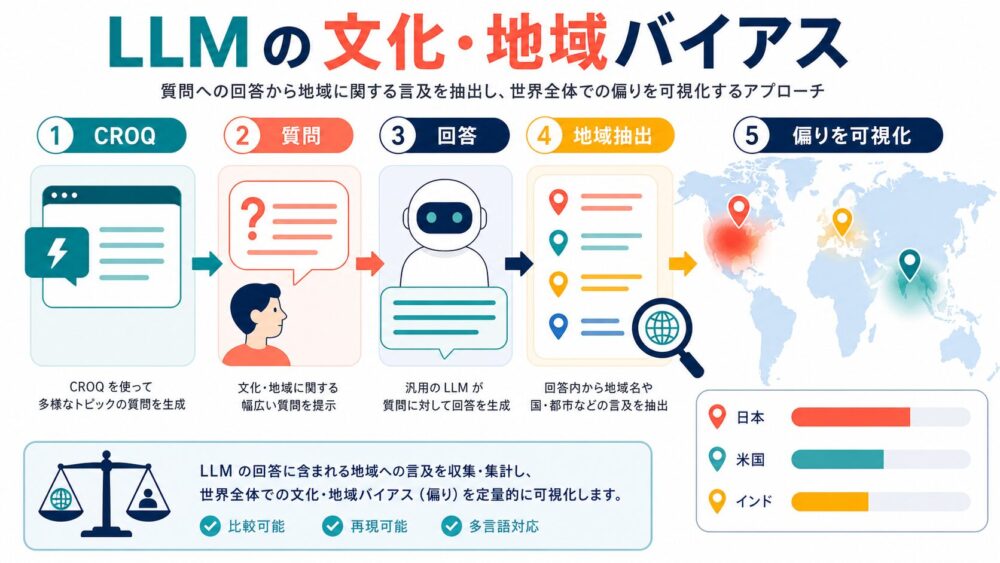
この論文は、LLM(Large Language Model、大規模言語モデル)が文化に関する曖昧な質問へ答えるとき、どの国や地域を暗黙に選びやすいのかを調べた研究です。
著者らは、CROQ(Culture-Related Open Questions、文化に関する自由回答型質問データセット)を作り、24言語・31,680問で複数のLLMの回答を分析しています。
論文では、入力言語の公用国への強い偏りに加えて、外部参照では日本、米国、インドなど一部の国が目立つこと、さらにその偏りは事前学習よりもSFT(Supervised Fine-Tuning、教師あり微調整)後に強まりやすいことが示されています。
論文情報
| 項目 | 内容 |
|---|---|
| 論文タイトル | Why are all LLMs Obsessed with Japanese Culture? On the Hidden Cultural and Regional Biases of LLMs |
| 著者 | Joseba Fernandez de Landa, Carla Perez-Almendros, Jose Camacho-Collados |
| 発表年 | 2026年 |
| arXiv | arXiv:2604.21751v1 |
| 公開日 | 2026年4月23日 |
| 論文リンク | Why are all LLMs Obsessed with Japanese Culture? On the Hidden Cultural and Regional Biases of LLMs |
何を調べた論文か:LLMの「文化的な初期値」を測る
この論文が扱う問いは、「LLMは文化の話をするとき、どの地域を自然に思い浮かべるのか」です。
たとえば、「家族生活を形づくる価値観は何か」「どのような伝統舞踊があるか」のような質問は、国や地域を指定しないと複数の正解があり得ます。
このような質問に対して、LLMが日本、米国、インド、中国、フランスなど、どの地域に回答を寄せるのかを分布として見ます。
重要なのは、この研究が「文化的に正しい答え」を採点しているわけではない点です。
正誤判定ではなく、自由回答に現れる地域参照の偏りを観察しています。
背景:文化ベンチマークだけでは見えにくい偏り
既存の文化ベンチマーク(評価用データセット)では、多くの場合、選択式問題や正解ラベルつき問題でLLMの文化知識を測ります。
それは知識の有無を見るには有効です。
一方で、「正解が1つではない文化質問」に対して、LLMがどの文化圏を自然に選ぶのかは見えにくくなります。
この論文は、そこを分布として測ります。
| 評価の種類 | 見たいもの | 例 | 弱点 |
|---|---|---|---|
| 正解ラベルつきQA | 文化知識の正確性 | 祭り名、歴史、制度 | 自由回答の偏りは見えにくい |
| 規範・価値観評価 | 文化的な妥当性 | ある行動が適切か | 評価基準の設計が難しい |
| CROQ型の自由回答分析 | LLMが暗黙に選ぶ地域 | 地域未指定の文化質問 | 正しさではなく分布の分析になる |
CROQデータセット:24言語・31,680問の自由回答型質問
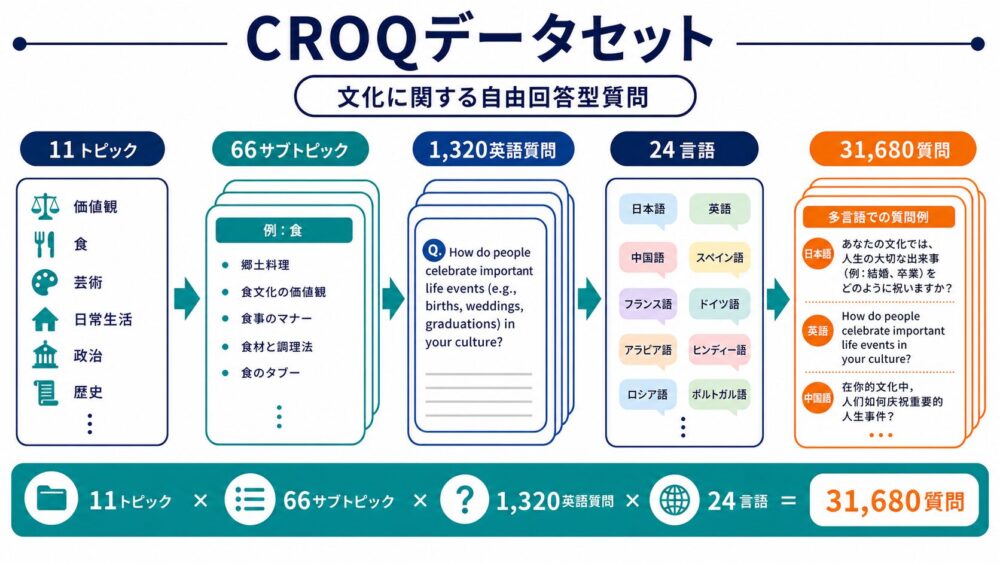
著者らは、CROQという新しいデータセットを構築しています。
CROQは、文化に関する曖昧な質問を集めたデータセットです。
| 項目 | 内容 |
|---|---|
| 大分類 | 11トピック |
| 小分類 | 66サブトピック |
| 英語質問 | 1,320問 |
| 言語数 | 24言語 |
| 総質問数 | 31,680問 |
11トピックには、信念・価値観・アイデンティティ、日常生活、教育、芸術、食、地理、政治、健康、メディア、歴史、経済などが含まれます。
質問は、地名を明示しない形で作られています。
What values shape family life {in region/place}? Be brief. Choose yourself the place.日本語で言えば、「どの地域かは自分で選び、家族生活を形づくる価値観を短く答えてください」という形です。
ここでLLMは、明示されていない地域を自分で補う必要があります。
その補い方に、モデル内部の文化的・地域的な事前分布が現れる、というのが論文の発想です。
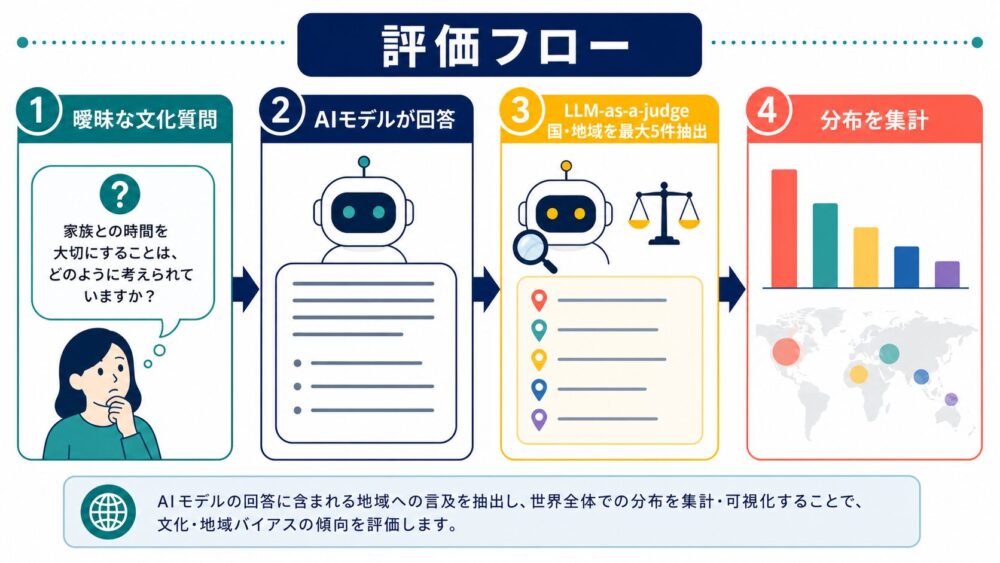
評価方法:回答から国・地域を抽出する
評価は大きく3段階です。
- CROQの質問をLLMに入力する
- LLMが自由回答を生成する
- 別のLLM-as-a-judge(LLMを評価者として使う方法)で、回答に含まれる国・地域を最大5件抽出する
論文では、LLM-as-a-judgeの抽出手順について、264件の評価で98%の精度を達成したプロンプトを採用したと説明しています。
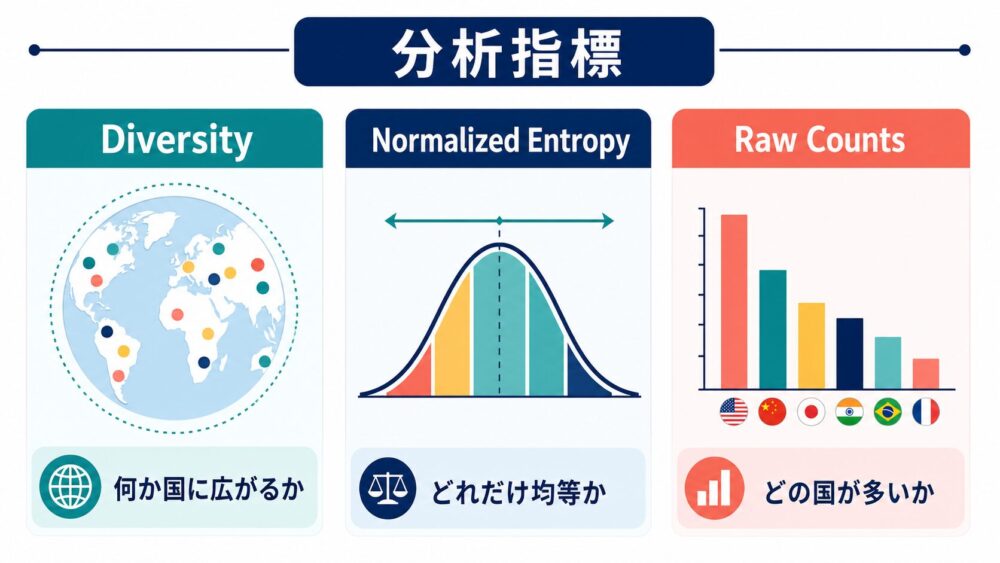
| 指標 | 意味 | 読み方 |
|---|---|---|
| Own | 入力言語の公用国への参照数 | その言語の国に寄っているか |
| Diversity | 参照された国・地域の種類数 | 広い地域に分散しているか |
| Normalized Entropy | 参照分布の均等さ | 一部の国に集中していないか |
| Raw Counts | 国・地域ごとの出現回数 | どの国が多いか |
Normalized Entropy(正規化エントロピー)は、分布の偏りを測る指標です。
国・地域の集合を\(C\)、国\(c\)が参照される確率を\(p(c)\)とすると、エントロピーは次のように書けます。
\[
H(C) = – \sum_{c \in C} p(c) \log p(c)
\]
ただし、国の種類数が多いほど最大値も大きくなるため、比較しやすいように最大値で割って正規化します。
\[
H_{\mathrm{norm}}(C) =
\frac{
– \sum_{c \in C} p(c) \log p(c)
}{
\log |C|
}
\]
\(H_{\mathrm{norm}}\)が1に近いほど、参照が複数地域へ均等に広がっていると解釈できます。
逆に0に近いほど、特定の国や地域に集中している可能性があります。
主要結果:入力言語の国に寄りやすく、日本・米国・インドも目立つ
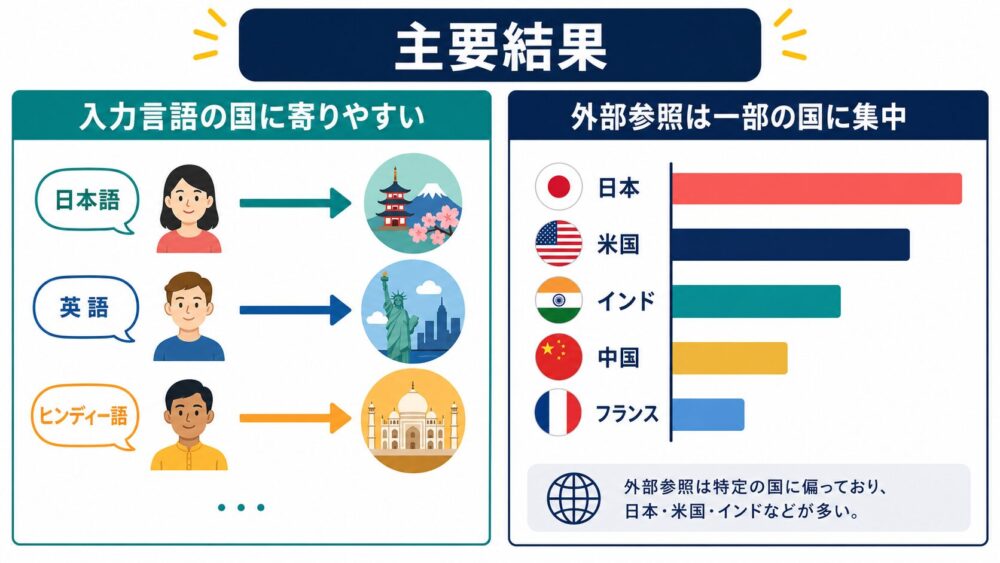
論文のRQ1では、「LLMはどのような地域文化バイアスを持つのか」が調べられています。
結果として、多くのモデルで入力言語の公用国への参照が強く現れました。
たとえば英語で質問すると英語圏、日本語で質問すると日本、スペイン語で質問するとスペイン語圏のように、言語と国の共起が回答に反映されやすい、と論文では示されています。
また、入力言語の公用国ではない外部参照を見ると、日本と米国が特に頻出し、その後にインド、中国、フランスなどが続く傾向が報告されています。
| 観点 | 論文で示された傾向 | 解釈上の注意 |
|---|---|---|
| 入力言語の影響 | 公用国への参照が多い | 言語と国の結びつきが強く出る |
| 外部参照 | 日本、米国、インド、中国、フランスが目立つ | 「その国の文化を理解している」証拠ではない |
| モデル差 | Command-Rは比較的多様、GPTやQwenなどは集中傾向 | 評価条件やモデル版で変わる可能性がある |
| トピック差 | 地理・経済では米国、政治・歴史では別傾向もある | 文化領域ごとの分析が必要 |
ここで大事なのは、「LLMは日本文化が好きだ」と読むのではなく、「自由回答で地域を選ぶとき、日本が参照されやすい分布が観測された」と読むことです。
言語の影響:高リソース言語と低リソース言語で分布が変わる
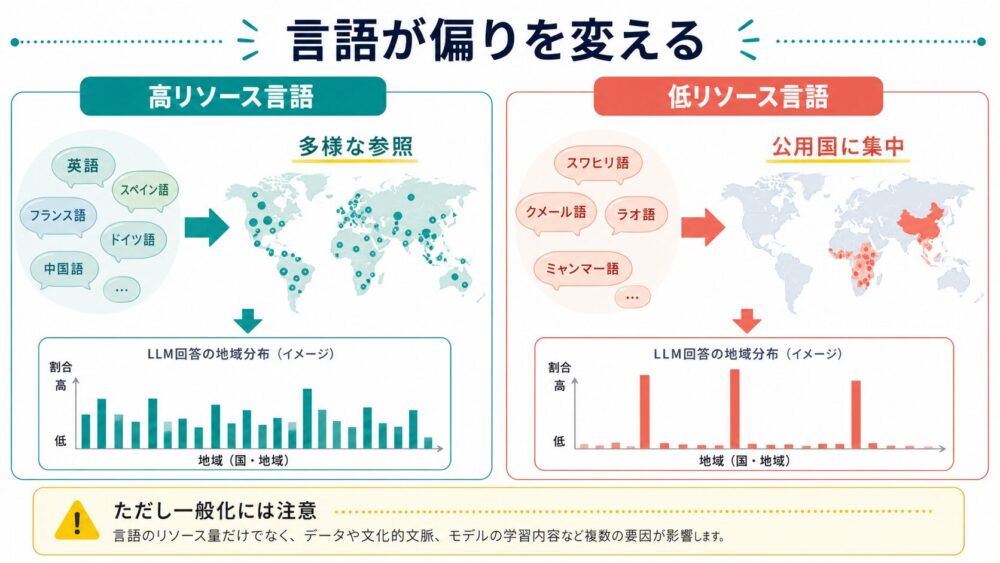
RQ2では、入力言語が地域バイアスにどう影響するかを調べています。
論文では、英語、中国語、フランス語、ロシア語などの高リソース言語(学習データが比較的多い言語)では、参照される国・地域がやや広がりやすい傾向が示されています。
一方で、アムハラ語、スンダ語、アッサム語、ハウサ語、バスク語などの低リソース言語(学習データが比較的少ない言語)では、入力言語の公用国への参照や未回答が増え、分布が狭くなりやすいと論文では説明されています。
| 言語条件 | 典型的な傾向 | 何が起きている可能性があるか |
|---|---|---|
| 高リソース言語 | DiversityやEntropyが比較的高い | 学習データ中の地域共起が豊富 |
| 低リソース言語 | OwnやNAが高くなりやすい | 安全な自己参照や未回答に寄る |
| 多国で使われる言語 | 分布が複数国へ広がる可能性 | 言語と国が一対一でない |
| 地域語・少数言語 | 特定地域に強く固定される可能性 | データ不足と国名共起の影響 |
これは多言語サービスにとって重要です。
同じプロンプトでも、言語を変えるだけで、モデルが想定する文化的背景が変わる可能性があるためです。
どの学習段階で偏りが強まるのか
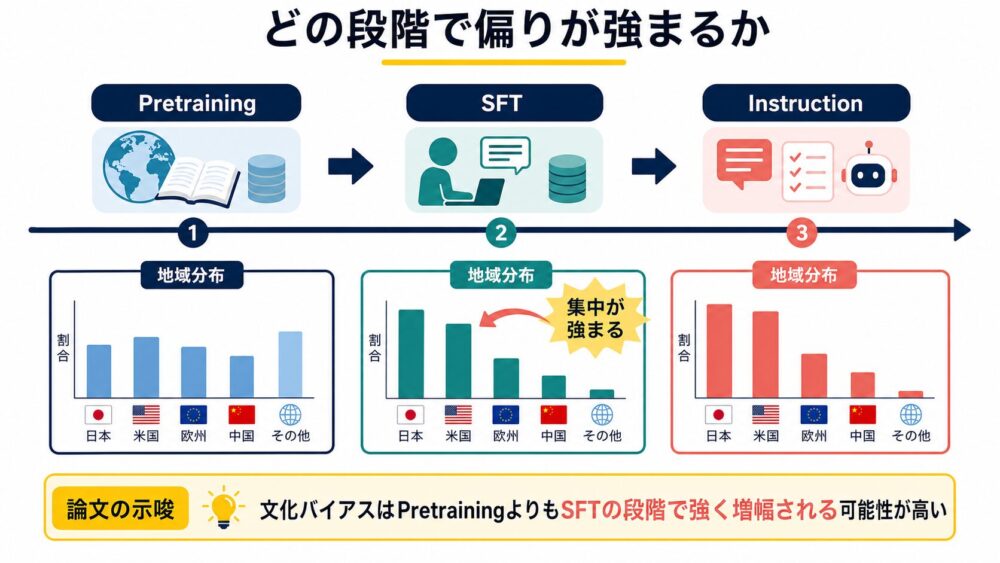
RQ3では、文化・地域バイアスが学習のどの段階で現れるのかを調べています。
論文では、Base model(事前学習後の基盤モデル)とInstruct model(指示追従用に調整されたモデル)を比較しています。
結果として、Base modelは地域参照が比較的広く分散する一方で、SFTやInstruction tuning(指示に従うように後段で調整する工程)の後に、特定地域への集中が強まりやすいことが示されています。
| 学習段階 | 役割 | 論文で示された傾向 |
|---|---|---|
| Pretraining | 大量テキストから言語・知識を学ぶ | 地域分布は比較的広い |
| SFT | 指示と模範回答で教師あり調整する | 偏りが明確に強まる可能性 |
| Instruction tuning / alignment | 望ましい応答形式へ整える | 偏りは緩和される場合もあるが残る |
ここから、文化バイアスは単に事前学習データだけで決まるのではなく、「どのような模範回答を好ましいと教えるか」にも影響される可能性が示唆されます。
実装者視点:CROQ型評価を自社AIサービスで使うなら
LLMアプリケーションを作る側から見ると、この研究はかなり実務的です。
文化や地域に関わる回答を出すサービスでは、プロンプト言語ごとに回答分布が変わる可能性があるためです。
たとえば、旅行、教育、医療情報、地域ニュース、商品推薦、キャラクター会話、多言語チャットボットなどでは、文化的な初期値がユーザー体験に影響します。
import logging
from collections import Counter
from typing import Iterable
logger = logging.getLogger(__name__)
def count_region_mentions(region_lists: Iterable[list[str]]) -> Counter[str]:
"""LLM回答から抽出済みの地域名リストを集計する。
Args:
region_lists: 1回答ごとに抽出された国・地域名のリスト。
Returns:
国・地域名をキー、出現回数を値にしたCounter。
Raises:
TypeError: region_listsの要素がlist[str]として扱えない場合。
Example:
>>> count_region_mentions([["Japan", "USA"], ["Japan"]])
Counter({'Japan': 2, 'USA': 1})
"""
counts: Counter[str] = Counter()
for regions in region_lists:
if not isinstance(regions, list):
logger.error("region_lists must contain list[str], got %s", type(regions).__name__)
raise TypeError("region_lists must contain list[str]")
for region in regions:
if not isinstance(region, str):
logger.error("region name must be str, got %s", type(region).__name__)
raise TypeError("region name must be str")
# 表記ゆれを別カウントにしないため、集計前に最低限の正規化を行う。
normalized = region.strip()
if normalized:
counts[normalized] += 1
logger.info("counted %d unique regions", len(counts))
return counts実務では、この集計だけでは不十分です。
地域名抽出モデルの誤り、多義的な地名、国と文化圏のズレ、ユーザーの意図、サービス上許容できる偏りの基準を別途設計する必要があります。
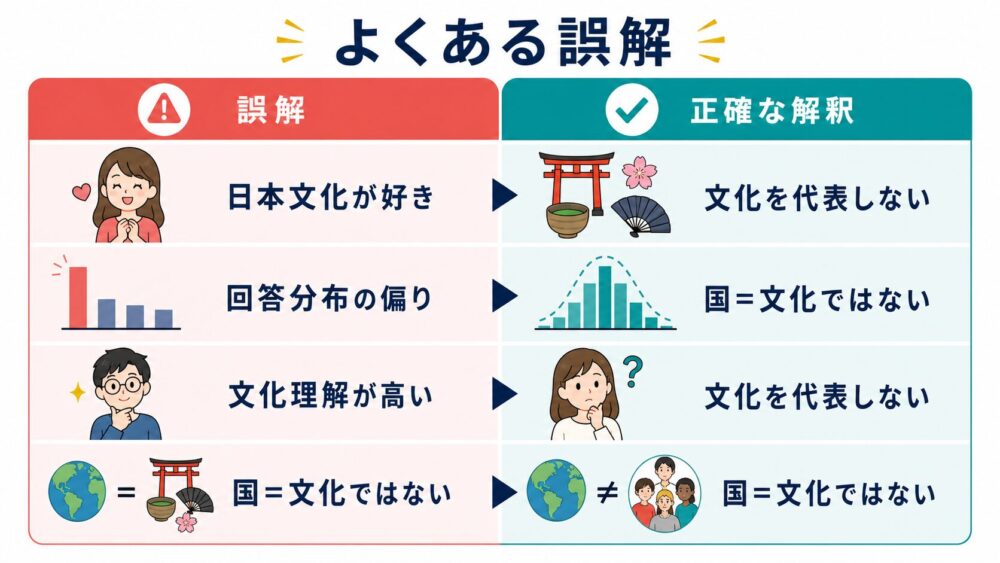
よくある誤解
| 誤解 | 正確な情報・解釈 |
|---|---|
| 「LLMは日本文化が好き」という意味 | 論文では、自由回答で日本が参照されやすい分布が観測されたという意味です。好みや意図を示すものではありません。 |
| 「日本文化の理解力が高い証拠」 | 参照回数が多いことと、理解の正確性は別です。誤ったステレオタイプを多く出す可能性もあります。 |
| 「国名が出れば文化を代表できる」 | 国と文化は一対一ではありません。同じ国内にも多様な文化があります。 |
| 「英語で評価すれば十分」 | 論文では、入力言語によって分布が変わることが示されています。多言語評価が必要です。 |
| 「事前学習データだけが原因」 | 論文では、SFT後に偏りが強まる可能性が示されています。後段の調整も重要です。 |
この論文の限界と注意点
| 注意点 | 内容 |
|---|---|
| LLM-as-a-judge依存 | 地域抽出にもモデルの誤りや偏りが入る可能性があります。 |
| 国単位の粗さ | 国名だけでは、民族、地域、宗教、階層、都市部・地方差を表しきれません。 |
| プロンプト依存 | 「短く答えて」「場所を選んで」などの指示が分布に影響する可能性があります。 |
| モデル版依存 | 2026年4月時点のモデルであり、今後の更新で変わる可能性があります。 |
| 文化理解の正確性ではない | 参照された国の文化を正しく説明できるかは別評価が必要です。 |
なぜ重要か:多言語AIサービスの品質に直結する
この論文が重要なのは、文化バイアスが「倫理的に大事」というだけでなく、実際のサービス品質に影響するからです。
たとえば、多言語の教育AIが、低リソース言語の質問に対して毎回その国だけを前提にすると、世界の多様な事例を学ぶ機会が狭まります。
旅行AIが、文化的な説明で特定国の有名事例ばかり出すと、ユーザーが求める地域性とずれる可能性があります。
また、医療・行政・金融のような高リスク領域では、地域前提の誤りがユーザーに不利益を与える可能性もあります。
このため、LLMを多言語・多文化環境で使う場合は、単に翻訳品質を見るだけでなく、回答がどの地域を暗黙に前提にしているかを検査することが重要です。
関連技術
| 関連技術 | 概要 | CROQとの違い |
|---|---|---|
| CulturalBench | 文化知識を問うベンチマーク | 正解ベースの評価が中心 |
| BLEnD | 日常的な文化知識を多国・多言語で評価 | 文化知識の差を見やすい |
| NormAd | 文化規範への適応を評価 | 規範判断寄り |
| LLM-as-a-judge | LLMで回答を評価・抽出する手法 | CROQでは地域抽出に利用 |
| Instruction tuning | 指示追従能力を高める後段学習 | 偏りを強める可能性が示唆された |
次に読むべき記事
| 記事案 | 読む理由 |
|---|---|
| LLM-as-a-judgeとは何か | この論文の地域抽出手法を理解しやすくなります。 |
| Instruction tuningとSFTの違い | 偏りがどの学習段階で強まるかを理解できます。 |
| 多言語LLMの低リソース言語問題 | 言語ごとの回答品質差を理解できます。 |
| 文化バイアス評価ベンチマーク比較 | CROQと既存研究の位置づけを整理できます。 |
まとめ
この論文は、LLMが文化に関する自由回答でどの国や地域を暗黙に選びやすいのかを、CROQという新しいデータセットで分析しています。
論文では、入力言語の公用国への強い偏りに加えて、外部参照では日本、米国、インドなどが目立つ傾向が示されています。
また、文化・地域バイアスは事前学習だけでなく、SFTやInstruction tuningといった後段の調整で強まり得ることも示唆されています。
多言語AIサービスを作るなら、「どの言語で聞いても同じ品質で答えるか」だけでなく、「どの文化や地域を暗黙に前提にしているか」を評価することが重要です。
コメント