Transformerとは?Attention Is All You Need論文からLLMの基本構造を理解する
Transformerは、RNN(再帰的に文や翻訳前の英語のような「順番に並んだtoken列」を処理するニューラルネットワーク)やCNN(畳み込みで近くの単語や局所パターンを処理するニューラルネットワーク)を使わず、Attentionを中心に入力文から出力文への変換を行うアーキテクチャです。
3文要約
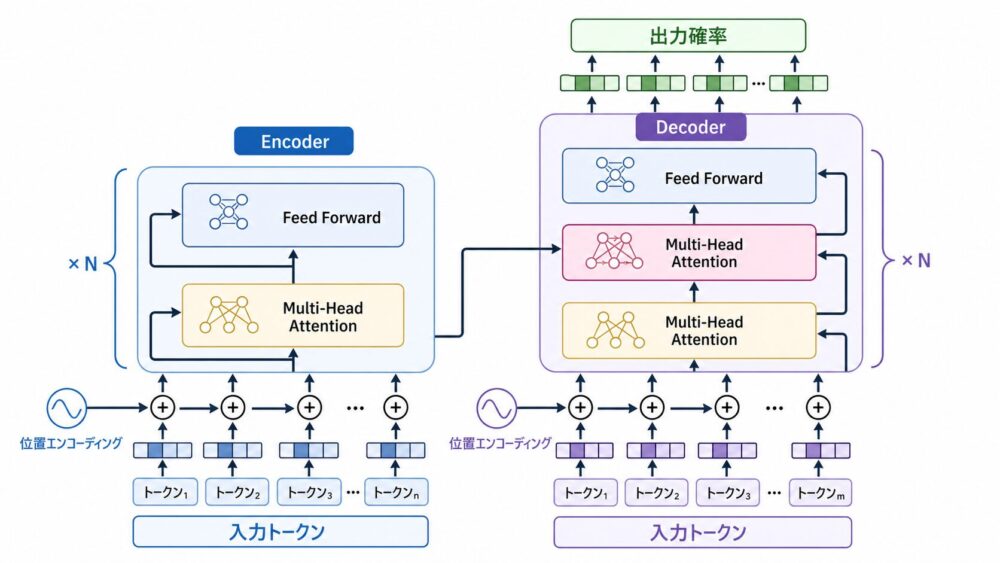
Transformerは、Self-Attention(同じ文の中にあるtoken同士が互いを参照する仕組み)によって、文中の離れた単語関係を短い計算経路で扱います。
Vaswaniらの論文では、再帰や畳み込みを使わず、Multi-Head Attention、Position-wise Feed-Forward Networks、Positional Encodingを組み合わせることで、機械翻訳で高い性能と学習効率を示しました。
現代のLLMはDecoder-onlyなど形を変えていますが、tokenを埋め込み、位置情報を加え、Attention層を重ねて文脈表現を作るという基本発想は、このTransformer論文を読むと理解しやすくなります。
論文情報
| 項目 | 内容 |
|---|---|
| 論文タイトル | Attention Is All You Need |
| 著者 | Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin |
| 初版公開日 | 2017年6月12日 |
| 最終改訂 | 2023年8月2日 v7 |
| 採択 | NeurIPS 2017 |
| 分野 | Computation and Language, Machine Learning |
| arXiv | Attention Is All You Need |
| DOI | 10.48550/arXiv.1706.03762 |
Transformerが登場した背景
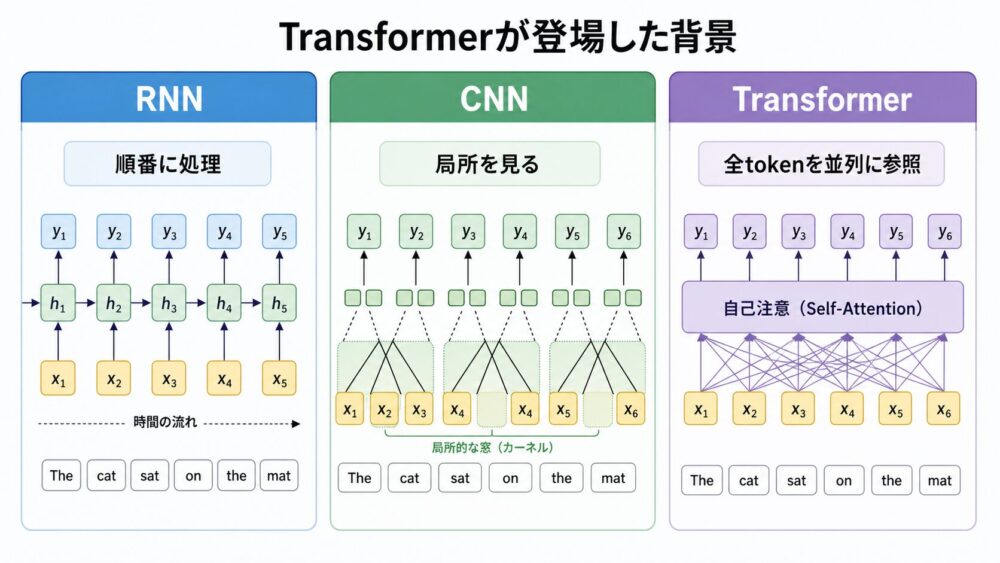
先ほどのAttention編では、Bahdanau Attentionを「Decoderが入力文のどこを見るか」を学ぶ仕組みとして整理しました。
Transformerは、そのAttentionを補助部品としてではなく、文や翻訳文のように順番に並んだtoken列を処理する中心に置いたモデルです。
ここでいうtoken列とは、文章を小さな単位に分けたものが左から右へ並んだデータです。
たとえば、翻訳前の英語文 I love machine learning は、I、love、machine、learning のようなtokenの並びとして扱えます。
当時のニューラル機械翻訳では、RNN Encoder-Decoderや、RNNにAttentionを追加した構成がよく使われていました。
RNNは、前のtokenの状態を次のtokenへ渡しながら、文を左から右へ順番に処理します。
CNNは、画像処理で有名な畳み込みを文章にも応用し、近くにある複数tokenの局所的なパターンを重ねて読むモデルです。
どちらも重要な系列モデルですが、長い文を扱うときには次のような違いが出ます。
| 観点 | RNNベースのモデル | CNNベースのモデル | Transformer |
|---|---|---|---|
| 文の処理 | tokenを順番に処理する | 近くのtokenのまとまりを見る | 層内では全tokenを並列に参照しやすい |
| 長距離依存 | 遠いtokenほど情報経路が長くなりやすい | 層を重ねる必要がある | Self-Attentionなら1層で直接参照できる |
| GPUとの相性 | 時間方向の逐次計算がボトルネックになりやすい | 比較的並列化しやすい | 行列積中心で並列化しやすい |
| 位置情報 | 順序処理に自然に含まれる | 畳み込み位置に含まれる | Positional Encodingで明示的に加える |
Transformer論文の大きな主張は、入力文から出力文への変換において「再帰も畳み込みも必須ではなく、Attentionだけでも十分に強いモデルを作れる」という点です。
ただし、「Attentionだけ」と言っても、Self-Attention単体ではありません。
実際のTransformerは、Multi-Head Attention、Feed Forward、残差接続、Layer Normalization、Positional Encodingなどを組み合わせたアーキテクチャです。
Transformerの全体像
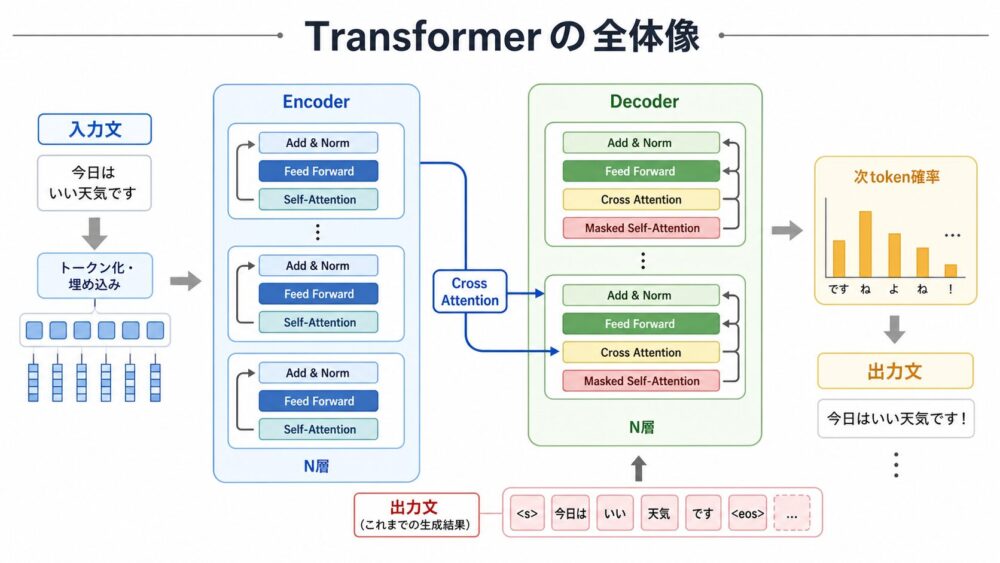
Transformerは、元論文ではEncoder-Decoder構造として提案されています。
入力文をEncoderが読み、Decoderが翻訳文を1 tokenずつ生成します。
構造を大きく分けると、次のようになります。
| 部品 | 役割 |
|---|---|
| Input Embedding | token IDをベクトルへ変換する |
| Positional Encoding | tokenの順序情報を埋め込みに加える |
| Encoder Self-Attention | 入力文中のtoken同士の関係を計算する |
| Decoder Masked Self-Attention | 未来tokenを見ないようにしながら出力側の文脈を計算する |
| Encoder-Decoder Attention | DecoderがEncoder出力を参照する |
| Feed Forward Network | 各位置ごとに非線形変換を行う |
| Linear + Softmax | 次tokenの確率分布を出す |
Encoder-Decoder構造
Encoder層は、Self-AttentionとFeed Forwardを積み重ねたブロックです。
Decoder層は、Masked Self-Attention、Encoder-Decoder Attention、Feed Forwardを積み重ねます。
論文ではEncoderとDecoderをそれぞれ6層重ね、隠れ次元を512、Attention head数を8にしたbaseモデルなどを評価しています。
EncoderとDecoderの違い
TransformerをLLMの文脈で読むとき、EncoderとDecoderの違いはかなり重要です。
元論文のTransformerは翻訳モデルなので、入力文を読むEncoderと、出力文を生成するDecoderがあります。
| 観点 | Encoder | Decoder |
|---|---|---|
| 入力 | 元の文 | これまでに生成した出力文 |
| Self-Attention | 全位置を互いに参照できる | 未来位置をmaskして見ない |
| Cross Attention | なし | Encoder出力を参照する |
| 主な用途 | 文理解、分類、双方向表現 | 生成、翻訳、次token予測 |
| 代表例 | BERT系 | GPT系、Decoder-only LLM |
GPT系LLMは、TransformerのDecoder側からCross Attentionを除いたようなDecoder-only構造を基本にしています。
そのため、Transformer論文のDecoderを読むと、次token予測を行う現代LLMの基礎が見えやすくなります。
Transformerの主要技術
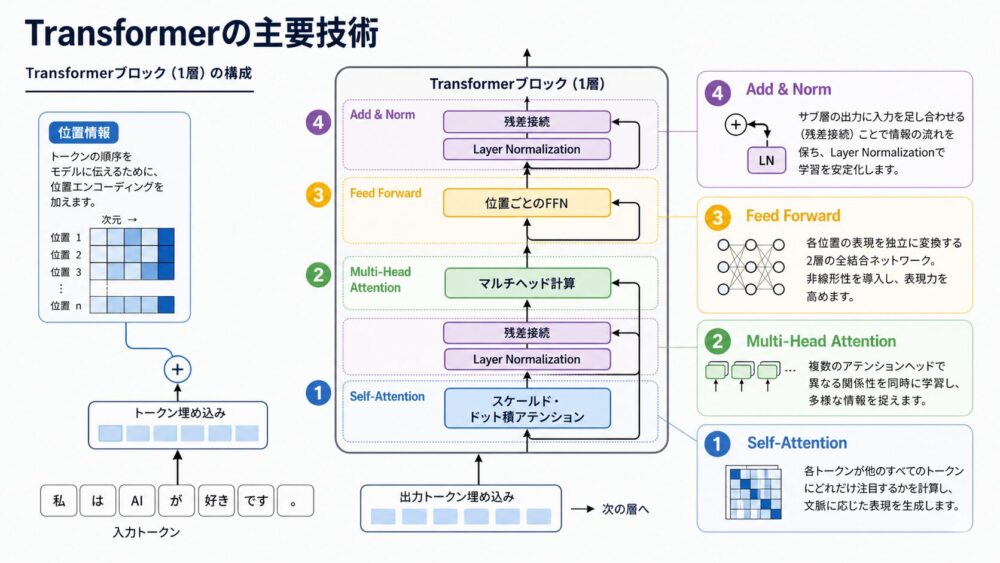
Transformerは「Attention Is All You Need」というタイトルで有名ですが、実際には複数の部品が組み合わさって動きます。
ここでは、本記事の理解に必要な粒度で主要技術を整理します。
Self-AttentionとPositional Encodingは、このLLMシリーズで後続記事として詳しく扱う予定です。
Self-Attentionとは何か
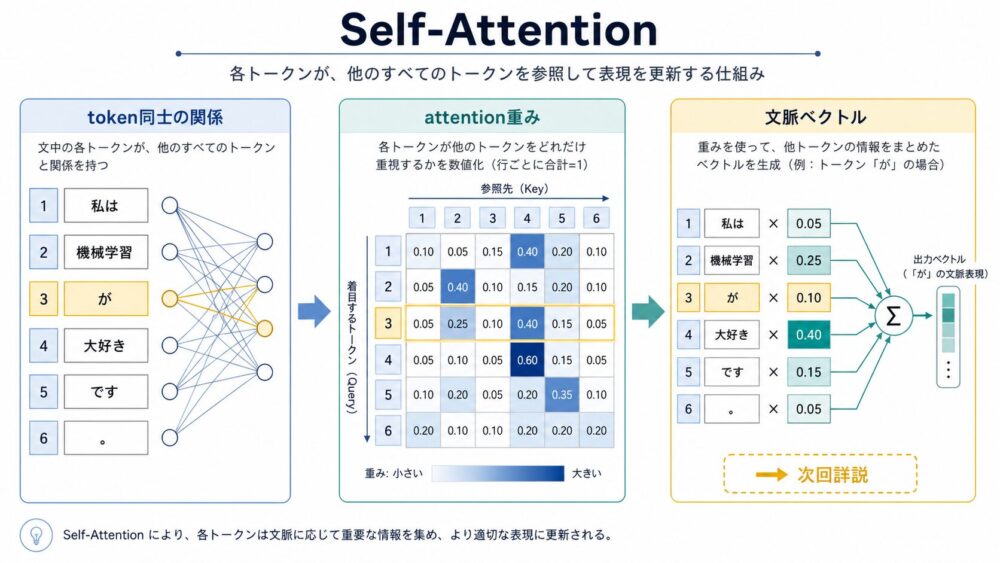
Self-Attentionは、同じ文の中にある各tokenが、他のtokenをどれくらい参照するかを計算する仕組みです。
たとえば「私は機械学習が大好きです。」という文なら、「大好き」は「私」や「機械学習」と強く関係します。
Self-Attentionでは、この関係をtoken間の重みとして学習します。
Transformer論文で使われる基本形は、Scaled Dot-Product Attentionです。
\[
\mathrm{Attention}(Q, K, V) =
\mathrm{softmax}\left(
\frac{QK^{\mathrm{T}}}{\sqrt{d_k}}
\right)V
\]
ここで、$Q$、$K$、$V$ はそれぞれQuery、Key、Valueです。
| 記号 | 直感的な役割 |
|---|---|
| Query | 今のtokenが「何を探しているか」 |
| Key | 各tokenが「どんな手がかりを持つか」 |
| Value | 実際に取り出して混ぜる情報 |
| $d_k$ | Keyの次元数 |
$QK^T$ は、QueryとKeyの相性スコアです。
具体例で考えます。
「私は機械学習が大好きです。」という文で、いま 大好き というtokenの表現を更新したいとします。
このとき、大好き から作られるQueryは「このtokenは、文中のどの情報を探すべきか」を表します。
Keyは、私、は、機械学習、が、大好き、です など、各tokenからそれぞれ作られます。
Keyは「各tokenが、照合されるために持っている手がかり」です。
Queryが各Keyと内積を取り、私 や 機械学習 周辺のKeyと相性が高ければ、それらのtokenに大きなattention weightが付きます。
Valueも、Keyと同じく各tokenからそれぞれ作られます。
ここでいうValueは、各tokenのベクトル表現を、Value用の重み行列で変換したものです。
たとえば 機械学習 のValueには、「機械学習」というtokenが持つ意味的な情報がベクトルとして入っています。
Attentionは、QueryとKeyで「どのtokenをどれくらい参照するか」を決め、その重みに応じて各tokenのValueを足し合わせます。
そのため、大好き の出力表現は、私、機械学習、大好き など各tokenのValueを、attention weightで重み付き和したものになります。
| 役割 | 大好き を更新する例 |
|---|---|
| Query | 大好き から作る。「何を参照したいか」を表す |
| Key | 私、は、機械学習、が、大好き、です から作る。Queryと照合される手がかり |
| Value | 各tokenのベクトル表現から作る。重みに応じて実際に混ぜる中身 |
このスコアを $\sqrt{d_k}$ で割るのは、次元数が大きいと内積値が大きくなり、softmaxの勾配が小さくなりやすいためです。
本記事ではTransformer全体像を優先するため、Self-Attentionの詳細な数式展開、mask、実装上の注意点は次回の「Self-Attentionとは?」の記事で詳しく整理します。
Multi-Head Attentionが必要な理由
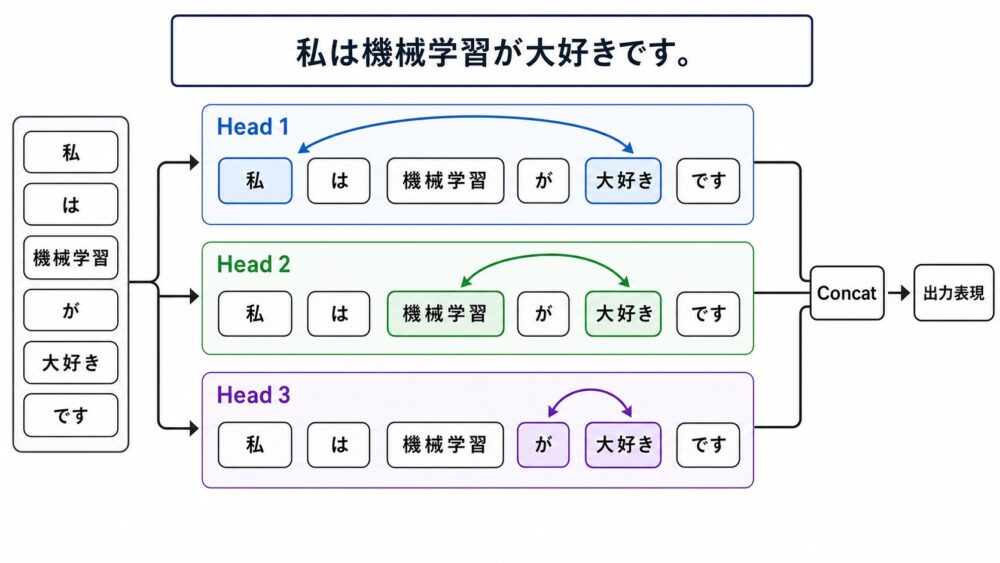
Transformerは、1つのAttentionだけではなく、複数のAttention headを並列に使います。
これがMulti-Head Attentionです。
\[
\mathrm{MultiHead}(Q, K, V) = \mathrm{Concat}(\mathrm{head}_1, \ldots, \mathrm{head}_h)W^O
\]
\[
\mathrm{head}_i = \mathrm{Attention}(QW_i^Q, KW_i^K, VW_i^V)
\]
複数headを使うことで、モデルは異なる種類の関係を同時に見られます。
headは、Q/K/Vを作るための別々の投影セットと、それを使ったAttention計算の1単位です。
畳み込み(Convolution)でいうフィルタの種類に少し似ていて、同じ入力を複数の見方で処理するための部品です。
ただし、畳み込みのフィルタが近くの要素を局所的に見るのに対して、Attention headは文中の離れたtokenも直接参照できます。
たとえば 私 は 機械学習 が 大好き です という文がある場合、私、は、機械学習 など各tokenは、head 1にもhead 2にもhead 3にも入力されます。
head 1が 私 と 大好き の関係を見やすい表現を作り、head 2が 機械学習 と 大好き の意味的関係を見やすい表現を作り、head 3が近い単語の局所的な関係を見る、といった分担が起こり得ます。
| headで見たい関係の例 | 説明 |
|---|---|
| 近い単語関係 | 直前・直後の語との局所的なつながり |
| 主語と述語 | 離れた位置にある構文的な関係 |
| 代名詞の参照 | 「それ」「彼」が何を指すか |
| 翻訳上の対応 | 入力文と出力文の意味的な対応 |
論文のbaseモデルでは $h=8$、$d_\mathrm{model}=512$、各headの次元は64です。
ここで $h=8$ は、8個のAttention headを並列に計算するという意味です。
すべてのtokenについて8種類のQ/K/V投影を作り、8通りのAttention結果を計算します。
$d_\mathrm{model}=512$ は、各tokenを512次元のベクトルとして表すという意味です。
最初の512次元ベクトルはInput Embeddingで作られ、そこにPositional Encodingを加えたものがTransformer層へ入力されます。
各層を通った後も、tokenごとの表現は基本的に $d_\mathrm{model}$ 次元のまま保たれます。
Multi-Head Attentionでは、この512次元を8個のheadに分け、各headが64次元の空間でAttentionを計算します。
\[
512 / 8 = 64
\]
単一の大きなAttentionを使うのではなく、低次元のAttentionを複数走らせて結合する設計になっています。
Multi-Head Attentionは、次回のSelf-Attention記事でもScaled Dot-Product Attentionとの関係としてもう一度扱います。
Positional Encodingで順序を伝える
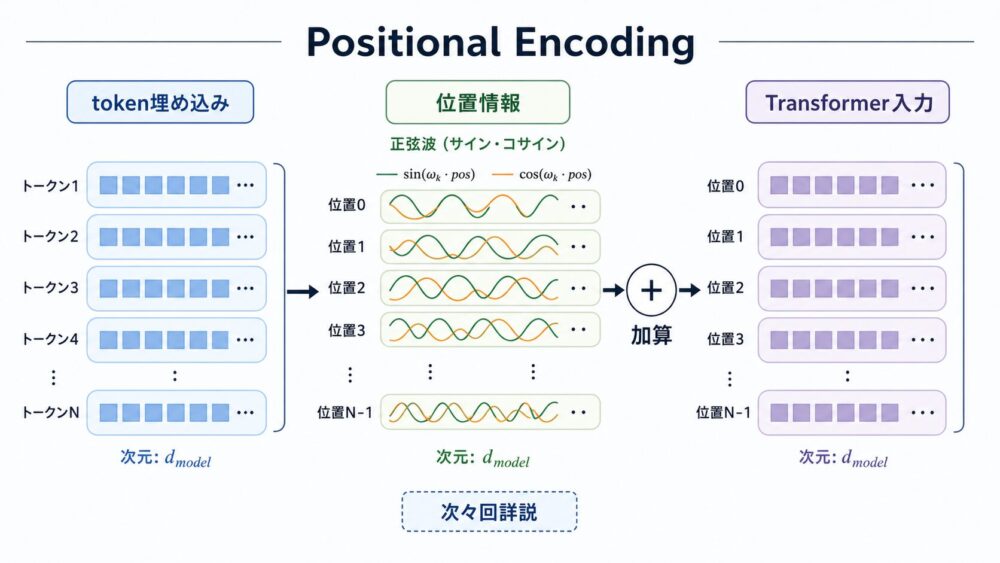
RNNはtokenを順番に処理するため、文中の順序が計算に自然に入ります。
一方、Self-Attentionは集合のように全tokenを見ます。
そのままだと、tokenの順番を区別できません。
そこでTransformerでは、入力埋め込みにPositional Encoding(位置情報を表すベクトル)を加えます。
論文では、sinとcosを使った固定の位置エンコーディングを使っています。
\[
PE_{(pos, 2i)} = \sin\left(pos / 10000^{2i / d_\mathrm{model}}\right)
\]
\[
PE_{(pos, 2i+1)} = \cos\left(pos / 10000^{2i / d_\mathrm{model}}\right)
\]
$pos$ はtoken位置、$i$ は次元のインデックスです。
この設計により、各位置は異なる波長のsin/cosの組み合わせとして表されます。
後のLLMではRoPE(Rotary Position Embedding、相対位置を回転で表す位置埋め込み)など別の方法もよく使われます。
位置情報の扱いは、Self-Attention記事の次に予定している「Positional Encoding / RoPE」編で詳しく扱います。
Feed Forward Networkの役割
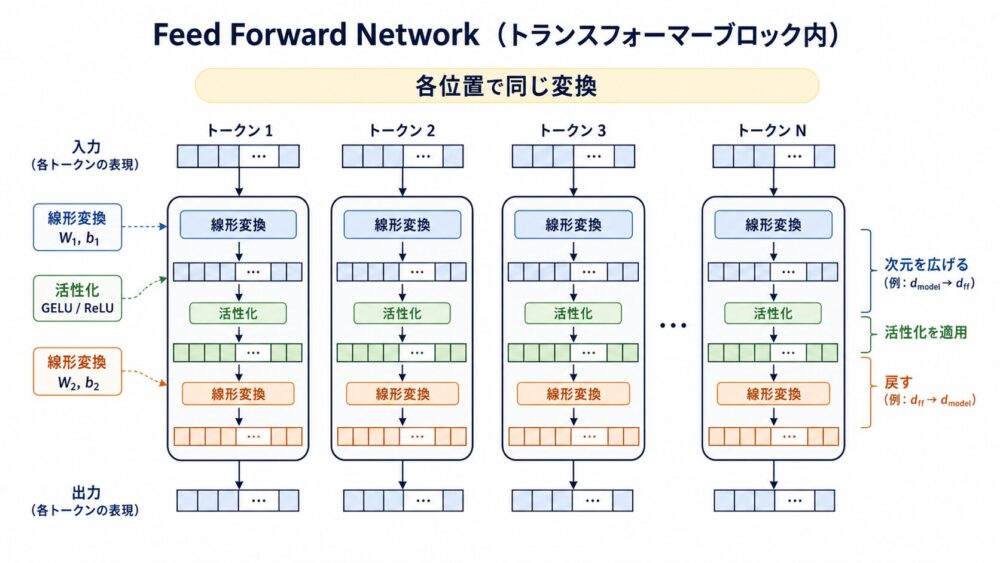
Transformerの各層には、Attentionの後にFeed Forward Networkがあります。
論文では、Position-wise Feed-Forward Networksと呼ばれています。
\[
\mathrm{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2
\]
上記式は畳み込みの式にも似ていますが、ここでの線形変換は畳み込みではありません。
各tokenのベクトル $x$ に重み行列 $W$ を掛け、バイアス $b$ を足して、別の特徴空間へ写す処理です。
\[
x’ = xW + b
\]
畳み込みは、近くのtokenや画素をまとめて見る局所的な演算です。
一方、TransformerのFeed Forwardは、各token位置を独立に処理します。
つまり、私 のtoken表現には同じFFNを適用し、大好き のtoken表現にも同じFFNを適用しますが、このFFN自体はtoken同士を混ぜません。
Attentionはtoken同士の関係を混ぜる役割を持ちます。
一方、Feed Forwardは、混ぜた後の各token表現を個別に変換し、より表現力のある特徴へ写像します。
2回線形変換する理由は、一度中間次元へ広げてから、元の次元へ戻すためです。
論文のbaseモデルでは、$d_\mathrm{model}=512$ のtoken表現を、内部では $d_\mathrm{ff}=2048$ へ広げ、ReLU(負の値を0にする非線形関数)を通してから512次元へ戻します。
非線形変換を挟むことで、単なる1回の行列変換では表せない複雑な特徴を作れます。
もし線形変換だけを何回重ねても、全体としては1つの大きな線形変換と同じ表現力に近くなります。
ReLUのような非線形関数を入れることで、「この特徴が強いときだけ別の特徴を強める」といった条件付きの表現が作りやすくなります。
メリットは、Attentionで集めた文脈情報を、各tokenごとにより豊かな特徴へ加工できることです。
| 観点 | Attention | Feed Forward |
|---|---|---|
| 主な役割 | token間の情報を混ぜる | 各token表現を非線形変換する |
| 処理範囲 | 複数tokenの関係 | 位置ごとに独立 |
| 直感 | どのtokenを見るか | 見た情報をどう加工するか |
残差接続の役割
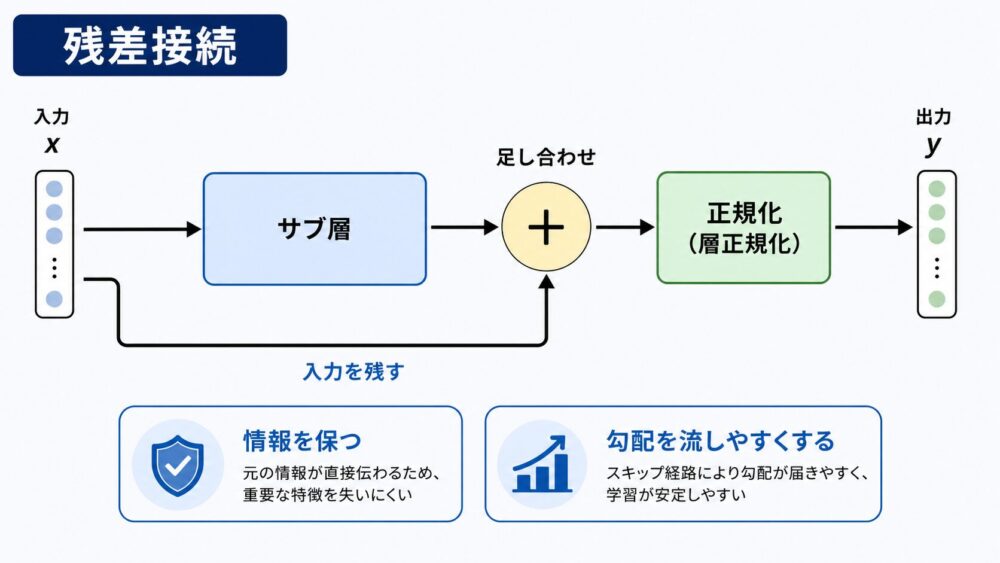
残差接続は、ある層の入力をそのまま残し、サブ層の出力に足し合わせる仕組みです。
Transformer論文では、各サブ層の周りに残差接続を置いています。
残差接続を広く普及させた代表的な元論文は、ResNetの Deep Residual Learning for Image Recognition です。
MobileNetは軽量CNNとして重要な系列ですが、残差接続そのものの代表的な出発点としてはResNetを参照するのが自然です。
\[
\mathrm{output} = \mathrm{LayerNorm}(x + \mathrm{Sublayer}(x))
\]
この設計により、層を深くしても元の情報が流れやすくなります。
また、勾配(学習時に重みを更新するための信号)も伝わりやすくなるため、深いニューラルネットワークを学習しやすくします。
Transformerを「Attentionの積み重ね」とだけ見ると、この残差経路を見落としがちです。
実際には、AttentionやFeed Forwardの変換を加えつつ、元の表現も保つことが安定した学習に重要です。
Layer Normalizationの役割
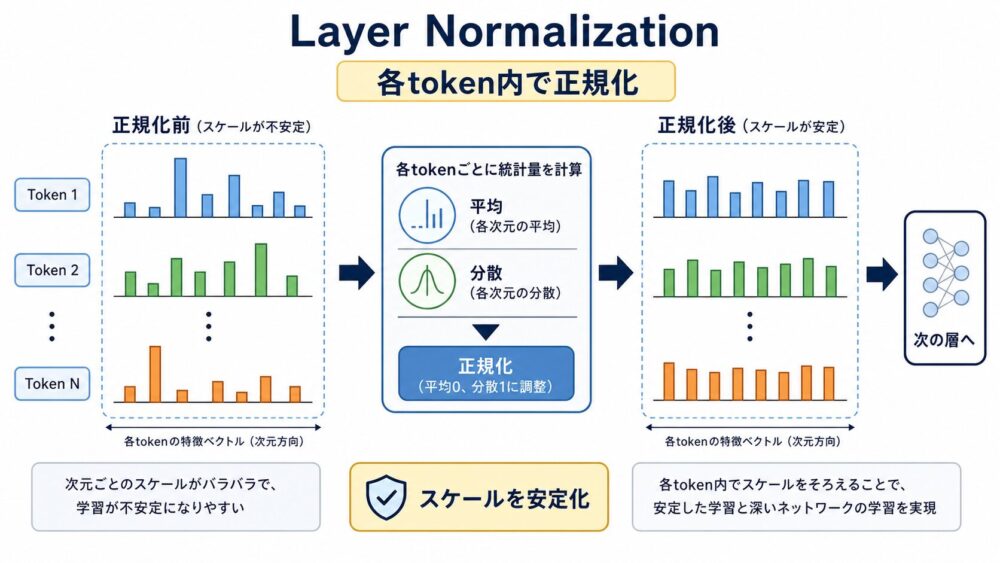
Layer Normalizationは、各token表現の特徴次元を正規化し、値のスケールを安定させる仕組みです。
正規化とは、値の平均や分散をそろえて、学習しやすい範囲に調整する処理です。
Transformer論文では、各サブ層の出力にLayer Normalizationを適用します。
\[
\mathrm{LayerNorm}(x) = \gamma \frac{x – \mu}{\sqrt{\sigma^2 + \epsilon}} + \beta
\]
$\mu$ は平均、$\sigma^2$ は分散、$\gamma$ と $\beta$ は学習されるスケールとバイアスです。
Layer Normalizationがあることで、層を重ねたときの値のばらつきが抑えられます。
現代のLLMではPre-LN(正規化をサブ層の前に置く構成)などの改良も多く使われますが、まずは「深いTransformerを安定して学習させるための部品」と理解するとよいです。
実験結果をどう読むか
論文では、WMT 2014 English-GermanとEnglish-Frenchの翻訳タスクで評価しています。
代表的な結果は次の通りです。
| モデル | EN-DE BLEU | EN-FR BLEU | 特徴 |
|---|---|---|---|
| ByteNet | 23.75 | – | 畳み込み系の文変換モデル |
| Deep-Att + PosUnk | – | 39.2 | 当時の強い翻訳モデル |
| Transformer base | 27.3 | 38.1 | 既存モデルより少ない学習コストで高性能 |
| Transformer big | 28.4 | 41.8 | EN-DEで当時のstate-of-the-art相当 |
Transformer bigは、WMT 2014 English-to-Germanで28.4 BLEUを報告しています。
English-to-Frenchでは41.8 BLEUを報告し、既存の強いモデルを上回ったとされています。
ただし、この結果は当時の機械翻訳タスクでの比較です。
現代LLMの対話性能や推論能力を、このBLEU値だけで説明することはできません。
重要なのは、Transformerが「高い翻訳性能」と「並列計算しやすい学習構造」を同時に示した点です。
RNN・CNN・Transformerの比較
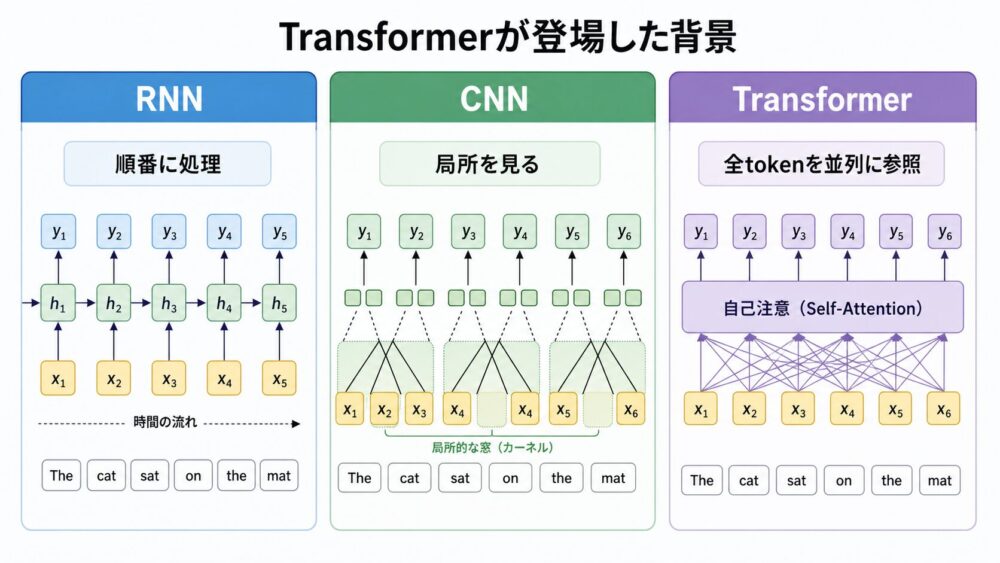
論文では、Self-Attention、Recurrent、Convolutionalの3種類を比較しています。
RNN(Recurrent Neural Network)は、前の時刻の状態を次の時刻へ渡しながら処理するニューラルネットワークです。
文章では、左から右へtokenを読み、過去の情報を隠れ状態として持ち運ぶイメージです。
CNN(Convolutional Neural Network)は、一定幅の窓で近くの要素をまとめて見るニューラルネットワークです。
文章では、近くにある単語の組み合わせや局所パターンを捉えやすい一方、遠い単語の関係を見るには層を重ねる必要があります。
ここでは、LLMを理解するために要点を整理します。
| 観点 | RNN | CNN | Transformer Self-Attention |
|---|---|---|---|
| 並列化 | 時間方向に弱い | 比較的しやすい | かなりしやすい |
| 長距離依存の経路長 | 長くなりやすい | 層数に依存 | 1層で直接参照できる |
| 局所性 | 順序に強い | 局所パターンに強い | 全token関係を直接扱える |
| 計算量の注意点 | 逐次処理が重い | カーネル幅に依存 | token数に対してAttentionが重くなる |
Transformerは万能ではありません。
Self-Attentionは全tokenペアを比較するため、単純な実装ではtoken数 $n$ に対して $O(n^2)$ の計算・メモリが必要です。
この課題は、後のFlashAttention、Sparse Attention、KV Cache、GQAなどの研究につながっていきます。
実装イメージ:Scaled Dot-Product Attention
以下は、Transformer論文のScaled Dot-Product Attentionを最小構成で実装した例です。
実務ではPyTorchの torch.nn.functional.scaled_dot_product_attention などを使う場面が増えていますが、数式とtensor形状の対応を理解するには手書き実装が役立ちます。
import logging
from typing import Optional
import torch
from torch import Tensor
logger = logging.getLogger(__name__)
def scaled_dot_product_attention(
query: Tensor,
key: Tensor,
value: Tensor,
attention_mask: Optional[Tensor] = None,
) -> Tensor:
"""Compute scaled dot-product attention.
Args:
query: Query tensor with shape `(batch, heads, query_length, head_dim)`.
key: Key tensor with shape `(batch, heads, key_length, head_dim)`.
value: Value tensor with shape `(batch, heads, key_length, head_dim)`.
attention_mask: Optional boolean mask broadcastable to
`(batch, heads, query_length, key_length)`. `True` means visible.
Returns:
Tensor with shape `(batch, heads, query_length, head_dim)`.
Raises:
ValueError: If `key` and `value` have different sequence lengths.
Example:
>>> q = torch.randn(2, 8, 4, 64)
>>> k = torch.randn(2, 8, 4, 64)
>>> v = torch.randn(2, 8, 4, 64)
>>> out = scaled_dot_product_attention(q, k, v)
>>> out.shape
torch.Size([2, 8, 4, 64])
"""
if key.size(-2) != value.size(-2):
logger.error("key_length and value_length must match")
raise ValueError("key and value must have the same sequence length")
head_dim: int = query.size(-1)
scores: Tensor = query @ key.transpose(-2, -1)
scores = scores / (head_dim**0.5)
if attention_mask is not None:
logger.debug("applying attention mask before softmax")
scores = scores.masked_fill(~attention_mask, torch.finfo(scores.dtype).min)
weights: Tensor = torch.softmax(scores, dim=-1)
logger.debug("computed attention weights", extra={"shape": tuple(weights.shape)})
return weights @ valuemaskをsoftmaxの前に入れる理由は、見てはいけない位置の確率をほぼ0にするためです。
Decoderの自己回帰生成では、未来tokenを見ないcausal maskが必要になります。
TransformerがLLM理解で重要な理由
Transformerは、現在のLLMのほぼすべてを直接説明するわけではありません。
たとえば、現代のLLMでは次のような違いがあります。
| 項目 | Transformer論文 | 現代の代表的LLM |
|---|---|---|
| 主目的 | 機械翻訳 | 次token予測、指示応答、対話 |
| 構造 | Encoder-Decoder | Decoder-onlyが多い |
| 位置情報 | sinusoidal positional encoding | RoPEなどが多い |
| 正規化 | Post-LN構成 | Pre-LN系がよく使われる |
| Attention | Multi-Head Attention | MHA、MQA、GQAなどに発展 |
それでもTransformer論文は、LLMの基礎として非常に重要です。
理由は、LLMの中核計算である「tokenをベクトル化し、位置を加え、Attentionで文脈を混ぜ、Feed Forwardで変換する」という流れが、この論文で明確に定式化されているからです。
よくある誤解
| 誤解 | 正確な見方 |
|---|---|
| TransformerはAttentionだけでできている | Attentionが中心だが、Feed Forward、残差接続、正規化、位置情報も重要 |
| Attention weightを見ればモデルの理由が完全に分かる | 参照傾向は見えるが、因果的な説明としては慎重に読む必要がある |
| TransformerはRNNの完全上位互換 | 並列性と長距離依存に強い一方、長文では $O(n^2)$ の課題がある |
| GPTは元論文のTransformerそのもの | GPT系は主にDecoder-only構造で、元論文の翻訳用Encoder-Decoderとは異なる |
| Positional Encodingは細部なので無視してよい | Attentionだけでは順序を区別しにくいため、位置情報は本質的に重要 |
まとめ
Transformerは、Attentionを文処理の中心に置き、RNNやCNNに頼らず機械翻訳を行うモデルとして提案されました。
Self-Attentionにより、各tokenは他のtokenを直接参照できます。
Multi-Head Attentionにより、複数種類の関係を並列に扱えます。
Feed Forward、残差接続、Layer Normalizationにより、Attentionで混ぜた情報を変換し、深い層を安定して学習できます。
Positional Encodingにより、Attentionだけでは失われやすい順序情報を補います。
現代LLMは、Transformer論文から多くの改良を経ています。
それでも、LLMを理解する最初の大きな山として、この論文は今でも読む価値があります。
関連技術
| 技術 | Transformerとの関係 |
|---|---|
| Bahdanau Attention | Attentionを翻訳Decoderに導入した重要な先行研究 |
| Self-Attention | Transformerの中心計算。次回の記事で詳しく扱う |
| Multi-Head Attention | 複数のAttention headで異なる関係を見る仕組み。次回記事でも補足する |
| Positional Encoding | token順序をモデルに伝える仕組み。次々回の記事で詳しく扱う |
| Decoder-only Transformer | GPT系LLMの基本構造 |
| KV Cache | Decoder推論でKey/Valueを再利用して高速化する仕組み |
| FlashAttention | Attention計算のメモリアクセスを最適化する手法 |
次に読むべき記事
- Self-Attentionとは?Scaled Dot-Product Attentionを数式から理解する
- LLMは語順をどう理解する?Positional EncodingとRoPEの基礎
- GPT系LLMの構造とは?Decoder-only Transformerをやさしく解説
- KV Cacheとは?LLMの生成を高速化する仕組み
コメント