 AI関連論文
AI関連論文 NPUはなぜDRAMアクセスを減らしやすいのか?PE ArrayとSystolic ArrayをGPUとの違いから理解する
NPUのPE Array、Systolic Array、On-chip SRAM、FIFO、Accumulator、dataflowを、行列積の積和とA/B/Cの移動から解説。GPUのtile再利用との違い、DRAMアクセスを減らしやすい理由、カメラAI・エッジAIへの応用まで整理します。
AI関連論文  AI関連論文
AI関連論文  AI関連論文
AI関連論文  AI関連論文
AI関連論文 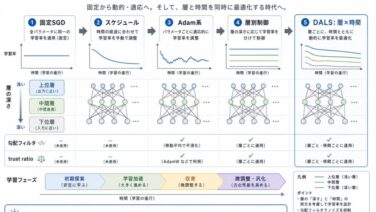 AI関連論文
AI関連論文  AI関連論文
AI関連論文 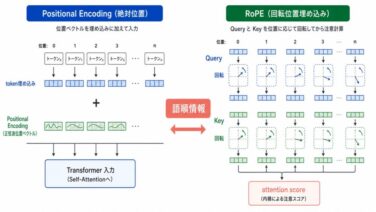 AI関連論文
AI関連論文 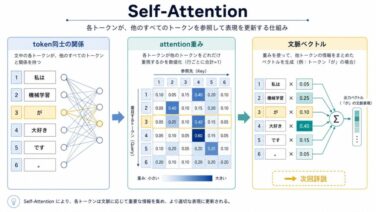 AI関連論文
AI関連論文 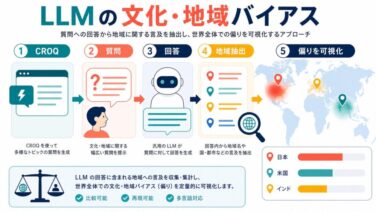 AI関連論文
AI関連論文 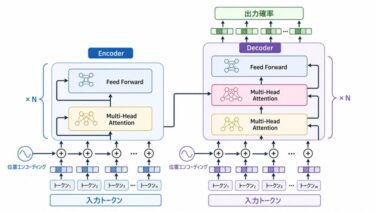 AI関連論文
AI関連論文