
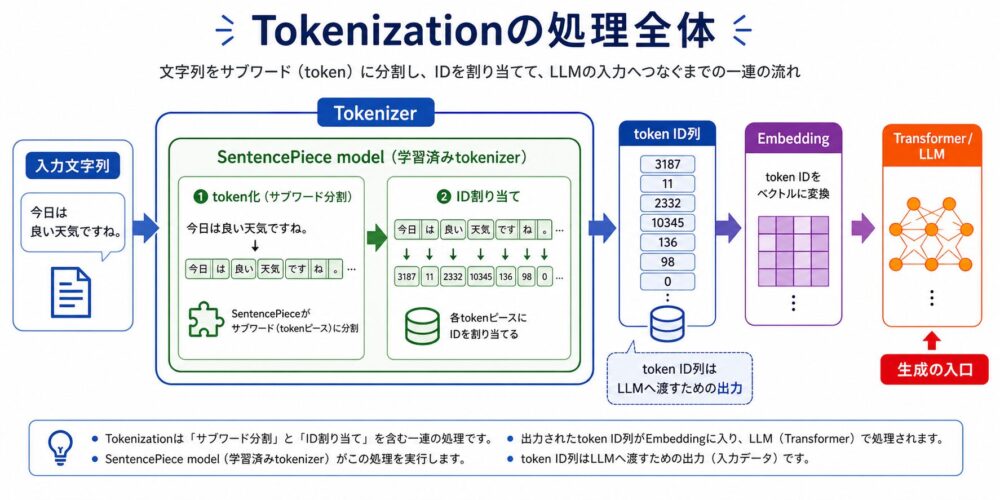
LLM(大規模言語モデル)は、次のtoken(テキストを分割した処理単位)を予測する技術です。
しかし、LLMは文字列をそのまま計算できるわけではありません。
前回のTokenization編で作ったtoken IDを、ニューラルネットワークが扱える数値ベクトルへ変換する必要があります。
この記事では、この変換処理で重要になるEmbedding(埋め込み)という技術を、BERT論文に基づいて解説します。
Embeddingの一般的な役割を先に整理し、そのうえで、BERTがtoken embedding、segment embedding、position embeddingをどのように組み合わせ、文脈化Embeddingを作るのかを見ていきます。
3行要約

- Embedding(埋め込み)は、token IDのような離散的な整数を、ニューラルネットワークが計算できる連続ベクトルへ変換する仕組みです。
- BERT論文は、Transformer Encoderを使って双方向の文脈を反映した言語表現を事前学習する方法を提案した論文です。
- BERTでは、入力時のEmbeddingに文脈が最初から入っているのではなく、Transformer層を通ることでcontextualized representation(文脈化表現)へ変化します。
Embeddingとは何か

Embeddingは、離散的なIDを連続値のベクトルへ変換する仕組みです。
日本語では「埋め込み」と訳されます。
たとえば、token ID 1176 を [0.12, -0.08, 0.44, ...] のような数値列へ変換します。
この数値列は、単なる番号ではなく、ニューラルネットワークの中で足し算、内積、Attention(入力同士の関係を重み付きで見る仕組み)などの計算に使える表現です。
前回のTokenization編では、文章がtoken列とtoken ID列へ変換されるところまで見ました。
しかし、Transformer(Attentionを中心に系列を処理するニューラルネットワーク)は、101 や 7592 のような整数IDを、そのまま意味として理解するわけではありません。
モデル内部では、各IDに対応するベクトルをEmbedding行列から取り出します。
語彙サイズを \(V\)、Embedding次元を \(H\) とすると、Embedding行列は次の形になります。
\[
E \in \mathbb{R}^{V \times H}
\]
token ID \(i\) に対するEmbeddingは、行列 \(E\) の \(i\) 番目の行です。
\[
x_i = E[i]
\]
この \(x_i\) が、Transformerへ渡される最初の表現になります。
| 表現 | 例 | 役割 |
|---|---|---|
| 文字列 | I like transformers |
人間が読む入力 |
| token | [I, like, transformers] |
tokenizerが作る単位 |
| token ID | [146, 1176, 19081] |
語彙表上の整数 |
| Embedding | [[...], [...], [...]] |
モデルが計算するベクトル |
LLM技術全体の中で見ると、Embeddingは「文字列処理」と「ニューラルネットワーク計算」をつなぐ入口です。
Tokenizationが文章をID列にする処理だとすれば、EmbeddingはそのID列をモデル内部のベクトル空間へ写す処理です。
Embeddingを使うことで、似た使われ方をするtokenが、学習を通じて近い方向のベクトルになりやすくなります。
ただし、Embeddingそのものに最初から人間が解釈できる意味が入っているわけではありません。
大量のテキストで学習する過程で、意味や構文に関係するパターンが重みとして獲得されます。
BERT論文から読み解く

BERT論文は、Embeddingを理解するうえで重要な題材です。
理由は、BERTが単にtoken IDをベクトルに変換するだけでなく、Transformer Encoderを通じて、文脈に応じて変わる表現を作る代表的なモデルだからです。
ここからは、BERT論文の内容を「Embeddingをどう作り、どう文脈化するか」という観点で読み解きます。
論文情報
| 項目 | 内容 |
|---|---|
| 論文タイトル | BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding |
| 著者 | Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova |
| 初版公開日 | 2018年10月11日 |
| 改訂版 | 2019年5月24日 v2 |
| 分野 | Computation and Language |
| arXiv | BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding |
| DOI | 10.48550/arXiv.1810.04805 |
論文概要
BERTは、Bidirectional Encoder Representations from Transformersの略です。
論文では、Transformer Encoderを使い、左右両方の文脈を反映した言語表現を事前学習する方法を提案しています。
BERTをEmbedding解説の題材にする理由は、次の3点です。
| 観点 | BERT論文から分かること |
|---|---|
| 入力表現 | token、文の所属、位置を足し合わせて入力Embeddingを作る |
| 文脈化 | Transformer Encoderによって、同じtokenでも文脈に応じた表現へ変わる |
| 転用 | 事前学習済みモデルを、分類、抽出、質問応答などへFine-tuningする |
つまり、BERTは「Embeddingとは何か」を理解するだけでなく、「EmbeddingがLLM内部でどのように意味を持つ表現へ変わるのか」を理解するための入口になります。
従来技術の課題

BERT以前にも、word2vecやGloVeのようなEmbedding技術は広く使われていました。
これらは静的Embedding(同じ単語に原則として同じベクトルを割り当てる表現)として有用でした。
しかし、静的Embeddingには、多義語や文脈依存の表現を扱いにくいという課題があります。
たとえば、bank という英単語は「銀行」と「川岸」の意味を持ちます。
静的Embeddingでは、この2つの意味が1つのベクトルに混ざりやすくなります。
I deposited money at the bank.
I sat on the bank of the river.また、BERT以前の多くの言語モデルは、左から右、または右から左の片方向文脈を使っていました。
そのため、単語の意味を決めるために左右両方の文脈を深く使う設計が難しい、という課題がありました。
| 観点 | 従来技術での課題 | BERTが狙った方向 |
|---|---|---|
| 多義語 | 同じ単語が同じ表現になりやすい | 文脈ごとに表現を変える |
| 文脈 | 片方向の情報に偏りやすい | 左右両方の文脈を見る |
| タスク転用 | タスクごとに特徴量設計が必要 | 事前学習済みモデルをFine-tuningする |
この課題に対して、BERTはMasked Language Modeling(入力の一部を隠して元tokenを予測する事前学習タスク)を使い、双方向文脈を学習できるようにしました。
BERTの入力表現:3種類のEmbeddingを足し合わせる

BERT論文で重要なのは、入力表現が単一のtoken embeddingだけではない点です。
各入力位置の表現は、次の3種類のEmbeddingの和として作られます。
\[
h_i^{(0)} = e_{\text{token}}(t_i) + e_{\text{segment}}(s_i) + e_{\text{position}}(i)
\]
ここで、\(t_i\) はtoken ID、\(s_i\) は文A/Bを示すsegment ID、\(i\) は系列内の位置です。
| Embedding | 何を表すか | BERTでの役割 |
|---|---|---|
| token embedding | token IDに対応する初期表現 | WordPiece tokenをベクトル化する |
| segment embedding | tokenが文Aか文Bか | 文ペアタスクやNSPで入力の所属を区別する |
| position embedding | tokenの位置 | Transformerに語順情報を与える |
Self-Attentionは、入力同士の関係を計算する強力な仕組みです。
一方で、Attentionだけではtokenの順番を直接持ちません。
そのため、position embeddingを足して、どのtokenが何番目にあるかを伝えます。
WordPieceと特殊tokenで入力列をそろえる

BERTは、WordPiece(単語をサブワードへ分割する方式)を使います。
WordPieceは、未知語を減らしながら語彙サイズを抑えるためのtokenization手法です。
論文では、30,000 tokenの語彙が使われています。
入力には、通常の単語やサブワードだけでなく、特殊tokenも含まれます。
| token | 役割 |
|---|---|
[CLS] |
系列の先頭に置かれ、分類タスクの代表表現として使われる |
[SEP] |
文の区切りや文ペアの境界を示す |
[MASK] |
Masked Language Modelingで予測対象を隠す |
文ペアを入力する場合は、次のような形になります。
[CLS] my dog is cute [SEP] he likes playing [SEP]このとき、前半の文にはsegment A、後半の文にはsegment BのEmbeddingが足されます。
tokens: [CLS] my dog is cute [SEP] he likes playing [SEP]
segment: A A A A A A B B B B
position: 0 1 2 3 4 5 6 7 8 9この3つの情報を足し合わせることで、BERTは「どのtokenか」「どちらの文か」「何番目か」を同時に受け取ります。
Masked Language Modelingで双方向文脈を学ぶ

Masked Language Modelingは、BERTの中心的な学習目的です。
BERTはTransformer Encoderを使うため、各tokenが左右両方の文脈を参照できます。
ただし、全文を見せたまま「次の単語を当てる」学習をすると、答えのtoken自身を見てしまう問題があります。
そこでBERTは、入力tokenの一部を隠し、その元tokenを当てるように学習します。
論文では、入力tokenの15%を予測対象にします。
ただし、選ばれたtokenをすべて [MASK] に置き換えるわけではありません。
| 選ばれたtokenの処理 | 割合 | 狙い |
|---|---|---|
[MASK] に置換 |
80% | 予測対象を明示的に隠す |
| ランダムtokenに置換 | 10% | 入力のノイズに頑健にする |
| そのまま残す | 10% | [MASK] がFine-tuning時に出ない差を緩和する |
損失は、予測対象になった位置だけで計算します。
\[
\mathcal{L}_{MLM} = – \sum_{i \in M} \log p(t_i \mid x_{\setminus M})
\]
\(M\) はmask対象位置の集合、\(x_{\setminus M}\) は一部がmaskされた入力です。
この学習により、各tokenの表現は周囲の文脈を使って意味を補う方向へ調整されます。
Next Sentence Predictionで文ペア関係を学ぶ

BERT論文では、Masked Language Modelingに加えて、Next Sentence Prediction(2つの文が連続しているかを判定する事前学習タスク)も使われています。
入力は文Aと文Bのペアです。
50%は実際に連続する文、50%はランダムに選んだ文Bです。
モデルは [CLS] の最終表現を使い、文Bが文Aの次に来るかを分類します。
\[
\mathcal{L}_{NSP} = – \log p(y \mid h_{[CLS]})
\]
| 学習目的 | 単位 | 何を学ばせたいか |
|---|---|---|
| MLM | token | 文脈から欠けた語を補う |
| NSP | 文ペア | 2文の関係を判定する |
なお、後続研究ではNSPの必要性について再検討されています。
そのため、現在のLLM理解では「BERT論文の設計としてNSPが使われた」と押さえつつ、すべての後続モデルに必須とは考えない方が安全です。
文脈化Embeddingとして下流タスクへ転用する

BERTの価値は、事前学習済みの文脈化表現を下流タスクへ転用できる点にあります。
論文では、タスクごとに大きな専用モデルを作るのではなく、BERT本体を初期化に使い、最後に小さな出力層を足してFine-tuning(事前学習済みモデルを特定タスクに追加学習すること)します。
| タスク | 使う表現 | 例 |
|---|---|---|
| 文分類 | [CLS] の最終表現 |
感情分類、自然言語推論 |
| token分類 | 各tokenの最終表現 | 固有表現抽出 |
| 質問応答 | 各tokenの開始/終了スコア | SQuAD形式の抽出型QA |
| 文検索 | 文全体の表現 | 類似文検索、RAGの検索器 |
注意点として、BERTの [CLS] 表現をそのまま汎用のsentence embeddingとして使うと、用途によっては期待ほど強くない場合があります。
検索や類似度計算では、Sentence-BERTのように文ペア類似度向けに調整されたモデルが使われることが多いです。
つまり、「BERTは文脈化表現を作る」ことと、「そのまま最高の検索Embeddingになる」ことは分けて考える必要があります。
実験結果
BERT論文では、GLUE、MultiNLI、SQuADなど、複数の自然言語理解タスクで当時のstate-of-the-art(当時最高水準)を更新したと報告されています。
arXiv概要では、GLUE score 80.5%、MultiNLI accuracy 86.7%、SQuAD v1.1 Test F1 93.2、SQuAD v2.0 Test F1 83.1が示されています。
| 評価 | 論文で示された結果の意味 |
|---|---|
| GLUE | 文分類や含意認識など複数タスクの総合評価 |
| MultiNLI | 文ペアの自然言語推論性能 |
| SQuAD v1.1 | 抽出型質問応答で答え範囲を当てる性能 |
| SQuAD v2.0 | 答えが存在しない質問も含む質問応答性能 |
この結果は、BERTの文脈化Embeddingが単独の特徴量として便利というだけでなく、Fine-tuningによって幅広いNLPタスクへ適応できることを示しています。
ただし、2018年当時の比較であり、現在の生成LLMの性能を直接比較するものではありません。
BERTは、生成よりも理解・分類・抽出に強いEncoder型モデルとして位置づけると分かりやすいです。
実装者視点で見るEmbedding
実装では、Embeddingは巨大な行列です。
語彙サイズ \(V\) と隠れ次元 \(H\) が大きくなるほど、Embedding層のパラメータ数も増えます。
\[
\text{parameters} = V \times H
\]
BERT Baseのように、語彙サイズが約30,000、隠れ次元が768なら、token embeddingだけで約2,300万パラメータになります。
これはモデル全体の中でも無視できないサイズです。
| 設計項目 | 実装上の注意 |
|---|---|
| 語彙サイズ | 大きいほどEmbedding行列が重くなる |
| 位置長 | 最大系列長を超える入力は切り詰めや分割が必要 |
| segment ID | 単文タスクではすべて0にする実装が多い |
| padding | attention maskと合わせて扱う必要がある |
| weight tying | 出力層とEmbeddingを共有する設計もある |
Embeddingの差し替えは、tokenizerの差し替えと強く結びつきます。
token IDとEmbedding行列の行が対応しているため、tokenizerだけ変えると、同じIDが別のtokenを指してしまう可能性があります。
Fine-tuning済みモデルでは、tokenizer、Embedding、出力層をセットで管理する必要があります。
実装例:BERT風の入力Embeddingを作る
以下は、BERT風にtoken embedding、segment embedding、position embeddingを足し合わせる最小例です。
実際のBERT実装では、LayerNorm(層ごとに値のスケールを整える処理)やdropout(過学習を抑えるために一部の値を落とす処理)も組み合わせます。
import logging
import torch
from torch import Tensor, nn
logger = logging.getLogger(__name__)
class BertStyleInputEmbedding(nn.Module):
"""Build BERT-style input embeddings from token, segment, and position IDs.
Args:
vocab_size: Number of tokens in the tokenizer vocabulary.
hidden_size: Embedding dimension used by the Transformer encoder.
max_position_embeddings: Maximum sequence length supported by the model.
segment_vocab_size: Number of segment IDs. BERT uses two for sentence A/B.
Returns:
A module that maps ID tensors to summed embedding tensors.
Raises:
ValueError: If one of the size arguments is not positive.
Examples:
>>> module = BertStyleInputEmbedding(30522, 768, 512, 2)
>>> token_ids = torch.tensor([[101, 2023, 2003, 102]])
>>> segment_ids = torch.zeros_like(token_ids)
>>> module(token_ids, segment_ids).shape
torch.Size([1, 4, 768])
"""
def __init__(
self,
vocab_size: int,
hidden_size: int,
max_position_embeddings: int,
segment_vocab_size: int = 2,
) -> None:
super().__init__()
if vocab_size <= 0:
raise ValueError("vocab_size must be positive")
if hidden_size <= 0:
raise ValueError("hidden_size must be positive")
if max_position_embeddings <= 0:
raise ValueError("max_position_embeddings must be positive")
if segment_vocab_size <= 0:
raise ValueError("segment_vocab_size must be positive")
self.token_embeddings = nn.Embedding(vocab_size, hidden_size)
self.segment_embeddings = nn.Embedding(segment_vocab_size, hidden_size)
self.position_embeddings = nn.Embedding(max_position_embeddings, hidden_size)
self.layer_norm = nn.LayerNorm(hidden_size)
self.dropout = nn.Dropout(0.1)
def forward(self, token_ids: Tensor, segment_ids: Tensor | None = None) -> Tensor:
"""Return summed BERT-style embeddings.
Args:
token_ids: Tensor shaped `(batch, seq_len)` containing tokenizer IDs.
segment_ids: Optional tensor shaped like `token_ids`. If omitted, all tokens use segment 0.
Returns:
Tensor shaped `(batch, seq_len, hidden_size)`.
Raises:
ValueError: If `token_ids` is not 2D or if `segment_ids` has a mismatched shape.
Examples:
>>> module = BertStyleInputEmbedding(100, 16, 32)
>>> ids = torch.tensor([[1, 2, 3]])
>>> module(ids).shape
torch.Size([1, 3, 16])
"""
if token_ids.ndim != 2:
raise ValueError("token_ids must have shape (batch, seq_len)")
batch_size, seq_len = token_ids.shape
if segment_ids is None:
segment_ids = torch.zeros_like(token_ids)
if segment_ids.shape != token_ids.shape:
raise ValueError("segment_ids must have the same shape as token_ids")
position_ids = torch.arange(seq_len, device=token_ids.device).unsqueeze(0)
position_ids = position_ids.expand(batch_size, seq_len)
logger.debug("build embeddings: batch=%d seq_len=%d", batch_size, seq_len)
# BERTの入力仕様にそろえるため、3種類のID情報を同じhidden_sizeで加算する。
embeddings = (
self.token_embeddings(token_ids)
+ self.segment_embeddings(segment_ids)
+ self.position_embeddings(position_ids)
)
logger.info("created input embeddings: shape=%s", tuple(embeddings.shape))
return self.dropout(self.layer_norm(embeddings))よくある誤解

| 誤解 | 正確な情報・解釈 |
|---|---|
| Embeddingは単語の意味そのものを保存した辞書である | Embeddingは学習で得られるベクトル表現であり、意味は文脈とタスクを通じて現れる |
| token embeddingだけ見ればBERTの理解が分かる | BERTで重要なのはTransformer層を通った後の文脈化表現 |
[CLS] は常に最高のsentence embeddingである |
分類には便利だが、類似度検索では専用に学習されたモデルが有利なことが多い |
| position embeddingは補助的なので不要 | Self-Attentionだけでは語順を直接区別しにくいため、位置情報が必要 |
| BERTはGPTと同じように文章生成が得意 | BERTはEncoder型で、主に理解・分類・抽出に向く |
Embeddingを理解するときは、「IDをベクトルへ変換する入力層」と「Transformerを通った後の文脈化表現」を分けることが大切です。
この2つを混ぜてしまうと、BERTの強みや、検索Embeddingとして使うときの注意点を誤解しやすくなります。
限界点

BERTは、自然言語理解タスクに大きな影響を与えたモデルです。
一方で、現在のLLMの文脈で見ると、いくつかの限界があります。
| 限界点 | 内容 | 実務での影響 |
|---|---|---|
| 生成が主目的ではない | BERTはEncoder型で、次tokenを逐次生成する設計ではない | ChatGPTのような対話生成にはDecoder型やEncoder-Decoder型が使われやすい |
| 長文処理が重い | Self-Attentionの計算量は系列長に対して大きくなりやすい | 長い文書をそのまま入力しにくい |
[CLS] が万能ではない |
分類には便利だが、検索や類似度では専用学習が必要な場合がある | RAGや文書検索ではSentence-BERT系などを検討する |
| tokenizerとEmbeddingが固定される | 語彙を変えるとEmbedding行列との対応が崩れる | ドメイン追加や多言語対応で再学習・追加学習が必要になる |
| メモリ消費が大きい | Embedding行列やTransformer層がパラメータを持つ | エッジデバイスや組み込み機器では搭載が難しい |
ハードウェア搭載を考えると、Embedding層だけでも無視できないサイズになります。
BERT Baseでは、token embeddingだけで約2,300万パラメータになります。
さらに、推論時には中間activation(層の途中で保持する計算結果)やattention maskも必要です。
スマートフォン、カメラ、車載機器のようなメモリと電力が限られる環境では、モデルサイズ、最大系列長、推論遅延、消費電力を同時に考える必要があります。
今後の展望

BERTの限界を踏まえると、今後の発展方向は大きく5つに整理できます。
| 発展方向 | 何を改善するか | 期待される効果 |
|---|---|---|
| 長文対応 | 系列長に対する計算量やメモリ消費 | 長い文書理解、契約書、議事録、技術文書への応用 |
| 検索特化Embedding | [CLS] そのままではなく、類似度学習に合わせる |
RAG、FAQ検索、意味検索の精度改善 |
| 軽量化 | 蒸留、枝刈り、量子化でパラメータや計算量を削減 | エッジデバイスや低遅延サービスへの搭載 |
| ドメイン適応 | 医療、法務、製造など専門領域の語彙や表現を学ぶ | 専門文書の分類・抽出・検索で使いやすくなる |
| マルチモーダル連携 | テキストEmbeddingを画像・音声などの表現と結びつける | VLM(画像と言語を扱うモデル)や検索拡張での応用 |
特にハードウェア搭載では、蒸留(大きなモデルの振る舞いを小さなモデルへ移す学習)や量子化(重みやactivationの数値精度を下げて軽くする技術)が重要になります。
Embedding行列の圧縮、語彙の見直し、最大系列長の制御も、実装上の大きな論点です。
BERTそのものが最新の生成LLMを置き換えるわけではありません。
しかし、文脈化Embedding、事前学習、Fine-tuningという考え方は、現在のLLMや検索システムを理解するうえでも重要な土台です。
まとめ
Embeddingは、token IDをベクトルへ変換するLLMの入口です。
BERT論文では、token embedding、segment embedding、position embeddingを足し合わせ、Transformer Encoderへ入力します。
そして、Masked Language Modelingにより、各tokenの表現は左右の文脈を反映した文脈化Embeddingへ変わります。
Embeddingを単なる「単語を数値にする表」と見ると、BERTの本質を見落とします。
本当に重要なのは、入力EmbeddingがSelf-Attentionを通じて文脈に応じて変化し、分類、抽出、質問応答などに転用できる表現になることです。
関連技術
| 技術 | Embeddingとの関係 |
|---|---|
| Tokenization | 文字列をtoken IDに変換し、Embeddingの入力を作る |
| Positional Encoding | tokenの順序を表す情報を追加する |
| Self-Attention | Embedding同士の関係を計算し、文脈化表現を作る |
| Sentence-BERT | BERTを文類似度・検索向けに調整する |
| Dense Retrieval | 文書や質問をベクトル化して近傍検索する |
Embeddingは単独の技術ではなく、Tokenization、Attention、Transformer、検索システムとつながっています。
特にRAG(検索で外部文書を補う生成方式)では、質問と文書をどのようなEmbedding空間へ写すかが、検索精度に直接影響します。
次に読むべき記事

コメント