 自分が読んだAI関連の論文について、日本語解説していきます。
自分が読んだAI関連の論文について、日本語解説していきます。
特に、AI(LLM, Diffusionモデルなど)を用いた画像処理(Denoiseや画像再構成、超解像などについての技術論文と
上記技術をエッジデバイスなどに搭載するために必要な縮小・軽量化(Quantization, LoRAなど)がメインになります。
自分が読んだAI関連の論文について、日本語解説していきます。
特に、AI(LLM, Diffusionモデルなど)を用いた画像処理(Denoiseや画像再構成、超解像などについての技術論文と
上記技術をエッジデバイスなどに搭載するために必要な縮小・軽量化(Quantization, LoRAなど)がメインになります。
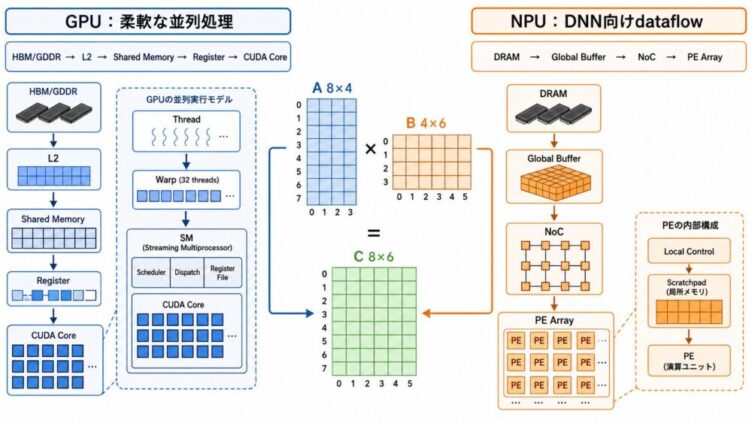 AI関連論文
AI関連論文 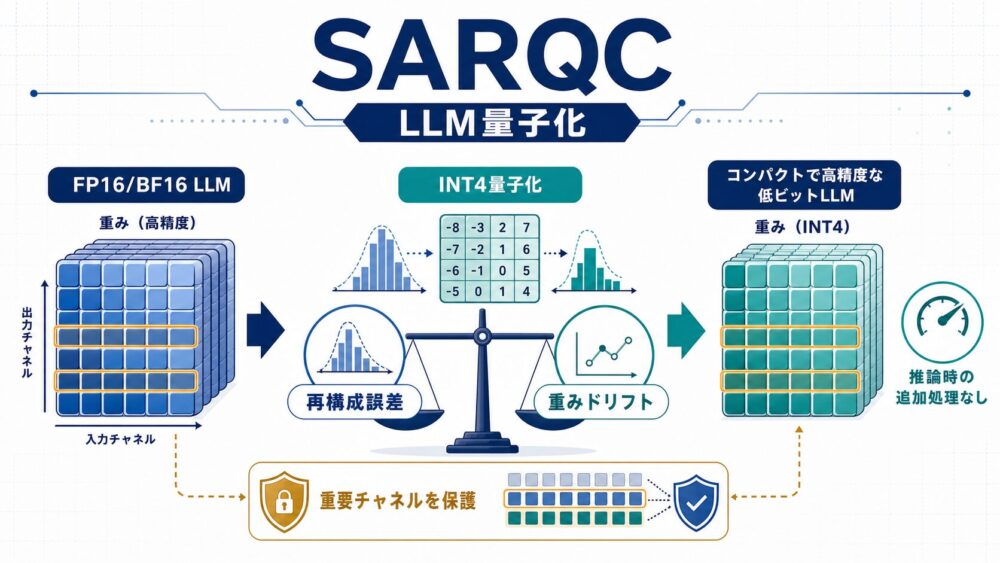 AI関連論文
AI関連論文 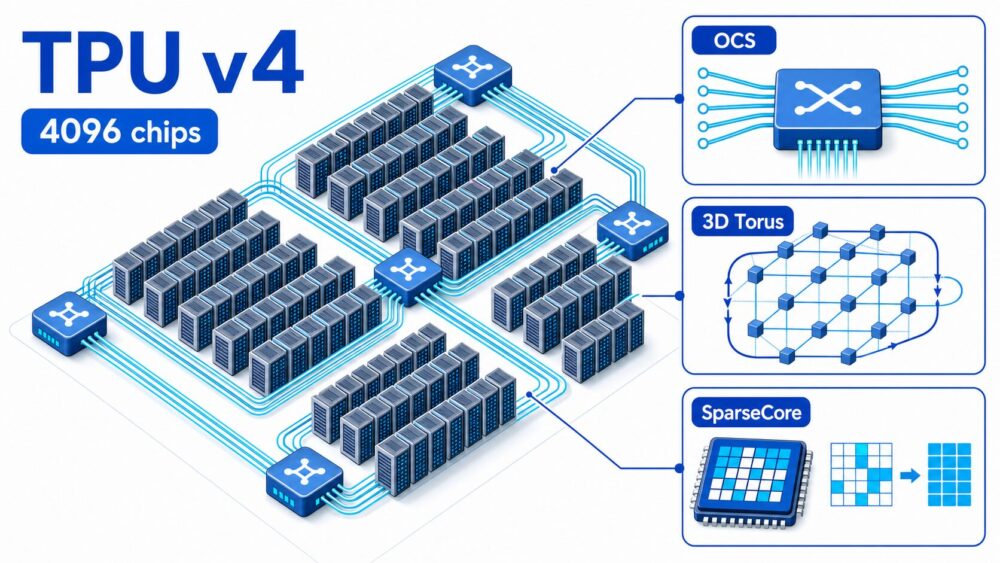 AI関連論文
AI関連論文 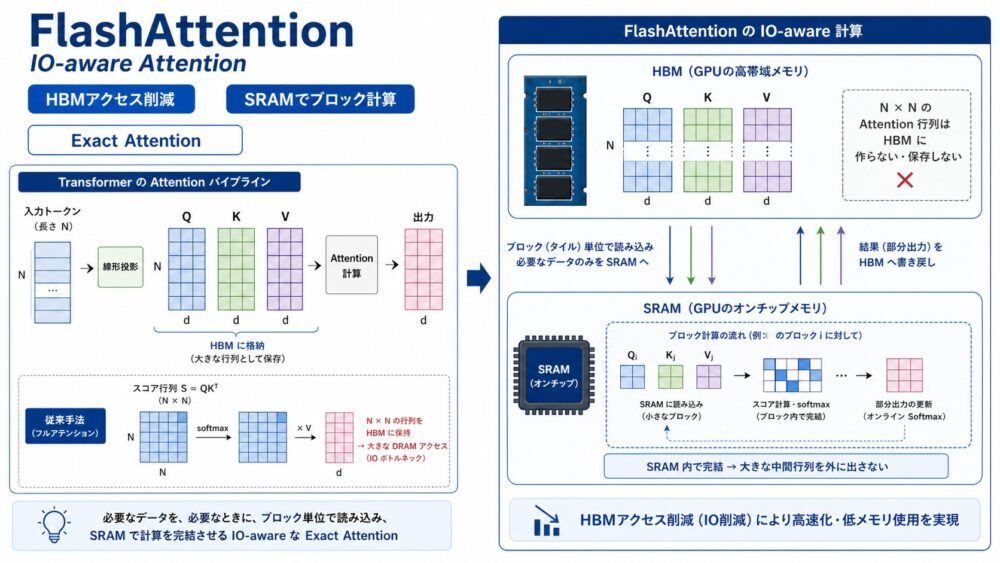 AI関連論文
AI関連論文 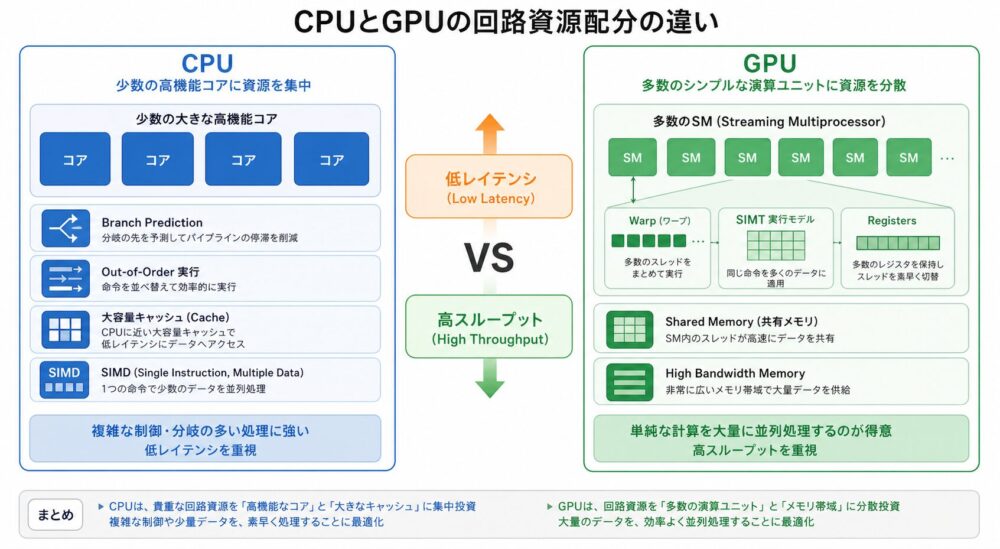 AI関連論文
AI関連論文 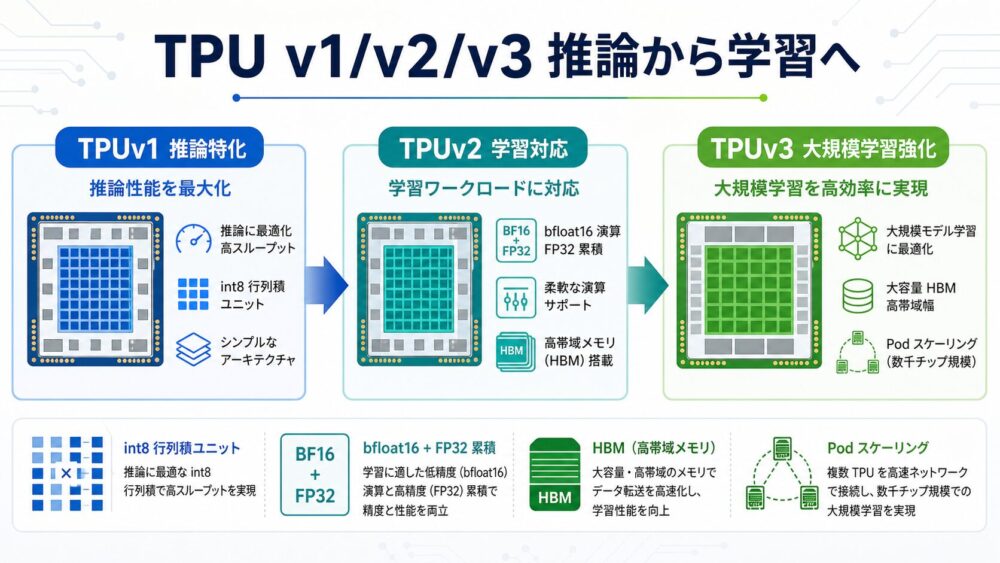 AI関連論文
AI関連論文 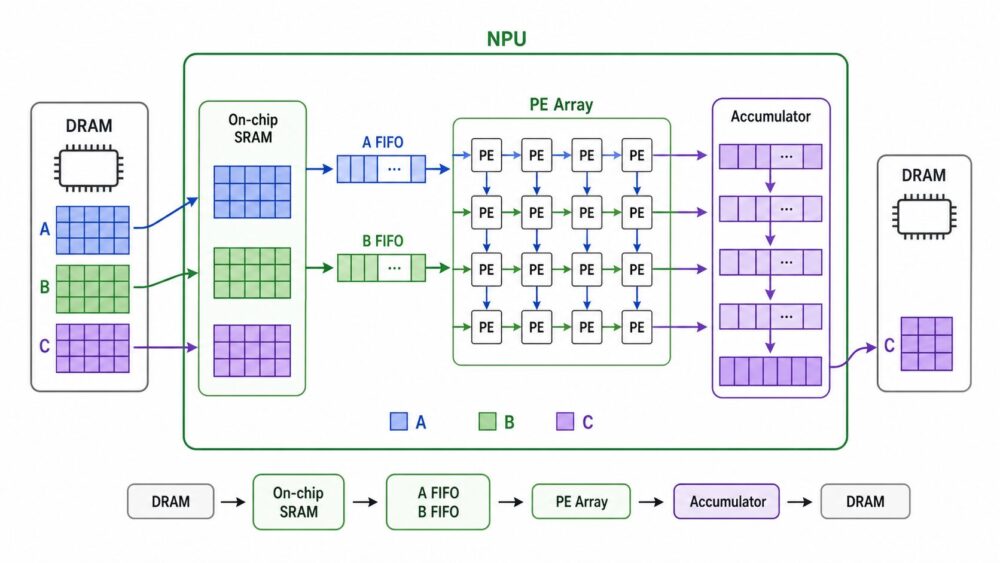 AI関連論文
AI関連論文 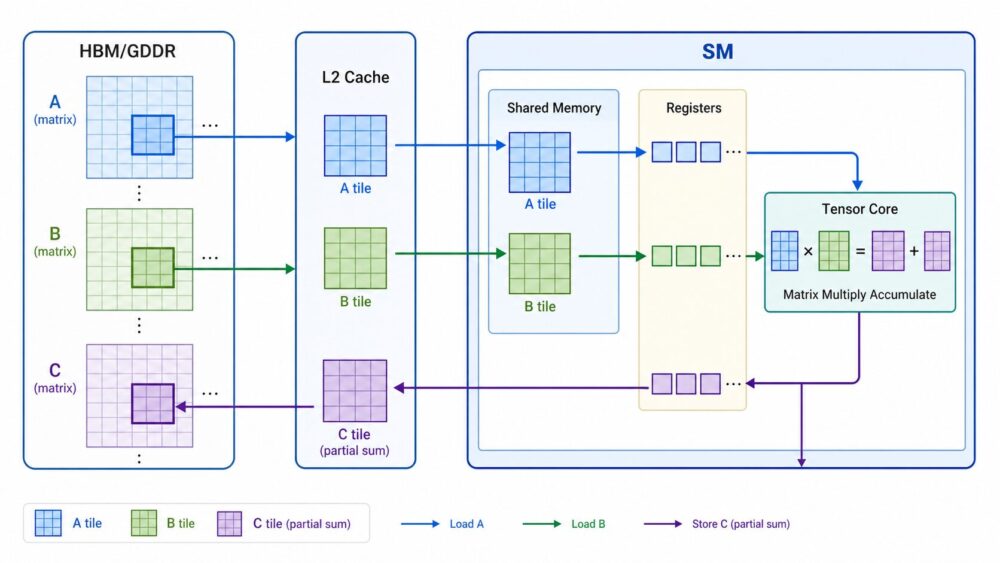 AI関連論文
AI関連論文 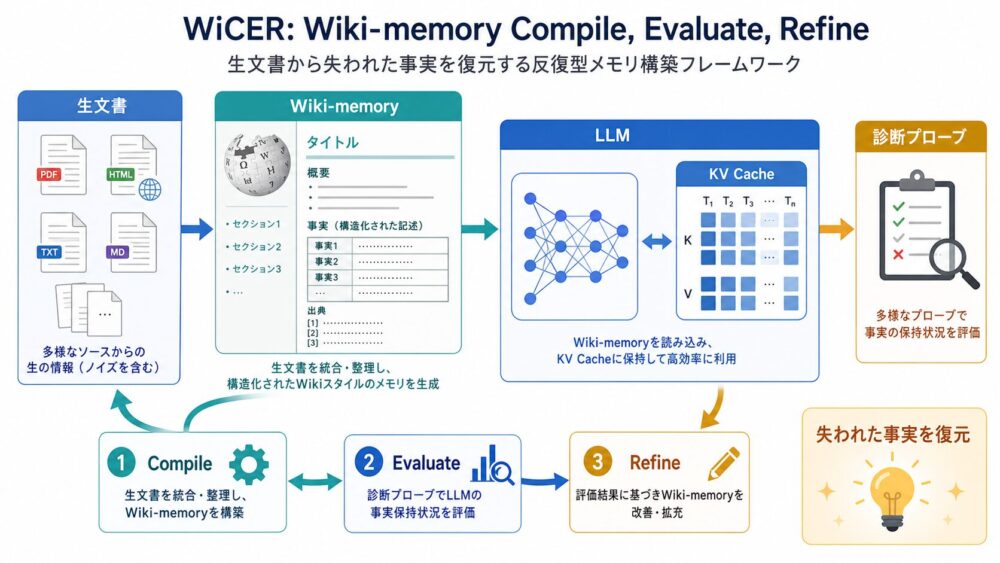 AI関連論文
AI関連論文