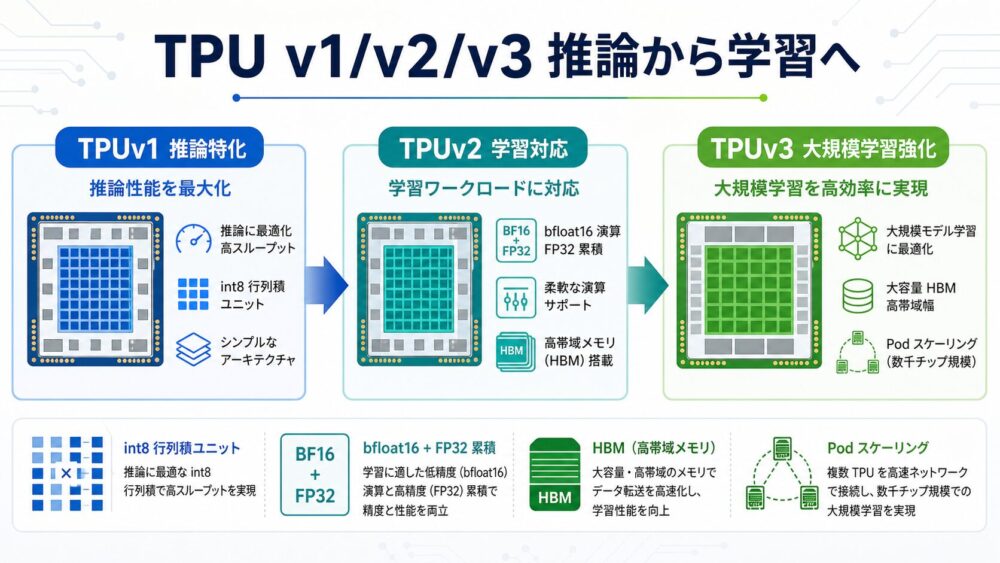
TPUv1は、主にニューラルネットワーク推論を高速化するために設計されたASIC(Application-Specific Integrated Circuit、特定用途向け集積回路)でした。
TPUv2では、bfloat16(float32に近い値域を持つ16-bit浮動小数点形式)演算、float32累積、HBM(High Bandwidth Memory、高帯域メモリ)、複数チップ構成により、深層学習の学習を主要用途として扱いやすくなりました。
TPUv3は、TPUv2で確立した学習向けの基盤を、演算性能、メモリ容量、メモリ帯域、Pod規模の分散学習の面で強化した世代です。
本記事の目的
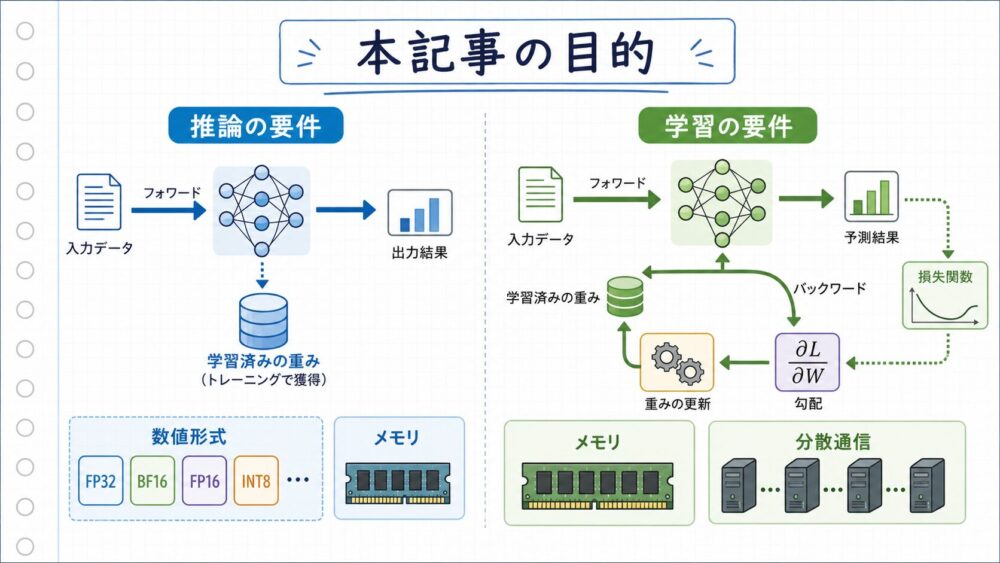
本記事の目的は、TPUv1、TPUv2、TPUv3の違いを、単純な世代比較ではなく、「推論から学習へ必要なハードウェア要件がどう変わったのか」という視点で整理することです。
TPUv1は、行列積を非常に高速に実行できる専用チップでした。
しかし、行列積器が速いことと、一般的な深層学習の学習を安定して実行しやすいことは同じではありません。
推論では、学習済みの重みを使って順伝播を実行することが中心です。
一方、学習では、順伝播に加えて、逆伝播、勾配計算、重み更新、optimizer state(最適化手法が保持する補助状態)、複数チップ間の勾配同期が必要になります。
そのため、TPUv1からTPUv2への変化は、単に行列積器を速くしただけではありません。
数値形式、累積精度、メモリ容量、メモリ帯域、分散学習を、ハードウェアとシステムの両面で扱えるようにしたことが本質です。
3文要約
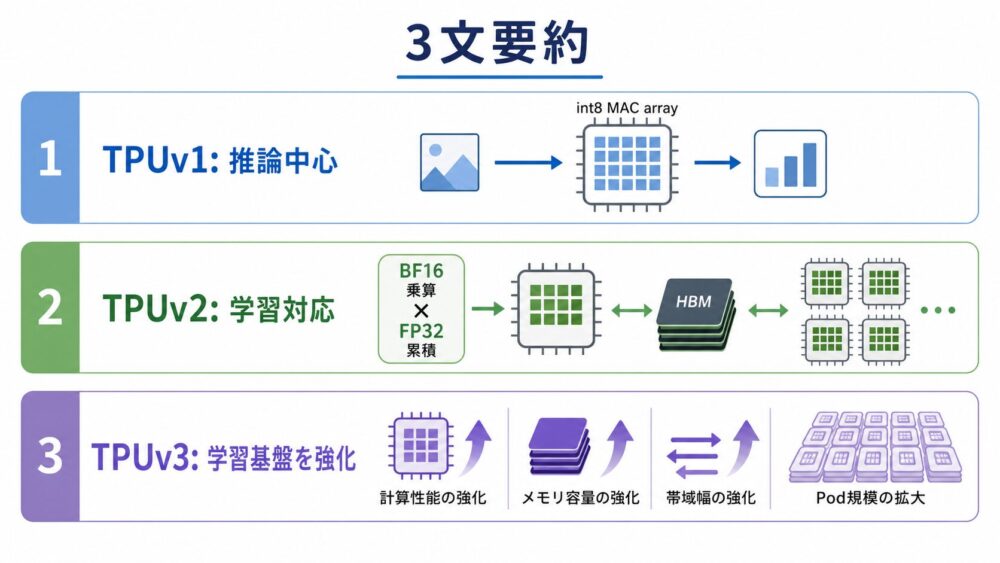
TPUv1は、JouppiらのISCA 2017論文で、主にデータセンター内のニューラルネットワーク推論を高速化するASICとして説明されています。
TPUv2では、bfloat16入力による行列演算、float32累積、HBM、複数チップ構成により、学習と推論の両方を扱うCloud TPUへ拡張されました。
TPUv3は、TPUv2の学習対応を維持しつつ、演算性能、HBM容量、メモリ帯域、Pod規模の分散学習性能を強化した世代です。
論文・一次資料情報
この記事では、査読論文・arXiv論文・Google Cloud公式ドキュメントを区別して扱います。
| 種別 | タイトル | 著者・組織 | 年 | この記事で参照する内容 | リンク |
|---|---|---|---|---|---|
| 査読論文 | In-Datacenter Performance Analysis of a Tensor Processing Unit | Norman P. Jouppi et al. | 2017 | TPUv1の設計目的、推論特化、8-bit MAC、Matrix Multiply Unit、Accumulator、On-chip Memory、推論性能・電力効率比較 | In-Datacenter Performance Analysis of a Tensor Processing Unit |
| arXiv論文 | Benchmarking TPU, GPU, and CPU Platforms for Deep Learning | Yu Emma Wang, Gu-Yeon Wei, David Brooks | 2019 | TPUv2/v3の構成、bfloat16演算とfloat32累積、HBM容量・帯域、v2/v3性能差、学習ベンチマーク | Benchmarking TPU, GPU, and CPU Platforms for Deep Learning |
| arXiv論文 | A Study of BFLOAT16 for Deep Learning Training | Dhiraj Kalamkar et al. | 2019 | bfloat16の指数部・仮数部、float16/float32/int8との違い、学習でbfloat16が使いやすい理由、mixed precision training | A Study of BFLOAT16 for Deep Learning Training |
| 公式資料 | TPU architecture | Google Cloud | 2026年確認 | Cloud TPUのMXU、TensorCore、bfloat16入力、float32累積、HBM、Pod、Slice、Interconnectの用語確認 | TPU architecture |
| 公式資料 | TPU v2 | Google Cloud | 2026年確認 | TPUv2 slice、512 chips、reconfigurable high-speed linksなどの公式仕様確認 | TPU v2 |
| 公式資料 | TPU v3 | Google Cloud | 2026年確認 | TPUv3の123 TFLOPS/chip、32 GiB HBM2、900 GB/s、1024 chips Pod、AllReduce bandwidthなど | TPU v3 |
| 公式資料 | Improve your model’s performance with bfloat16 | Google Cloud | 2026年確認 | Cloud TPUでのbfloat16行列演算、float32累積、メモリ削減、帯域削減の説明 | Improve your model’s performance with bfloat16 |
| 公式資料 | Training on TPU slices | Google Cloud | 2026年確認 | TPU Pod、複数TPUへのスケール、batch size、学習時のスケーリング注意点 | Training on TPU slices |
ここで注意したいのは、JouppiらのTPUv1論文と、WangらのTPUv2/v3ベンチマーク論文では、対象世代と評価目的が異なることです。
Jouppiらの論文は、TPUv1をデータセンター推論アクセラレータとして分析しています。
Wangらの論文は、Cloud TPU v2/v3、NVIDIA V100、CPUを対象に、主に学習ベンチマークを比較しています。
Google Cloud公式ドキュメントは、査読論文ではありません。
この記事では、公式仕様の確認用として使い、論文で実証された内容とは分けて扱います。
TPUv1は何のために設計されたのか
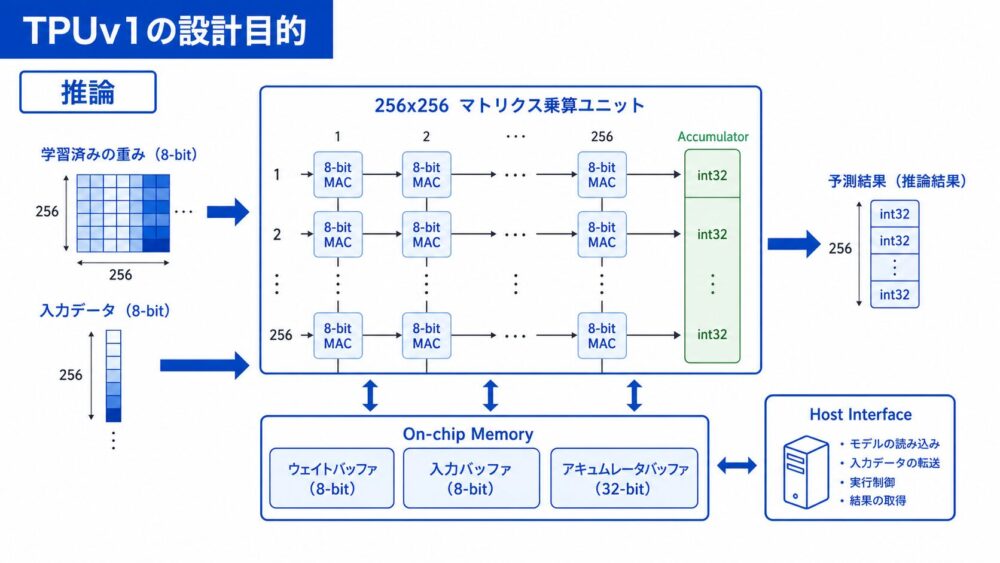
Jouppiらの論文では、TPUv1は、Googleのデータセンターでニューラルネットワークの推論フェーズを加速するために設計されたASICとして説明されています。
論文で評価されたワークロードは、MLP(Multi-Layer Perceptron、多層パーセプトロン)、CNN(Convolutional Neural Network、畳み込みニューラルネットワーク)、LSTM(Long Short-Term Memory、系列処理向けニューラルネットワーク)などで、Googleのデータセンター内推論需要の大部分を代表するものとして扱われています。
TPUv1の中核は、65,536個の8-bit MAC(Multiply-Accumulate、乗算加算)で構成されるMatrix Multiply Unit(行列積ユニット)です。
ピーク性能は92 TOPS(Tera Operations Per Second、1秒あたり兆回規模の演算)とされ、28 MiBのsoftware-managed on-chip memory(ソフトウェア管理のオンチップメモリ)を持ちます。
TPUv1では、低精度の積和を大量に並べ、推論に必要な行列積を高い電力効率で処理することが狙いでした。
論文では、同時期にデータセンターで使われていたHaswell CPUやNVIDIA K80 GPUと比較し、TPUv1が推論ワークロードで高い性能とTOPS/Wattを示したことが報告されています。
TPUv1の推論向け設計を、学習との対比で見ると次のようになります。
| 観点 | 推論で中心になること | 学習で追加されること |
|---|---|---|
| 計算 | 学習済み重みによる順伝播 | 順伝播、逆伝播、勾配計算、重み更新 |
| 数値形式 | 量子化済み重みとactivationを扱いやすい | 勾配や小さな更新量を長期間扱う必要がある |
| メモリ | 重み、入力、出力 | activation、gradient、weight gradient、optimizer state、一時バッファ |
| 通信 | 推論サーバ内のレイテンシが重要 | 複数チップ・複数ホストの勾配同期が重要 |
推論では、学習済み重みを使った順伝播が中心です。
もちろん推論にも精度やメモリ帯域は重要ですが、学習ほど多種類の中間値と更新処理を持ちません。
そのため、8-bit中心の行列積器で推論を高速化する設計は合理的でした。
ただし、行列積器が高速であることと、学習を実用的に実行できることは別問題です。
この点を混同すると、「TPUv1は行列積が速いのだから、そのまま学習にも向くはずだ」という誤解につながります。
なぜニューラルネットワーク学習にはより多くのハードウェア要件が必要なのか
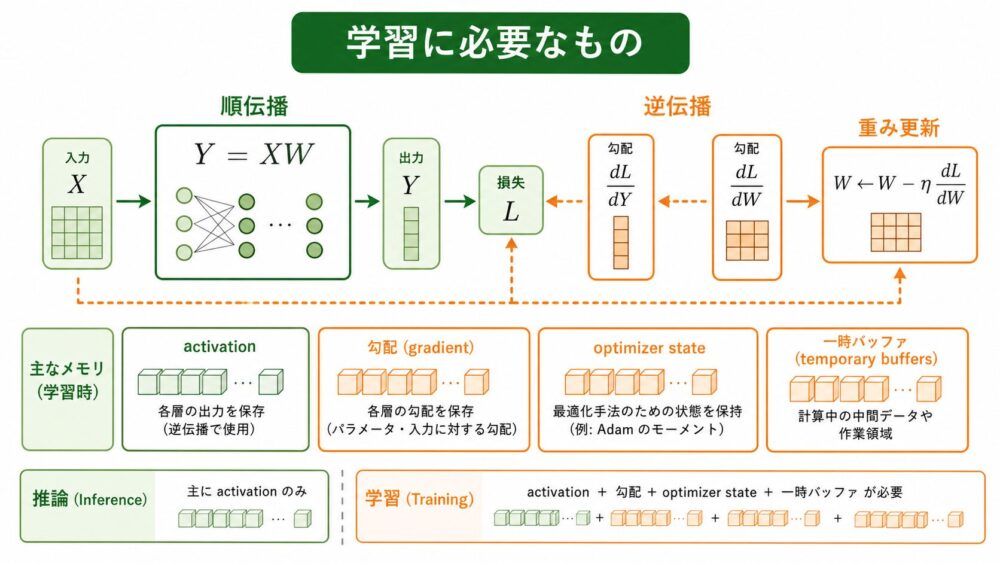
学習では、順伝播だけでなく、逆伝播と重み更新が必要です。
単純な線形層で考えると、順伝播は次の行列積です。
\[ Y = XW \]
ここで、\(X\) は入力またはactivation、\(W\) は重み、\(Y\) は出力です。
損失 \(L\) から逆伝播すると、重みに対する勾配は概念的に次のような形になります。
\[ \frac{\partial L}{\partial W} = X^{\mathrm{T}} \frac{\partial L}{\partial Y} \]
そして、最も単純なSGD(Stochastic Gradient Descent、確率的勾配降下法)の更新は次のように書けます。
\[ W \leftarrow W – \eta \frac{\partial L}{\partial W} \]
ここで、\(\eta\) はlearning rate(学習率)です。
この3つの式から分かるように、学習では順伝播の \(XW\) だけでは終わりません。
逆伝播では、出力側の勾配、入力側のactivation、重み、重みに対する勾配などを扱います。
さらにAdam(Adaptive Moment Estimation、勾配の移動平均などを使う最適化手法)のようなoptimizerでは、重み本体に加えて、一次モーメント、二次モーメントなどのoptimizer stateも保持します。
| データ | 推論 | 学習 |
|---|---|---|
| weight | 必要 | 必要 |
| input | 必要 | 必要 |
| output | 必要 | 必要 |
| activation | 一部必要 | 逆伝播のため多く保持する |
| gradient | 基本的に不要 | 必要 |
| weight gradient | 不要 | 必要 |
| optimizer state | 不要 | 最適化手法によって必要 |
| temporary buffer | 必要な場合あり | より多く必要になりやすい |
このため、学習ではメモリ容量だけでなく、メモリ帯域も重要になります。
容量は「必要な値が収まるか」に効きます。
帯域は「演算器へ値を十分な速度で供給できるか」に効きます。
また、学習では小さな重み更新を長期間積み重ねます。
勾配が小さくなったり、optimizer stateの値域が広くなったりするため、数値表現と累積精度が重要です。
これが、推論特化のint8設計と、学習アクセラレータに求められる数値設計の違いです。
TPUv1は「学習不可能」ではなく「学習向けに最適化されていない」
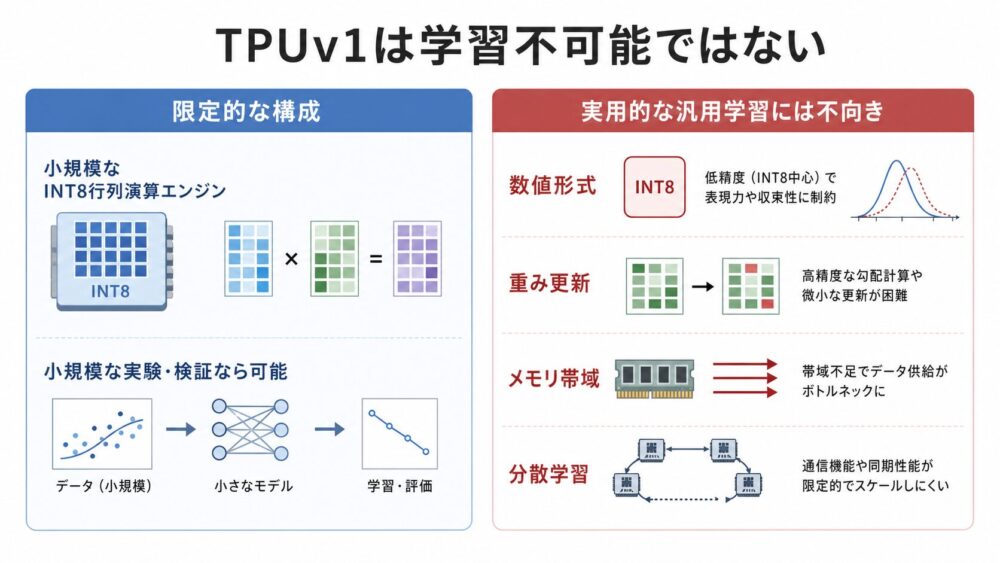
ここは丁寧に分ける必要があります。
TPUv1は、行列積器を持つため、限定的な低精度学習や、学習処理の一部を構成する余地は理論上あります。
たとえば、順伝播や一部の勾配計算は行列積として表せます。
そのため、「TPUv1では絶対に学習できない」と断定するのは強すぎます。
一方で、TPUv1は、一般的なDNN(Deep Neural Network、深層ニューラルネットワーク)の学習を主目的として設計されたチップではありません。
Jouppiらの論文が主に扱っているのは、データセンター推論ワークロードです。
TPUv1の8-bit MAC、int32 accumulator(32-bit整数累算器)、オンチップメモリは、推論向けの電力効率とレイテンシに強く寄せた設計として理解するのが自然です。
int8中心で学習を構成しようとすると、次のような課題があります。
| 課題 | なぜ学習で難しくなるか |
|---|---|
| 量子化スケール | layerごと、tensorごと、時刻ごとに値域が変わるため、固定スケールでは表現しにくい |
| 丸め誤差 | 小さな勾配や更新量が丸めで消えやすい |
| 飽和 | 値域を超えた勾配やactivationが上限・下限に張り付き得る |
| 勾配表現 | 勾配は分布が広く、外れ値や小さい値を同時に扱う必要がある |
| master weight | 低精度演算を使う場合でも、更新を安定させるため高精度の重み保持が必要になりやすい |
| optimizer state | Adamなどでは重み以外の状態が増え、メモリ容量と帯域を圧迫する |
| 分散同期 | 複数チップ学習では勾配同期やAllReduce(複数デバイスの値を集約して全員へ配る通信)が必要になる |
int32 accumulatorがあることも、学習全体が十分になることを意味しません。
Accumulatorは、積和の部分和をより広いビット幅で保持するために重要です。
しかし、学習では、部分和だけでなく、勾配、重み更新、optimizer state、checkpoint、複数チップ通信まで含めた数値設計が必要です。
よくある誤解を整理すると、次のようになります。
| よくある誤解 | 正確な情報・解釈 |
|---|---|
| TPUv1は行列積器なので、そのまま学習にも向く | 行列積は可能でも、学習には数値精度、メモリ帯域、更新処理、分散学習など追加要件がある |
| int32 accumulatorがあるので学習には十分 | 部分和の累積だけでなく、勾配、重み更新、optimizer stateなど全体の数値設計が必要 |
| TPUv1は学習不可能だった | 限定的な構成の可能性と、実用的な汎用学習向け設計であるかは別問題 |
| TPUv2/v3は単に演算器を増やしただけ | 数値形式、累積精度、HBM、分散構成も学習対応に重要だった |
この記事での解釈は、次の通りです。
TPUv1は「学習不可能」だったのではなく、「幅広い深層学習を安定して学習するための汎用的な学習アクセラレータとして最適化された設計ではなかった」と見るのが適切です。
TPUv2で何が変わったのか:bfloat16とfloat32累積
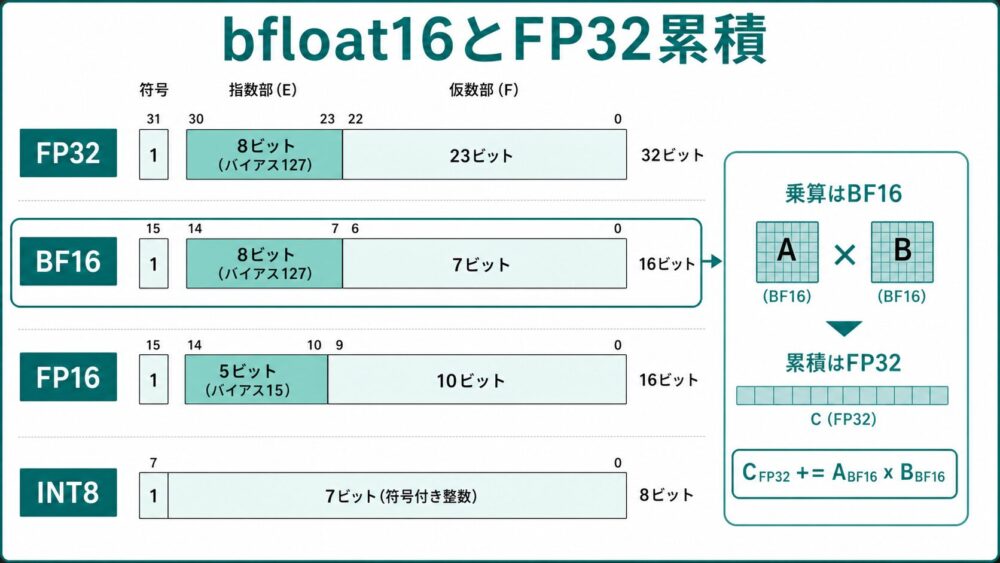
TPUv2で大きく変わった点のひとつが、bfloat16演算とfloat32累積を使うmixed precision(低精度演算と高精度保持を組み合わせる計算方式)です。
Wangらの論文では、TPUv2がbfloat16で計算し、float32で累積するmixed precision trainingをサポートすると説明されています。
Google Cloudのbfloat16公式資料でも、TPUは行列積をbfloat16値で実行し、accumulation(累積)をIEEE float32で行うと説明されています。
行列積の中核は、概念的に次の形です。
\[ C_{\mathrm{FP32}} \mathrel{+}= A_{\mathrm{BF16}} \times B_{\mathrm{BF16}} \]
これは、入力の乗算はbfloat16で高速・省メモリに行い、部分和はfloat32で保持する、という考え方です。
bfloat16、float16、float32、int8の違いを簡単に整理します。
| 数値形式 | ビット幅 | 値域 | 精度 | 学習での見方 |
|---|---|---|---|---|
| float32 | 32-bit | 広い | 高い | 基準となる高精度形式 |
| bfloat16 | 16-bit | float32に近い | float32より粗い | 値域を保ちやすく、学習で扱いやすい |
| float16 | 16-bit | bfloat16より狭い | bfloat16より仮数部は多い | 値域不足に注意が必要で、loss scalingが必要になる場合がある |
| int8 | 8-bit | スケールに依存 | 量子化に依存 | 推論では強いが、学習ではスケール・勾配表現が難しい |
Kalamkarらの論文では、bfloat16はfloat32と同じ指数部幅を持つため、float32に近いdynamic range(表現できる値域)を持つことが学習で有利だと説明されています。
ここで重要なのは、bfloat16が「float32と同じ精度」を持つわけではないことです。
bfloat16は16-bitなので、仮数部はfloat32より少なく、細かい値の表現精度は落ちます。
しかし、指数部の幅がfloat32と同じであるため、非常に小さい値や大きい値を扱う範囲を保ちやすいという特徴があります。
学習で特に重要なのは、この値域です。
勾配やactivationの値は、層、ステップ、モデル構造によって大きく変化します。
値域が狭いと、overflow(値が大きすぎて表現できない)やunderflow(値が小さすぎて0に近づく)が起きやすくなります。
bfloat16は、float16よりも値域を確保しやすいため、学習時の扱いが比較的容易です。
ただし、「bfloat16なら必ずfloat32と同じ学習精度になる」と断定してはいけません。
Kalamkarらの論文は、多数のモデルでbfloat16学習がfloat32と同等の結果を示したと報告していますが、すべてのモデル、すべてのoptimizer、すべての実装で無条件に成立する保証ではありません。
記事内の解釈としては、bfloat16は「学習で必要な値域を保ちつつ、メモリ量とデータ転送量を減らしやすい形式」と捉えるのが適切です。
TPUv2の学習向けハードウェア拡張:HBMと複数チップ構成
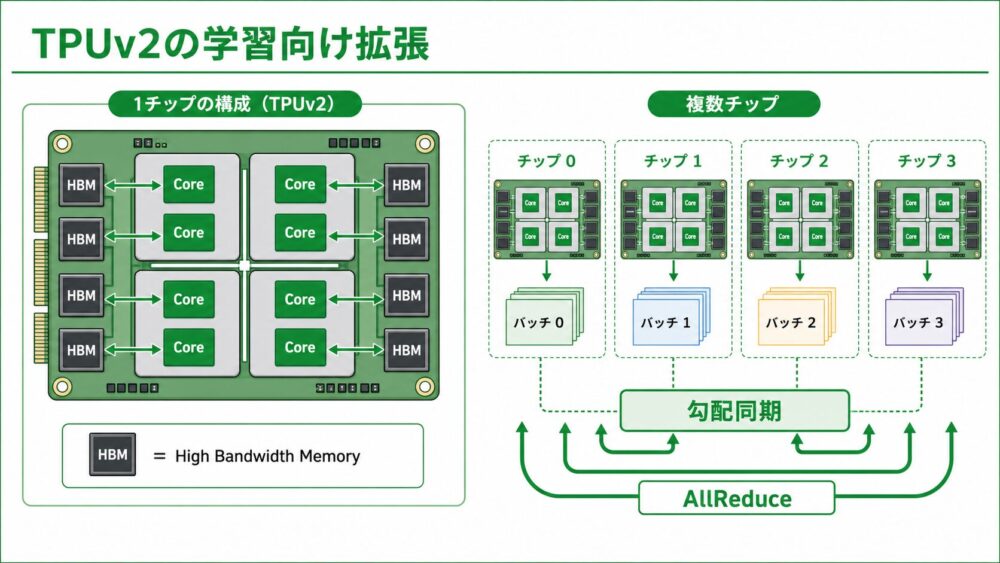
TPUv2では、学習向けにHBMと複数チップ構成が重要になります。
Wangらの論文では、Cloud TPU v2の1 boardは4 TPU packages、合計8 coresで構成され、board全体で180 TFLOPS、64 GBのメモリ、2400 GB/sの総メモリ帯域を持つと整理されています。
1 coreあたりでは8 GBのHBMを持つと説明されています。
Google CloudのTPUv2公式資料では、TPUv2 sliceが512 chipsで構成され、reconfigurable high-speed linksで相互接続されると説明されています。
学習でHBMが重要になる理由は、保持・転送するデータが推論より多いからです。
| 用途 | 主に保持・転送するデータ |
|---|---|
| 推論 | 重み、入力、出力 |
| 学習 | 重み、入力、activation、gradient、weight gradient、optimizer state、一時バッファ |
HBMの「容量」と「帯域」は分けて考える必要があります。
容量は、モデル、activation、勾配、optimizer stateがメモリに収まるかを左右します。
帯域は、それらのデータをMXU(Matrix Multiply Unit、行列積ユニット)やvector unitへ十分な速度で供給できるかを左右します。
演算器のピーク性能が高くても、メモリからデータを供給できなければ性能は出ません。
Wangらの論文でも、TPUの性能がメモリ帯域、inter-chip communication(チップ間通信)、host-device balance(ホストとデバイスのバランス)に影響されることが分析されています。
特に学習では、複数チップでデータ並列を使う場合、各チップが別々のmini-batchを処理し、最後に勾配を同期します。
この勾配同期では、AllReduceのようなcollective communication(複数デバイスが協調して値を集約・配布する通信)が重要になります。
Google CloudのTraining on TPU slicesでも、TPUはTPU Podへスケールアウトするよう設計され、Podは専用の高速ネットワークで接続されたTPUデバイス群だと説明されています。
したがって、TPUv2の学習対応を理解するには、bfloat16/float32累積だけでなく、HBMと複数チップ接続も合わせて見る必要があります。
TPUv3は何を強化したのか
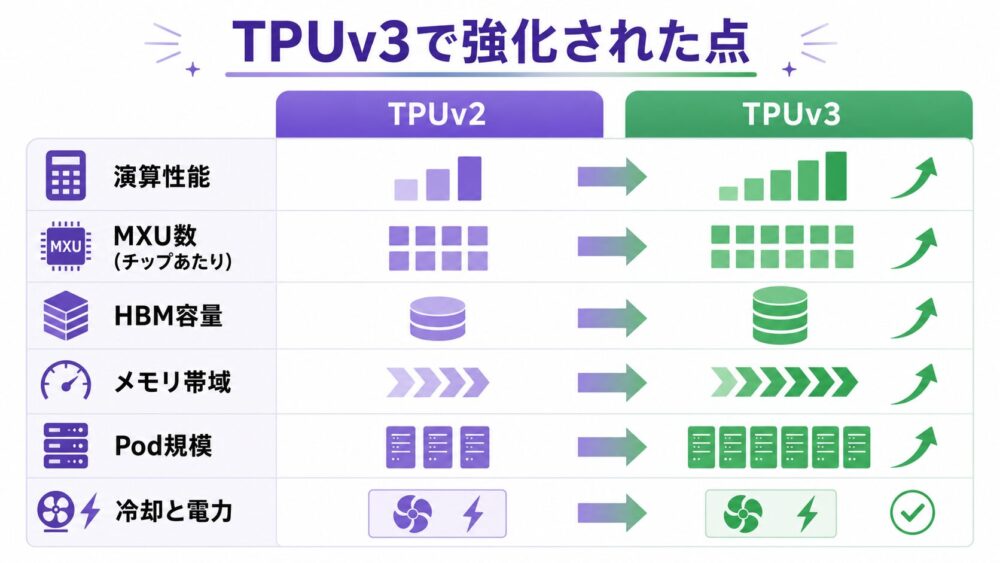
TPUv3は、「初めて学習可能にした世代」というより、TPUv2で確立した学習対応を強化した世代です。
Wangらの論文では、TPUv3はTPUv2と比べてMXU数とHBM容量が増え、ピーク性能が420 TFLOPSに向上したと整理されています。
同論文の表では、TPUv2は8 coresのboardで180 TFLOPS、TPUv3は8 coresで420 TFLOPSとされています。
また、TPUv3のメモリはcoreあたり16 GB、帯域は論文中の実測推定で3600 GB/sとされています。
Google CloudのTPUv3公式資料では、TPUv3 chipは2 TensorCoresを持ち、各TensorCoreは2 MXUs、vector unit、scalar unitを持つと説明されています。
公式仕様では、TPUv3 chipあたり123 TFLOPS(bf16)、32 GiB HBM2、900 GB/s、TPU Pod size 1024 chips、Podあたり126 PFLOPS(bf16)、AllReduce bandwidth 340 TB/s、bisection bandwidth 6.4 TB/sが示されています。
TPUv2とTPUv3の比較を整理します。
| 観点 | TPUv2 | TPUv3 |
|---|---|---|
| 位置づけ | 学習・推論を扱うCloud TPU世代 | TPUv2の学習基盤を強化した世代 |
| 1 board / 8 coresのピーク性能 | 180 TFLOPS | 420 TFLOPS |
| coreあたりHBM容量 | 8 GB | 16 GB |
| board総メモリ帯域 | 2400 GB/s | 3600 GB/s相当とWangらが実測から推定 |
| chipあたり公式仕様 | 公式v2ページは詳細値を簡略化 | 123 TFLOPS、32 GiB HBM2、900 GB/s |
| Pod規模 | v2 sliceは512 chips | v3 Podは1024 chips |
| 分散学習 | 複数チップ構成 | より大きいPod規模、AllReduce bandwidthを公式仕様で提示 |
TPUv3で重要なのは、演算器だけではありません。
より高い演算性能を使うには、HBM容量、HBM帯域、チップ間通信、冷却、電力も支える必要があります。
Google CloudのTPUv3公式資料では、TPUv3の測定電力やPod規模、AllReduce bandwidthが示されており、単体チップ性能だけでなく、システムとしてのスケールが重視されていることが分かります。
ただし、性能比較は単純ではありません。
対象モデル、batch size、activationの大きさ、optimizer、通信量、メモリ律速か計算律速かによって、TPUv2からTPUv3への性能向上幅は変わります。
Wangらの論文でも、TPUv3はcompute-boundなMatMulでは大きな改善が見られる一方、memory-boundな処理ではメモリ帯域やデータ供給の制約が残ることが示唆されています。
TPUv1・v2・v3を「推論と学習の要件」で比較する
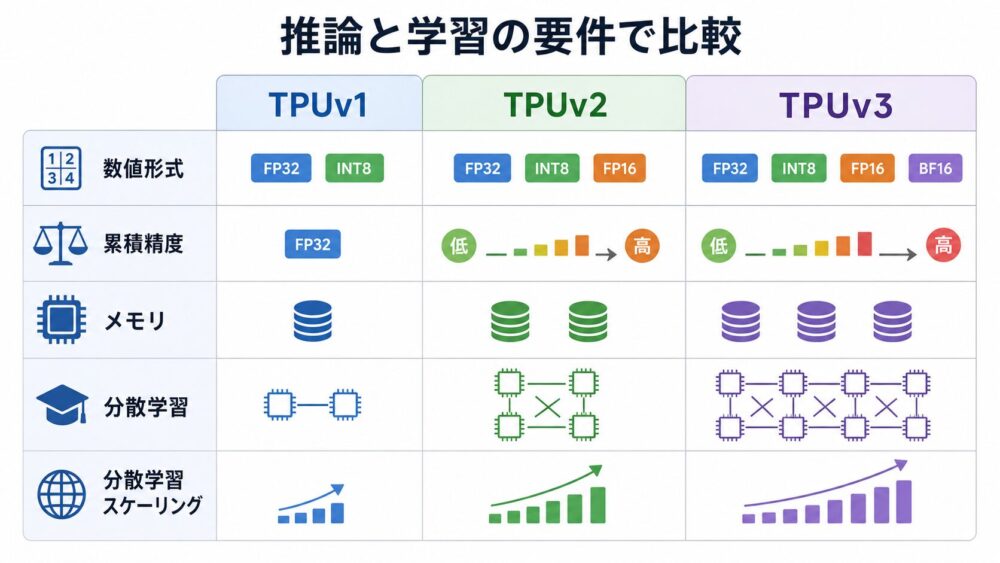
ここまでの内容を、推論と学習の要件で比較します。
| 観点 | TPUv1 | TPUv2 | TPUv3 |
|---|---|---|---|
| 主な設計目的 | データセンター推論の高速化 | 学習・推論を扱うCloud TPU | TPUv2の学習基盤を大規模化・高速化 |
| 主な数値形式 | 8-bit MAC中心 | bfloat16入力の行列演算 | bfloat16入力の行列演算 |
| 累積精度 | int32 accumulator | float32 accumulation | float32 accumulation |
| 推論対応 | 主用途 | 対応 | 対応 |
| 学習対応 | 限定的な構成余地はあるが、主目的ではない | 主要用途として扱いやすい | TPUv2の学習対応を維持しつつ強化 |
| メモリ構成 | 28 MiB on-chip memory、外部DDR3 | HBM、coreあたり8 GB、board全体64 GB | HBM2、chipあたり32 GiB、coreあたり16 GB相当 |
| 分散学習への適性 | 汎用的な大規模分散学習向け設計とは言いにくい | 複数チップ・slice構成で学習を扱う | Pod規模、AllReduce bandwidth、bisection bandwidthを強化 |
| 主な強化点 | 推論向け8-bit行列積と電力効率 | bfloat16、float32累積、HBM、複数チップ | 演算性能、MXU数、HBM容量、帯域、Pod規模 |
結論は明確です。
TPUv1からTPUv2への本質的な変化は、行列積器を速くしたことだけではありません。
学習で必要になる数値表現、累積精度、メモリ容量・帯域、複数チップでの計算を、ハードウェアとシステムの両面で扱えるようにしたことです。
TPUv1は、8-bit行列積を中心に推論を高速化する設計でした。
TPUv2は、学習を現実的な主要用途として扱える構成へ拡張されました。
TPUv3は、その学習基盤をさらに大規模・高性能にした世代です。
GPU・NPU・カメラAIへの示唆
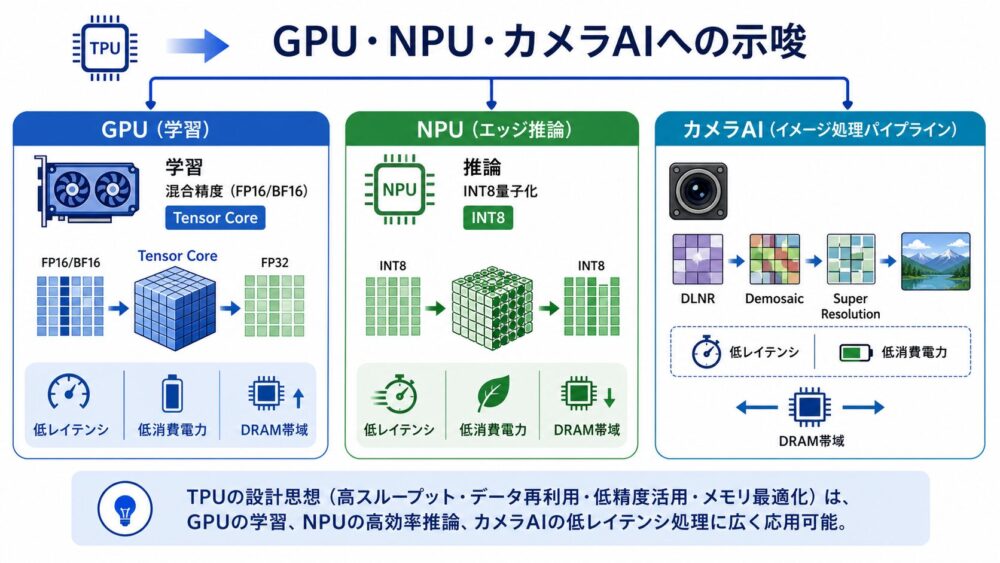
TPUの世代比較は、GPU(Graphics Processing Unit、画像処理由来の並列プロセッサ)、NPU(Neural Processing Unit、ニューラルネットワーク向けアクセラレータ)、カメラAIを考えるときにも参考になります。
ただし、TPUの設計思想を、そのままカメラNPUへ一般化してはいけません。
GPUでは、Tensor Core(NVIDIA GPUの行列積向け演算器)を使ったmixed precision trainingが広く使われます。
たとえばNVIDIA V100では、float16で計算し、float32で累積する構成が使われ、Wangらの論文でもGPU側のmixed precision trainingとして比較されています。
TPUのbfloat16 + float32累積と、GPUのfloat16/bfloat16 + float32累積は、「低精度乗算で演算量とメモリ転送を減らし、累積は高精度に保つ」という方向性では似ています。
一方、NPUやエッジAIでは、推論特化のint8設計が有利になりやすいです。
カメラ内のDLNR(Deep Learning Noise Reduction、深層学習を使うノイズ低減)、Demosaic(カラーフィルタ配列からRGB画像を復元する処理)、Super Resolution(超解像)では、端末内で低レイテンシ、低消費電力、限られたDRAM帯域の中で推論を実行することが重要です。
推論時には、学習済み重みが固定されており、毎フレームの処理時間と電力が強い制約になります。
そのため、int8 quantization(8-bit整数量子化)や、演算子を絞ったNPU設計が有利になる場合があります。
一方、学習環境では、モデル全体のactivation、gradient、optimizer state、checkpoint、複数チップ通信が重要です。
同じニューラルネットワークでも、学習と推論では、必要なハードウェア要件が大きく異なります。
| 用途 | 重視される要件 | 典型的に重要な要素 |
|---|---|---|
| データセンター学習 | スループット、メモリ容量、帯域、分散通信 | HBM、AllReduce、mixed precision、checkpoint |
| データセンター推論 | スループット、レイテンシ、運用効率 | batch処理、低精度推論、メモリ帯域 |
| カメラ内推論 | 低レイテンシ、低消費電力、DRAM帯域、対応演算子 | int8 NPU、オンチップSRAM、ISPとの接続 |
| カメラ向け学習 | 高画質データ、損失関数、長時間学習 | GPU/TPU学習環境、大容量メモリ、分散学習 |
TPUv1、TPUv2、TPUv3の違いから得られる示唆は、「行列積器の速さだけで学習・推論の適性は決まらない」ということです。
どの数値形式で、どの値を、どのメモリに保持し、どの帯域で供給し、複数チップならどう同期するかまで含めて、ハードウェア適性を見る必要があります。
まとめ
TPUv1は、8-bit行列積を中心に推論を高速化する設計でした。
TPUv1でも、行列積器を使って限定的な学習構成を検討する余地はあります。
しかし、幅広い深層学習を安定して学習するための数値形式、メモリ帯域、分散学習を主目的にした構成ではありませんでした。
TPUv2では、bfloat16演算、float32累積、HBM、複数チップ構成を取り込み、学習と推論を対象にしたTPUへ拡張されました。
TPUv3は、その学習向け基盤を、演算性能、メモリ、帯域、分散規模の面で強化した世代です。
「TPUv1は学習不可能だった」と断定するよりも、「TPUv1の設計目的は推論加速であり、実用的な汎用学習アクセラレータとして必要な条件はTPUv2以降で大きく整った」と理解する方が、論文ベースの説明として適切です。
関連技術
| 用語 | 簡単な説明 |
|---|---|
| TPU | Tensor Processing Unit。Googleが開発したニューラルネットワーク向けアクセラレータ |
| NPU | Neural Processing Unit。ニューラルネットワーク処理向けアクセラレータの総称 |
| ASIC | Application-Specific Integrated Circuit。特定用途向けに設計された集積回路 |
| Systolic Array | データを隣接演算器へ規則的に流しながら積和を進める配列構造 |
| Matrix Multiply Unit | 行列積を高速に実行する演算ユニット |
| MAC | Multiply-Accumulate。乗算して結果を累積する基本演算 |
| int8 quantization | 重みやactivationを8-bit整数へ量子化する技術 |
| bfloat16 | 16-bit浮動小数点形式。float32と同じ指数部幅を持ち、値域を確保しやすい |
| mixed precision training | 低精度演算と高精度累積・保持を組み合わせる学習方式 |
| float32 accumulation | 乗算結果の部分和をfloat32で累積すること |
| HBM | High Bandwidth Memory。高帯域のパッケージ近傍メモリ |
| AllReduce | 複数デバイスの値を集約し、結果を各デバイスへ配る通信 |
| distributed training | 複数デバイス・複数ホストで学習を分担する方式 |
| Tensor Core | NVIDIA GPUなどに搭載される行列積向け演算器 |
| GPU training | GPUを使った深層学習。Tensor Coreやmixed precisionが重要になる |
次に読むべき記事
| 記事 | リンク | 補足 |
|---|---|---|
| GPUはなぜ行列積をtile化するのか | GPUの行列積はなぜタイル化するのか?warp・Shared Memory・Tensor Coreから理解する | GPUの行列積、tile化、Tensor Coreを理解する前編 |
| NPUはなぜPE Array内でデータ再利用しやすいのか | NPUはなぜDRAMアクセスを減らしやすいのか?PE ArrayとSystolic ArrayをGPUとの違いから理解する | Systolic Arrayとデータ再利用を理解する後編 |
| bfloat16とfloat16の違い | bfloat16とfloat16の違い(準備中) | TPUv2以降の学習数値形式を深掘りする記事案 |
| mixed precision trainingとは何か | mixed precision trainingとは何か(準備中) | 低精度演算と高精度累積の使い分けを扱う記事案 |
| GPUとNPUの違い | GPUとNPUの違い(準備中) | データセンター学習とエッジ推論の違いへ接続する記事案 |
コメント