WindowQuantとは?動画VLMのKV Cacheを軽量化する混合精度量子化手法を解説
3文要約
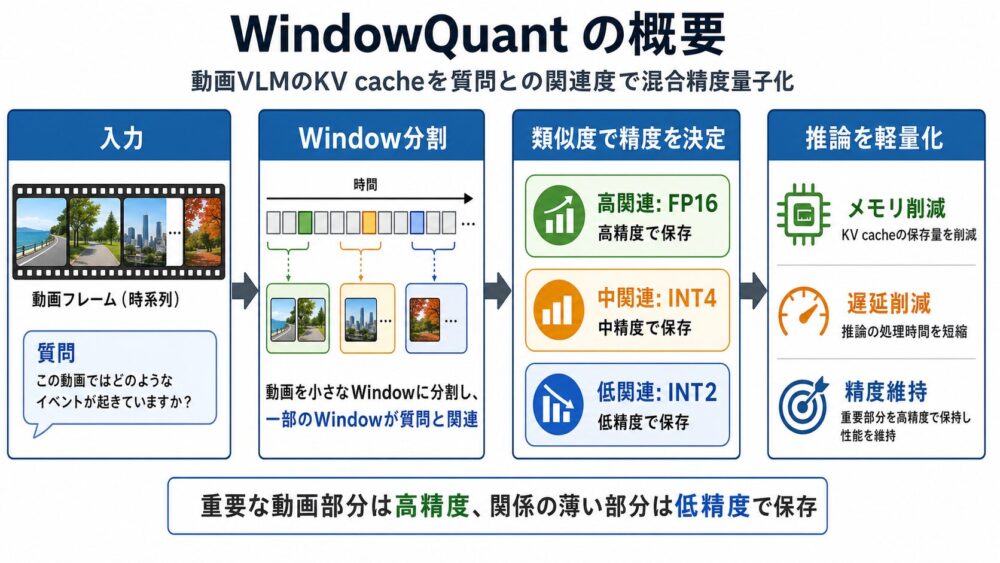
WindowQuantは、動画VLMの推論で肥大化するKV Cache(推論時に再利用するKey/Value中間表現)を軽量化する手法です。
動画を複数のwindow(短い時間区間)に分け、テキスト質問との関連度が高い部分はFP16、低い部分はINT2のように精度を変えて保存します。
論文では、精度を維持または改善しながら、KV Cacheのメモリ使用量とデコード遅延を削減できることが示されています。
論文情報
| 項目 | 内容 |
|---|---|
| 論文タイトル | WindowQuant: Mixed-Precision KV Cache Quantization based on Window-Level Similarity for VLMs Inference Optimization |
| 著者 | Wei Tao, Xiaoyang Qu, Peiqiang Wang, Guokuan Li, Jiguang Wan, Kai Lu, Jianzong Wang |
| 公開日 | 2026年5月4日 |
| 分野 | Vision-Language Model, 動画理解, 推論最適化 |
| 論文リンク | https://arxiv.org/html/2605.02262v1 |
背景:動画VLMではKV Cacheが重くなる
VLM(Vision-Language Model、画像や動画と言語を同時に扱うモデル)は、動画質問応答や動画理解タスクで使われます。
動画を扱う場合、各フレームはvisual token(画像・動画情報をモデルが扱うためのベクトル表現)に変換されます。
動画が長くなるほどvisual token数が増え、Transformer内部で保持するKV Cacheも大きくなります。
WindowQuant論文では、LLaVA-OneVision-0.5Bで30秒動画を処理すると、visual token由来のKV Cacheが約21.6GBに達する例が示されています。
つまり、動画VLMではモデル重みだけでなく、入力動画に由来するKV Cacheが大きなボトルネックになります。
KV Cacheとは何か
KV Cacheは、Transformerのattention(入力token同士の関係を計算する仕組み)で使うKeyとValueを保存しておくキャッシュです。
Transformerの基本は、元論文 Attention Is All You Need で提案されたQuery、Key、Valueにもとづくattentionです。
| 要素 | 役割 | 直感 |
|---|---|---|
| Query | 今のtokenが何を探しているか | 検索クエリ |
| Key | 過去tokenが何を持っているか | 検索対象の見出し |
| Value | 実際に取り出す情報 | 検索結果の中身 |
attentionの基本式は次のように表せます。
Attention(Q, K, V) = softmax(QK^T / sqrt(d)) V自己回帰生成(1 tokenずつ次のtokenを生成する方式)では、過去tokenのKeyとValueは一度計算すれば変わりません。
そのため、毎回すべてを再計算するのではなく、過去tokenのKey/ValueをKV Cacheとして保存して再利用します。
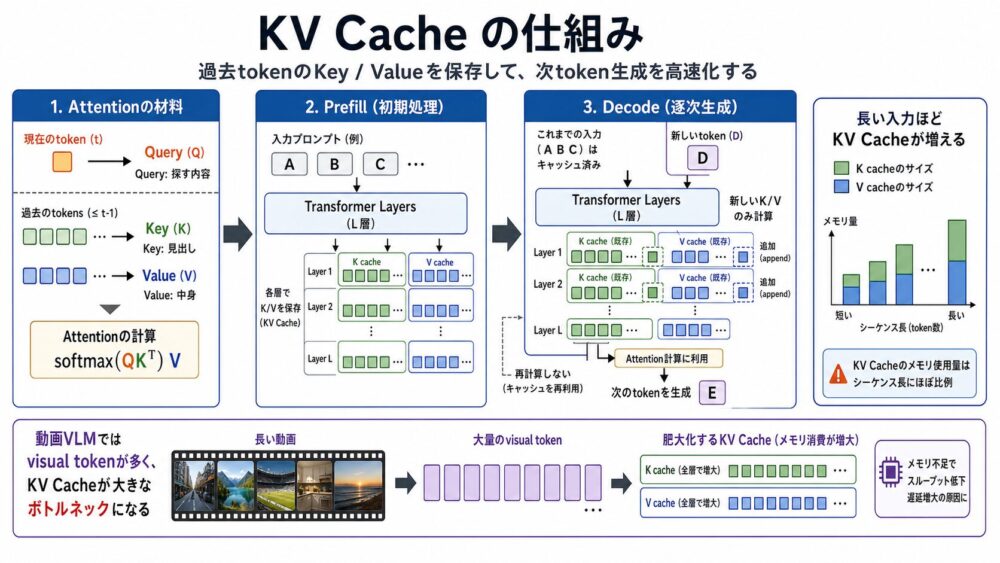
KV Cacheのメリットと課題
KV Cacheを使うと、過去tokenのKey/Valueを再計算しなくてよくなるため、デコードが高速になります。
一方で、長い入力や動画入力ではKV Cache自体が巨大になり、GPUメモリとメモリ帯域を圧迫します。
| 観点 | メリット | 課題 |
|---|---|---|
| 計算量 | 過去tokenのK/V再計算を避けられる | attentionでは過去K/Vの読み出しが必要 |
| 速度 | decodeが速くなる | cacheが巨大だと読み出しが遅くなる |
| メモリ | 計算結果を再利用できる | 長文・動画ではGPUメモリを大量消費する |
| 実装 | 多くの推論フレームワークで標準対応 | cache配置、断片化、量子化が難しい |
このKV Cacheのメモリ問題は、LLM servingでも重要な課題です。
たとえば Efficient Memory Management for Large Language Model Serving with PagedAttention は、KV Cacheをブロック単位で効率よく管理することで、LLM servingのメモリ効率を改善する研究です。
既存手法の課題
KV Cacheを軽くする代表的な方法に量子化(数値表現のbit数を下げてメモリと計算量を削減する手法)があります。
たとえばFP16をINT8、INT4、INT2のような低bit表現に変換すれば、メモリ使用量は大きく減ります。
ただし、すべてのKV Cacheを同じbit幅で量子化すると、重要な情報まで粗くなり、精度が落ちる可能性があります。
一方で、token単位で重要度を判定して混合精度にする方法は探索コストが高く、ハードウェア上でも扱いにくいという課題があります。
WindowQuantの提案:重要なwindowだけ高精度で残す
WindowQuantの基本アイデアは、動画全体のKV Cacheを同じ精度で保存しないことです。
動画を複数のwindowに分け、各windowがテキスト質問とどれくらい関連しているかを計算します。
関連度が高いwindowはFP16で保持し、関連度が低いwindowはINT2まで圧縮します。
| 関連度 | 精度 | 意味 |
|---|---|---|
| 高い | FP16 | 質問に重要なので高精度で保持 |
| 中程度 | INT4 | 精度と圧縮率のバランスを取る |
| 低い | INT2 | 関連が薄いため強く圧縮する |
類似度はどう計算するのか
WindowQuantでは、各動画windowのvisual tokenと、テキスト質問のtext tokenを埋め込み空間で比較します。
論文のablationでは、Pearson correlation、Euclidean distance、cosine similarityが比較されています。
| 類似度関数 | レイテンシ | 精度 | コメント |
|---|---|---|---|
| Pearson correlation | 55ms | 63.2% | 相関を見るが、やや遅い |
| Euclidean distance | 49ms | 61.4% | 距離ベースだが精度は低め |
| Cosine similarity | 48ms | 64.1% | 最も速く、精度も高い |
最終的に、本論文ではcosine similarity(ベクトルの向きの近さを見る指標)が採用されています。
処理の流れは次のようになります。
video window -> visual encoder -> visual token window embedding
text prompt -> text encoder -> text token embedding
各windowについて:
similarity(window, prompt) = cosine_similarity(visual_window_embedding, text_embedding)
similarity > T_high なら FP16
similarity < T_low なら INT2
それ以外なら INT4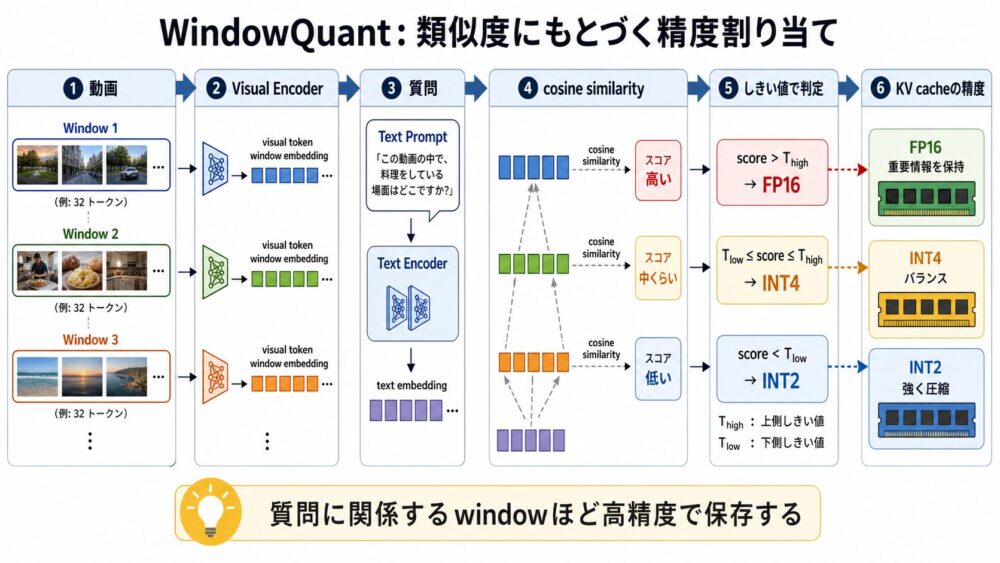
なぜ混合精度の配置が重要なのか
FP16、INT4、INT2のKV Cache windowがメモリ上にばらばらに並ぶと、GPUの計算効率が落ちます。
これはkernel単位というより、KV Cache内のwindowブロックが物理メモリ上で異なるbit幅として交互に並ぶことによるメモリアクセス効率の低下です。
たとえば、素朴にwindow順で保存すると次のようになります。
Window 0: FP16
Window 1: INT2
Window 2: FP16
Window 3: INT4
Window 4: INT2
Window 5: INT4この状態では、GPUがattention計算を行うときに、異なるデータ形式をまたぎながら読み出す必要があります。
その結果、cache line(メモリをまとめて読む単位)やSIMD(複数データを一命令で処理する方式)に乗りにくくなります。
| 問題 | 何が起きるか |
|---|---|
| アラインメント崩れ | 2bit、4bit、16bitが混ざり、メモリ境界にきれいに乗りにくい |
| cache line効率低下 | 必要なデータだけを連続して読みづらい |
| metadata参照増加 | 各windowのbit幅を見ながら処理する必要がある |
| SIMD効率低下 | 同じ命令でまとめて処理しづらい |
| kernel最適化の難化 | bit幅ごとに最適な演算パスを作りにくい |
WindowQuantでは、同じbit幅のwindowを物理メモリ上でまとめます。
INT2 windows: Window 1, Window 4
INT4 windows: Window 3, Window 5
FP16 windows: Window 0, Window 2これにより、INT2、INT4、FP16のブロックごとにattention計算を行いやすくなります。
本論文での粒度は、基本的にはtoken単位ではなくwindow単位です。
標準設定ではwindow sizeは32で、1つのwindow内のvisual tokenは同じbit幅で量子化されます。
なぜ最初のwindowはFP16で保持するのか
WindowQuantでは、最初のwindowを類似度に関係なくFP16で保持します。
これは、先頭付近のtokenが後続の推論に強く影響する可能性があるためです。
LLMでは、系列先頭付近のtokenにattentionが集まりやすい現象が知られています。
このようなtokenは、意味的な内容だけでなく、attention計算上の安定点として働くことがあります。
動画VLMでも、最初のwindowにはシーンの初期状態、対象物の配置、人物や物体の存在、場面設定などが含まれることがあります。
ここを強く量子化すると、後続の変化を解釈するための基準が粗くなります。
たとえば「人物が何を持ったか」を答えるには、最初に何も持っていなかったのか、すでに持っていたのかという初期状態が重要です。
そのため、最初のwindowをFP16で保持することは、推論全体の文脈を安定させる保険として機能します。
論文のablationでも、最初のwindowをFP16固定にすることで精度維持に寄与することが示されています。
実験結果の要約
WindowQuantは、LLaVA-OneVision-Qwen2、VideoLLaVA、VideoLLaMA2、InternVL2などの動画VLMで評価されています。
主な結果として、KV Cacheのメモリ使用量とデコード遅延を削減しながら、精度を維持または改善しています。
たとえば100フレーム入力では、KV Cache使用量が1.05GBから0.19GBに減少したと報告されています。
また、デコード段階の遅延は2451msから1640msに短縮されています。
一部のベンチマークではFP16のベースラインより精度が上がっています。
これは、関連度の低い情報を低精度化することで、推論に不要なノイズが抑えられた可能性があります。
ただし、この効果はタスクやモデルに依存するため、常に精度が上がるとまでは言えません。
実装者視点で面白い点
WindowQuantの面白さは、動画全体を均一に圧縮しない点です。
動画質問応答では、質問に答えるために本当に重要な場面は一部であることが多いです。
そのため、質問に関係するwindowは高精度で残し、関係の薄いwindowは強く圧縮する設計は自然です。
また、token単位ではなくwindow単位で制御することで、探索コストと実装複雑性を抑えています。
精度だけでなく、メモリ配置やGPU上の計算効率まで考慮している点も実用的です。
限界と注意点
WindowQuantは、細かい視覚情報や一瞬の動きが重要なタスクでは性能が落ちる可能性があります。
Object ExistenceやMoving Attributeのように、細粒度の視覚判断が必要な場合、INT2量子化によって必要な情報が失われることがあります。
また、WindowQuantが主に削減するのはKV Cacheです。
FFN(Feed-Forward Network、Transformer内部の全結合層)などの中間活性メモリは残るため、ピークメモリ全体の削減には別の最適化も必要です。
今後の展望
WindowQuantの考え方は、長尺動画を扱うVLMで特に重要になりそうです。
今後は、KV Cache量子化に加えて、フレーム選択、token pruning(重要度の低いtokenを削除する手法)、attention最適化、中間活性メモリ削減などを組み合わせる方向が考えられます。
また、質問内容に応じて保存精度を変える設計は、動画だけでなく長文マルチモーダル入力にも応用できる可能性があります。
まとめ
WindowQuantは、動画VLMのKV Cacheを質問との関連度に応じてwindow単位で混合精度量子化する手法です。
重要なwindowはFP16で保持し、中程度のwindowはINT4、関連度の低いwindowはINT2で保存します。
これにより、質問応答に必要な情報を残しながら、KV Cacheのメモリ使用量とデコード遅延を削減できます。
特に長尺動画を扱うVLMでは、KV Cacheが大きなボトルネックになります。
WindowQuantは、その課題に対して「すべての動画tokenを同じ重要度として扱わない」という実用的な方向性を示した論文です。
参考リンク
- 論文HTML: https://arxiv.org/html/2605.02262v1
- Transformer元論文: https://arxiv.org/abs/1706.03762
- Hugging Face Cache strategies: https://huggingface.co/docs/transformers/en/kv_cache
- PagedAttention論文: https://arxiv.org/abs/2309.06180
- Zenn要約記事: https://zenn.dev/kashu0777/articles/20260508-windowquant-vlm-kv-cache

コメント