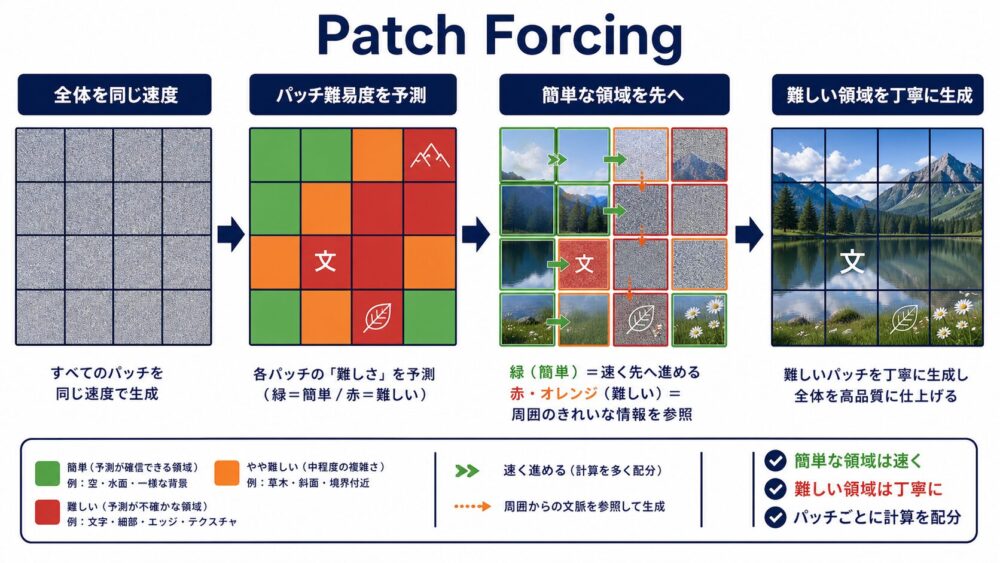
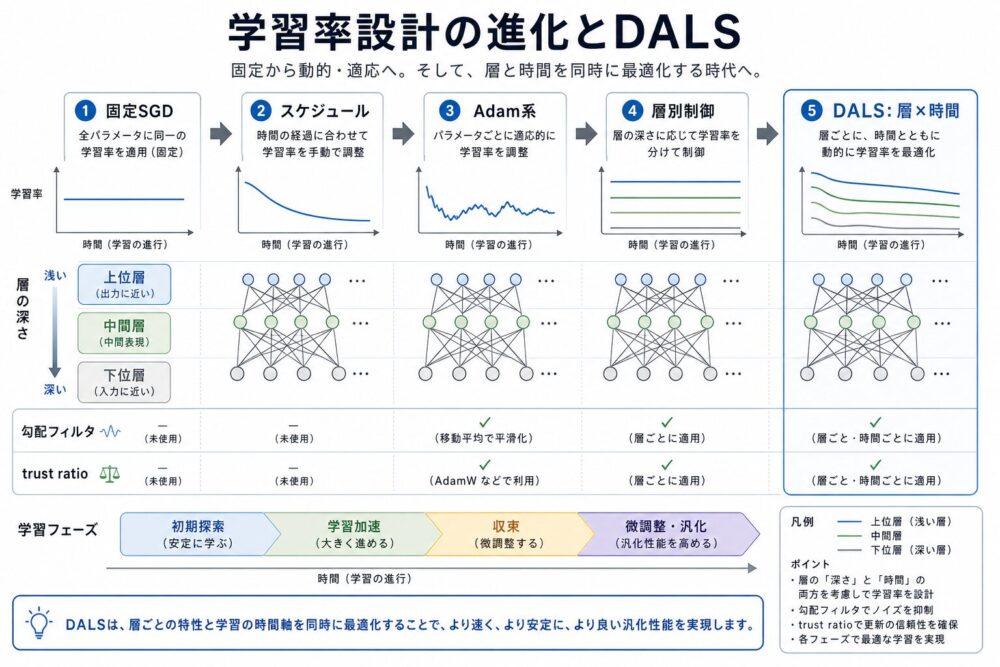
Patch Forcingとは?画像生成をパッチごとの難しさで適応的に進める仕組み
画像生成モデルは通常、背景も文字も細い輪郭も、画像全体を同じノイズレベル、同じ回数で更新します。
しかし、自然画像には簡単に決まる領域と、最後まで曖昧さが残る領域があります。
CVPR 2026論文「Denoising, Fast and Slow」は、パッチごとに生成速度を変え、簡単な領域を先にきれいにして難しい領域の文脈として使うPatch Forcingを提案しています。
3文要約
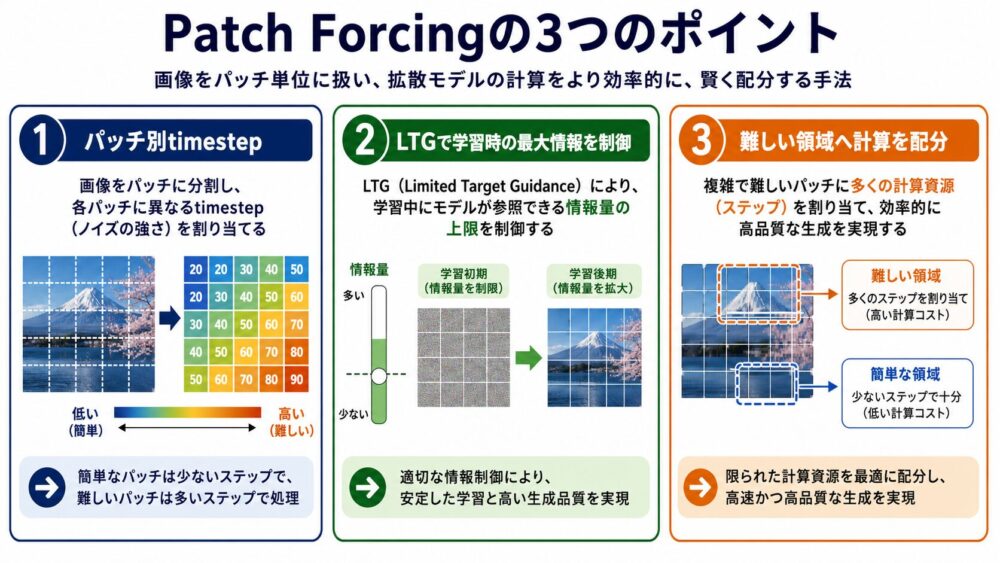
Patch Forcingは、画像を複数のパッチに分け、パッチごとに異なるtimestep(生成途中のノイズ量を表す時刻)を与える画像生成フレームワークです。
学習時にはLTG samplerで1枚の画像に含まれる「最もきれいなパッチ」を制限し、推論開始時には存在しない過剰な文脈をモデルが頼る問題を抑えます。
推論時にはdifficulty head(パッチの生成難易度を予測する小さな出力層)を使い、簡単な領域を先へ進めて難しい領域へ文脈を与えることで、同じNFEでもImageNet生成のFIDを改善しています。
論文情報

| 項目 | 内容 |
|---|---|
| 論文タイトル | Denoising, Fast and Slow: Difficulty-Aware Adaptive Sampling for Image Generation |
| 著者 | Johannes Schusterbauer, Ming Gui, Yusong Li, Pingchuan Ma, Felix Krause, Björn Ommer |
| 研究機関 | CompVis @ LMU Munich, Munich Center for Machine Learning(MCML) |
| 発表年 | 2026年 |
| 採択先 | CVPR 2026 |
| 論文リンク | Denoising, Fast and Slow |
| 公式コード | CompVis/patch-forcing |
本記事の目的
本記事では、Patch Forcingの新規性を次の順番で整理します。
- なぜ画像全体を同じ速度で生成することが非効率なのか
- なぜ単純なパッチ別timestep学習では失敗するのか
- LTG samplerがtrain-test mismatchをどう抑えるのか
- difficulty headが簡単なパッチと難しいパッチをどう分けるのか
- dual-loopとlook-aheadが計算をどう配分するのか
- ImageNetとtext-to-imageで何が改善し、何が未解決なのか
論文の式と実験値を使いますが、初めてFlow Matchingに触れる読者でも流れを追えるように説明します。
背景:画像のすべての領域は同じ難しさではない
](https://kasblo.com/wp-content/uploads/2026/06/spatial-difficulty.jpg)
一般的なDiffusion TransformerやFlow Matchingモデルは、1回の更新で画像内の全パッチに同じtimestepを与えます。
空や壁のような低周波の背景も、細い文字、物体境界、複雑な模様も、同じタイミングで同じ幅だけノイズ除去を進めます。
実装が単純でGPU上の並列計算にも向いていますが、画像の空間的な不均一さを無視しています。
| 領域の例 | 生成難易度の傾向 | 必要になりやすいもの |
|---|---|---|
| 空、壁、単色背景 | 低い | 少ない更新でも大まかな色や形が決まりやすい |
| 大きな物体の内部 | 中程度 | 周囲の形状と整合する文脈 |
| 輪郭、遮蔽境界 | 高い | 両側の物体関係と細かな更新 |
| 小さな文字、指、細線 | 高い | より多い refinementと明確な周辺文脈 |
ここでいうrefinementとは、粗い予測を少しずつ修正して細部を整える処理です。
簡単な背景に必要以上の計算を使う一方、文字や細い構造には十分な更新を与えられない可能性があります。
Patch Forcingの発想は、画像生成を「全員が同じ速さで走る処理」から「得意なパッチは先へ進み、難しいパッチは文脈を受け取りながら丁寧に進む処理」へ変えることです。
Flow Matchingとパッチ別timestep
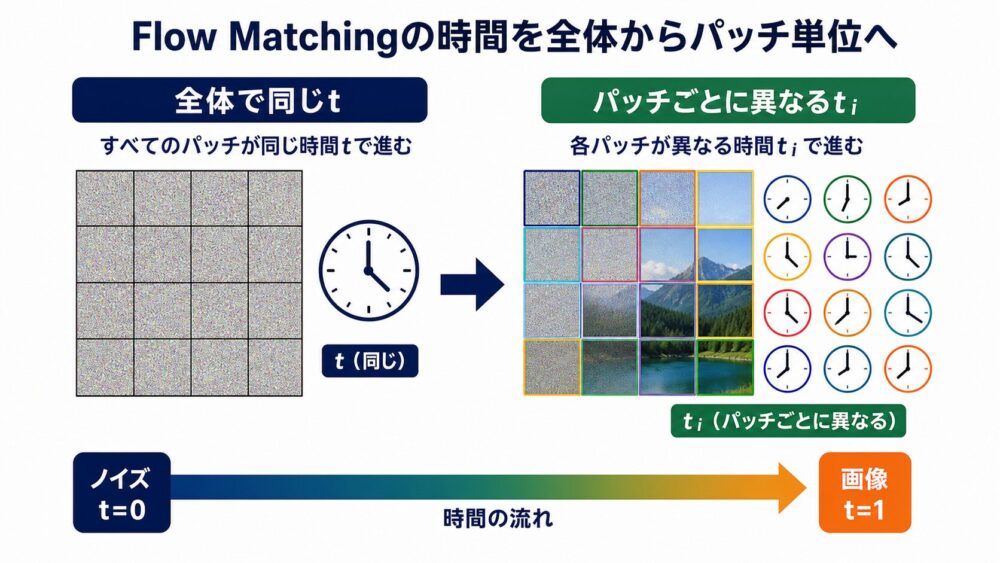
論文はSiTで使われるFlow Matching(ノイズ分布からデータ分布へ連続的に移動するベクトル場を学習する手法)を基盤にしています。
ノイズを \(\mathbf{x}_0\)、実画像を \(\mathbf{x}_1\) とすると、中間状態は次式で表されます。
\[
\mathbf{x}_t = t\mathbf{x}_1 + (1-t)\mathbf{x}_0, \qquad t \in [0, 1]
\]
\(t=0\) は純粋なノイズ、\(t=1\) は実画像です。
モデル \(\mathbf{v}_\theta\) は、ノイズから画像へ向かう速度 \(\mathbf{x}_1-\mathbf{x}_0\) を予測します。
\[
\mathcal{L}_{\mathrm{FM}}
=
\mathbb{E}_{t,\mathbf{x}_0,\mathbf{x}_1}
\left[
\left\|
(\mathbf{x}_1-\mathbf{x}_0)
-\mathbf{v}_\theta(\mathbf{x}_t,t)
\right\|^2
\right]
\]
通常は画像全体に1個の \(t\) を使います。
Patch Forcingでは、画像またはlatent(画像を圧縮した特徴表現)をTransformerのパッチへ分割し、各パッチ \(i\) に異なる \(t_i\) を与えます。
\[
\mathbf{t}
\in
\mathbb{R}^{(H/p)\times(W/p)}
\]
\(H,W\) は画像またはlatentの高さと幅、\(p\) はパッチサイズです。
Diffusion Transformerはtimestep embeddingをAdaLN(timestepなどの条件で正規化パラメータを変える仕組み)へ入力します。
そのスカラー条件をパッチごとの条件へ拡張するため、アーキテクチャ変更は小さく、追加パラメータもdifficulty headを含めて論文では0.01%未満です。
単純なパッチ別学習が失敗する理由

各パッチの \(t_i\) を独立に一様分布から選べばよいように見えます。
\[
t_i \sim \mathcal{U}(0,1)
\]
しかし、パッチ数が増えると、1枚の学習画像には高確率で \(t_i\approx1\) のほぼ完成したパッチが含まれます。
平均timestep \(\bar{t}\) も0.5付近へ集中します。
モデルは、周囲に部分的に完成した領域がある状態で学習しやすくなります。
一方、通常の画像生成は全領域が純粋なノイズに近い状態から始まります。
| 段階 | パッチの状態 | 利用できる文脈 |
|---|---|---|
| 単純な独立timestep学習 | ノイズとほぼ完成したパッチが混在 | 最初から強い文脈がある |
| 実際の推論開始 | 全パッチがほぼ純粋なノイズ | きれいな文脈がない |
この差がtrain-test mismatch(学習時と推論時の入力条件のずれ)です。
Spatial Reasoning Models(SRM)は、平均timestep \(\bar{t}\) を一様にすることでこの問題へ対応しました。
ただし、平均を制御しても、最大timestep \(t_{\max}\) が1に近ければ、ほぼ完成したパッチが残ります。
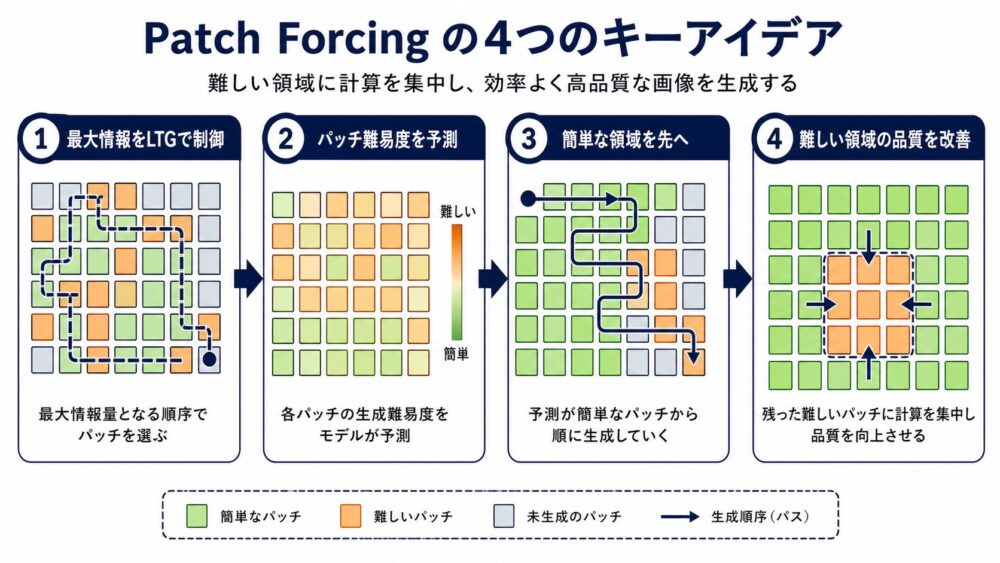
Patch Forcingは「平均的にどれくらい情報があるか」ではなく、「最も情報量の多いパッチがどこまで完成してよいか」を制御します。
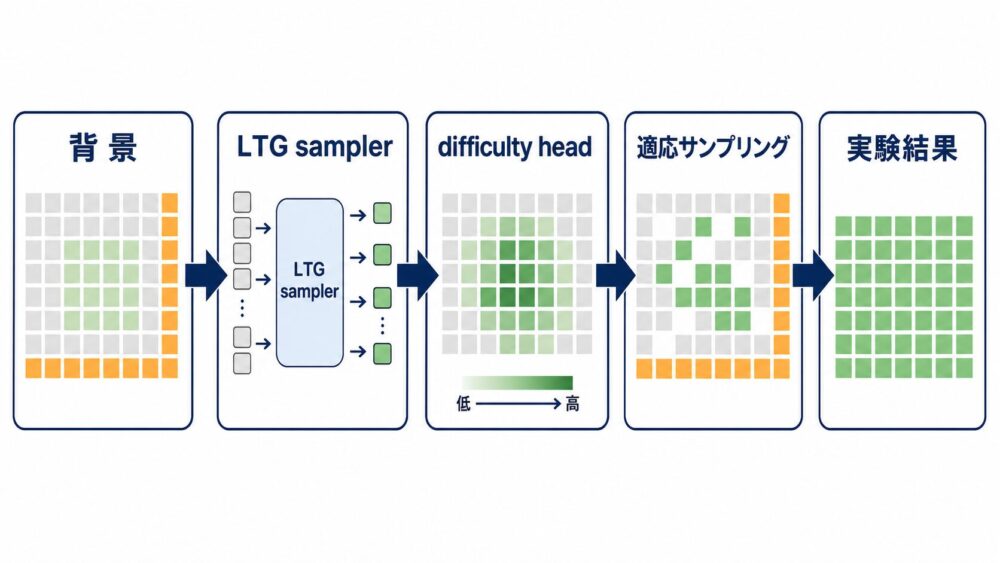
提案手法1:LTG samplerで最大情報量を制御する
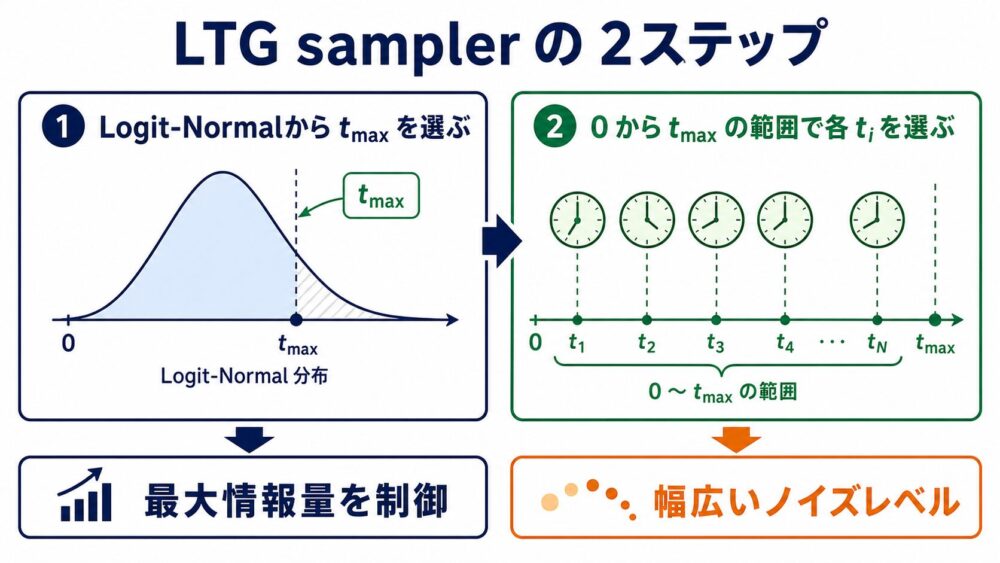
LTGはLogit-Normal Truncated Gaussianの略です。
最初に、1枚の学習サンプルで許可する最大timestep \(t_{\max}\) をLogit-Normal分布から選びます。
\[
t_{\max}
\sim
\mathrm{LogitNorm}(m,s)
\]
次に、各パッチの \(t_i\) を、\(t_{\max}\) を中心とするガウス分布の下半分から選びます。
\[
t_i
\sim
\mathrm{truncate}
\left(
\mathcal{N}(t_{\max},\sigma^2)
\right),
\qquad
0\le t_i\le t_{\max}
\]
この設計には2つの役割があります。
| 工夫 | 解決する問題 |
|---|---|
| \(t_i\le t_{\max}\) に制限 | ほぼ完成したパッチが毎回混ざるcontext leakageを抑える |
| \(t_{\max}\) をLogit-Normalから選択 | 低いtimestepだけに偏らず、幅広いノイズレベルを学習する |
単純なtruncated Gaussianだけでは、timestepが低い側、つまりノイズの多い側へ偏ります。
そこでLogit-Normal分布を組み合わせ、最大情報量を制限しながら、学習するノイズレベルの多様性を確保します。
また、SRMの再帰的な割り当てと異なり、LTGはパッチtimestepを並列に生成できます。
提案手法2:difficulty headで難しいパッチを見つける
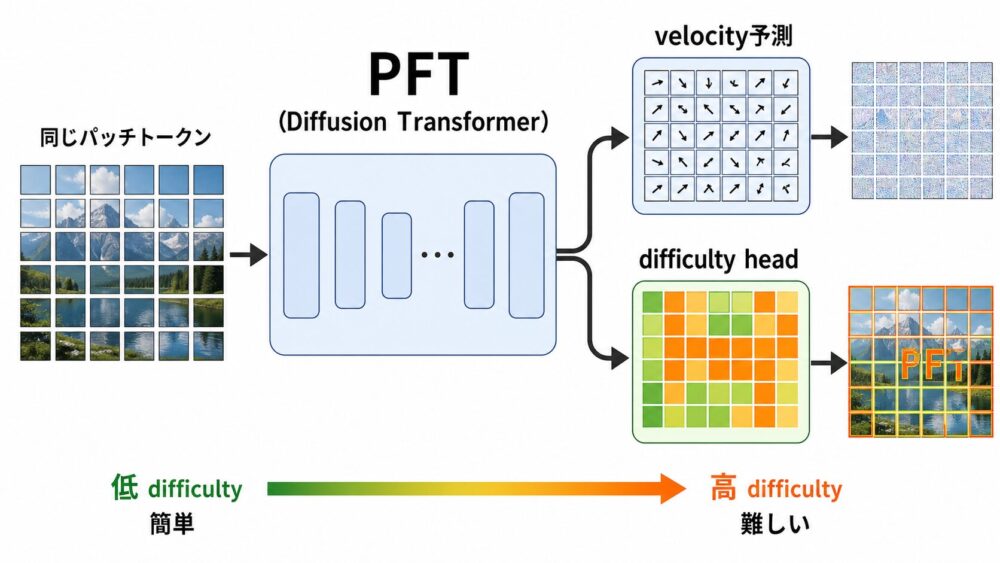
パッチ別timestepで学習できても、推論時にどのパッチを先へ進めるかを決める必要があります。
論文では、モデルのvelocity予測に対する標準偏差 \(\sigma_\theta\) を予測するdifficulty headを追加します。
学習目標は、通常のFlow Matching損失と、正解velocityの負の対数尤度を組み合わせたものです。
\[
\mathcal{L}_{\mathrm{total}}
=
\mathbb{E}
\left[
\left\|
\mathbf{v}_{\mathrm{GT}}
-\mathbf{v}_\theta
\right\|^2
-\lambda
\log
\mathcal{N}
\left(
\mathbf{v}_{\mathrm{GT}}
\mid
\mathrm{sg}(\mathbf{v}_\theta),
\sigma_\theta^2\mathbf{I}
\right)
\right]
\]
\(\mathrm{sg}\) はstop gradient(difficulty head側の損失をvelocity予測へ逆伝播させない操作)です。
論文では \(\lambda=0.01\) を使っています。
著者らは、この値を厳密な確率的不確実性としてではなく、相対的なパッチ難易度として利用しています。
| difficulty予測 | 解釈 | 推論時の扱い |
|---|---|---|
| 低い | velocity予測に自信がある簡単な領域 | 大きく先へ進める |
| 高い | 誤差が大きくなりやすい難しい領域 | 小さなstepで丁寧に更新する |
実験では、予測difficultyと検証誤差に正の相関があり、\(t=0.6\) で相関係数 \(R=0.52\)、ノイズに近い \(t=0.2\) では \(R=0.11\) と報告されています。
生成が進むほど、どこが難しいかを判断しやすくなる結果です。
提案手法3:簡単な領域を文脈として使う適応サンプリング
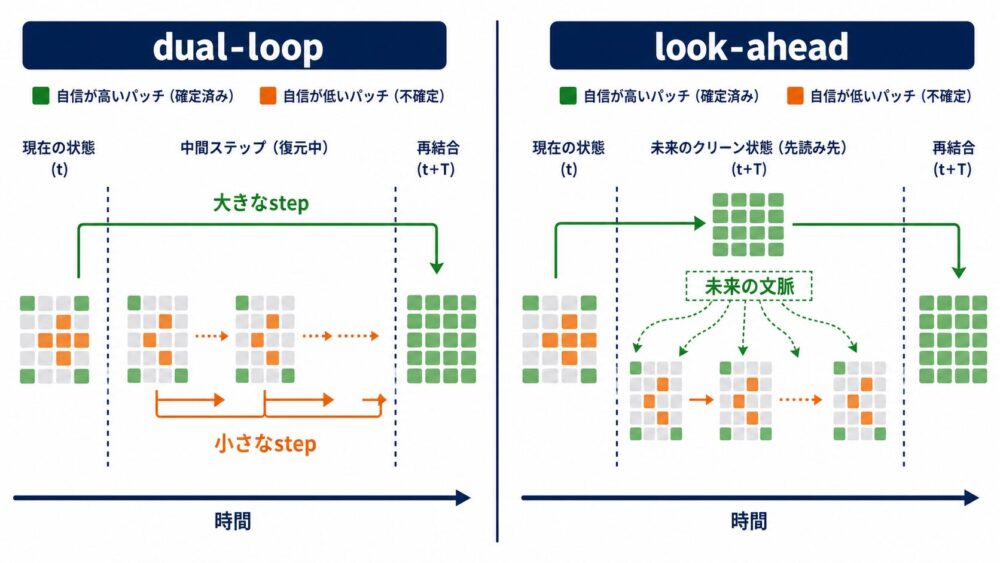
Patch Forcingはdifficulty mapを使い、2種類のサンプラーを提案しています。
dual-loop sampler
dual-loopは、外側と内側の2つの更新ループを使います。
- difficultyが低いパッチを大きなstepで先へ進める
- 先へ進んだパッチを文脈として固定する
- difficultyが高いパッチを小さなstepで複数回refinementする
- 両者のtimestepがそろったらdifficultyを再計算する
難しい領域へ多くの更新回数を配りながら、簡単な領域が作った文脈も使える方式です。
look-ahead sampler
look-aheadは、簡単なパッチを現在時刻より未来、つまりさらに画像に近い状態まで一時的に進めます。
その未来状態を文脈として、同じ時刻に残っている難しいパッチを更新します。
論文では、適切なlook-ahead量は現在のtimestepに比例すると観察しています。
| サンプラー | 簡単なパッチ | 難しいパッチ | 特徴 |
|---|---|---|---|
| parallel Euler | 同じstep | 同じstep | 通常の一斉更新 |
| dual-loop | 大きなstep | 小さなstepを複数回 | 難しい領域のrefinementを重視 |
| look-ahead | 未来状態まで進める | 未来の文脈を参照して更新 | 文脈による曖昧さ低減を重視 |
重要なのは、単にランダムなパッチを先へ進めればよいわけではない点です。
論文のアブレーションでは、予測difficultyに基づく順序がランダム選択より良い結果を示しています。
なぜ先に生成した領域が難しい領域を助けるのか
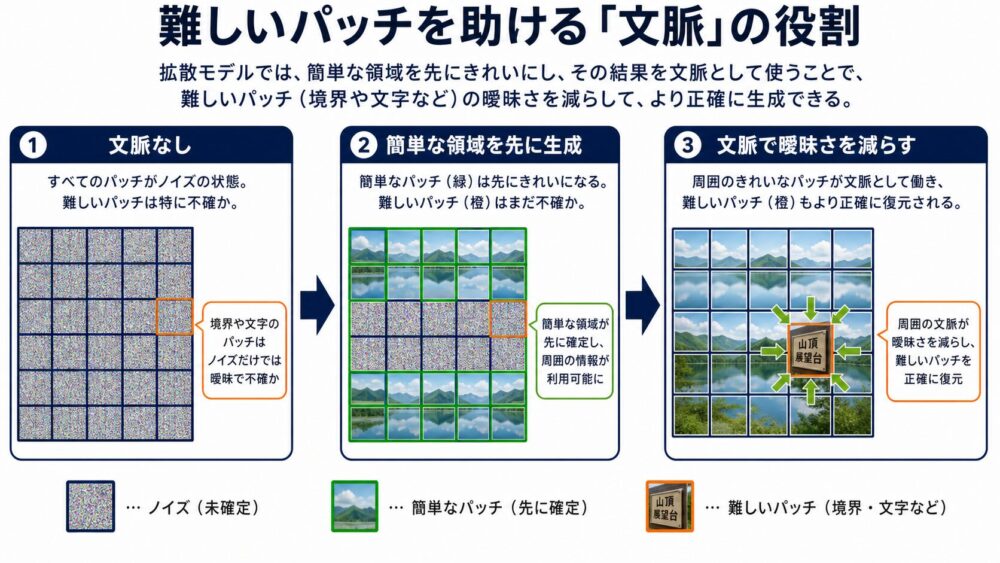
たとえば、鳥の細い脚を生成するとします。
周囲がまだノイズだけなら、脚の位置、向き、背景との境界は曖昧です。
先に鳥の胴体と地面が少し明確になれば、脚がどこから伸び、どこへ接地するかを推定しやすくなります。
Patch Forcingは外部から追加条件を与えるのではなく、モデル自身が先に生成した簡単な領域を内部文脈として再利用します。
論文は、次の3点を実験で確認しています。
| 検証した仮説 | 論文中の観察 |
|---|---|
| 文脈は生成を助ける | 先へ進めたconfident patchを与えると、uncertain regionの検証損失が下がる |
| difficultyは難しさを表す | 予測difficultyが高いパッチほど検証誤差も高い |
| 文脈はdifficultyを下げる | きれいな周辺文脈を与えると、残りの領域の予測difficultyが低下する |
この3点が、適応的な生成順序を設計する根拠になっています。
実験結果:同じモデル規模とNFEでFIDを改善
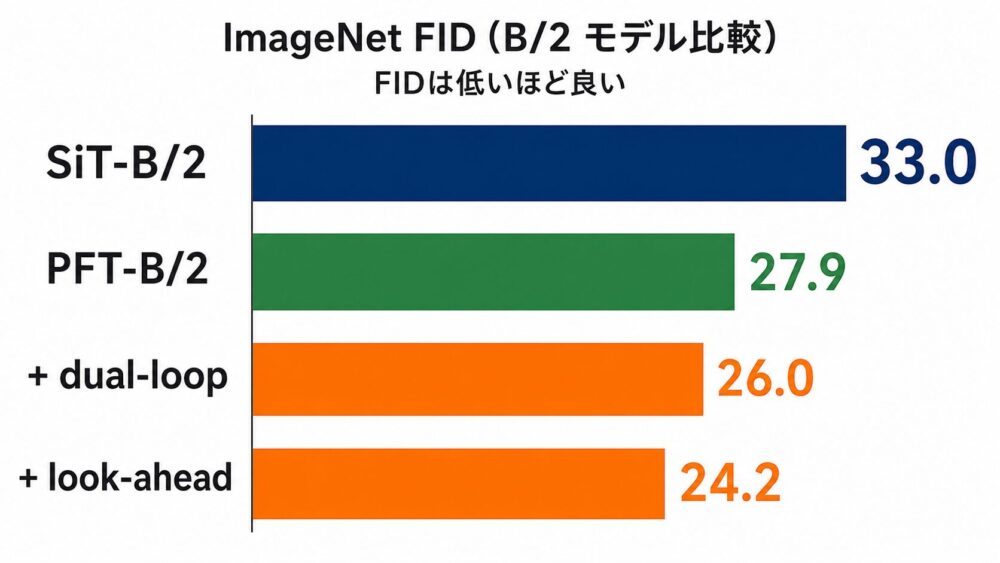
論文はImageNet \(256\times256\) のclass-conditional generation(クラス名を条件にした画像生成)で評価しています。
FIDは低いほど、生成画像の分布が実画像の分布に近いことを表します。
NFEはNumber of Function Evaluationsの略で、生成モデルを何回評価したかを表す計算量の目安です。
| モデル | パラメータ数 | 学習iteration | FID ↓ |
|---|---|---|---|
| SiT-B/2 | 130M | 400K | 33.0 |
| PFT-B/2 | 130M | 400K | 27.9 |
| PFT-B/2 + dual-loop | 130M | 400K | 26.0 |
| PFT-B/2 + look-ahead | 130M | 400K | 24.2 |
| SiT-L/2 | 458M | 400K | 18.8 |
| PFT-L/2 | 458M | 400K | 14.7 |
| PFT-L/2 + dual-loop | 458M | 400K | 13.9 |
| PFT-L/2 + look-ahead | 458M | 400K | 13.0 |
| SiT-XL/2 | 675M | 400K | 17.2 |
| PFT-XL/2 | 675M | 400K | 12.9 |
| PFT-XL/2 + dual-loop | 675M | 400K | 11.5 |
| PFT-XL/2 + look-ahead | 675M | 400K | 9.8 |
まず、適応サンプラーを使わず通常のEuler samplingを行うPFTだけでもSiTを改善しています。
これは、LTG samplerを使ったパッチ別timestep学習自体に効果があることを示します。
さらにdual-loopとlook-aheadを加えるとFIDが下がり、特にlook-aheadが強い結果です。
PFT-XL/2にREPA(中間表現を事前学習表現へ整合させる学習手法)を組み合わせた設定では、FID 6.7を報告しています。
ただし、CFGを使ったstate-of-the-art比較では、PFT-XL/2 + REPA + look-aheadのFIDは2.00で、SiT-XL/2 + REPAの1.96をわずかに下回っています。
一方、sFID、Inception Score、Recallでは競争力のある結果です。
したがって「全指標で既存法を上回った」ではなく、「固定アーキテクチャと計算予算で一貫した改善を示し、REPAやCFGとも組み合わせられる」と読むのが正確です。
Text-to-Imageへの拡張
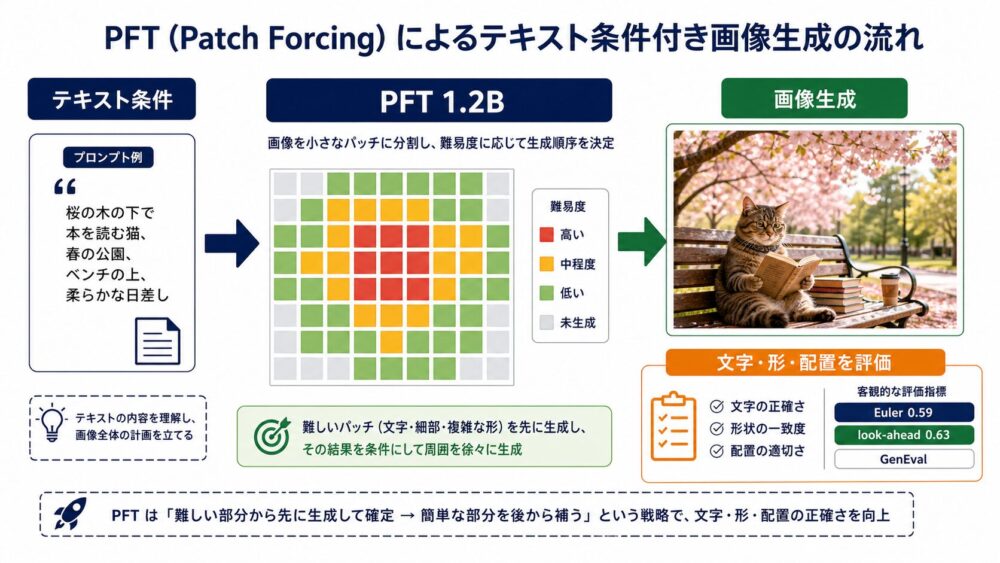
著者らは、1.2B parameterのPFTとQwen3-1.7B text encoderを使い、COYO由来の1.2億image-text pairでtext-to-imageモデルも学習しています。
T2I-CompBench++では、look-aheadが色、形、テクスチャなど複数項目をEuler samplingより改善しています。
GenEvalのoverall scoreは次のとおりです。
| PFT-1.2Bのサンプリング | GenEval Overall ↑ |
|---|---|
| Euler | 0.59 |
| dual-loop | 0.59 |
| look-ahead | 0.63 |
論文は、同一条件の通常Flow Matchingモデルと比べ、PFTで画像内文字が明瞭になる傾向も示しています。
ただし、補足実験ではlook-aheadの文字生成性能がPFTのEulerやdual-loopより弱い場合も報告されています。
未来文脈を固定するlook-aheadは、文字を繰り返し修正する自由度を下げる可能性があるという著者らの解釈です。
よくある誤解
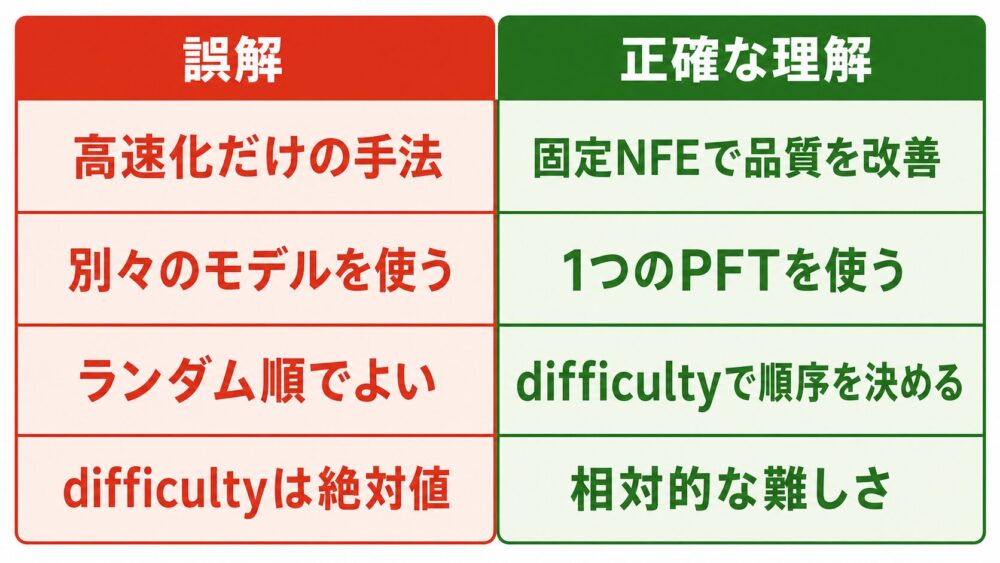
| よくある誤解 | 正確な理解 |
|---|---|
| 簡単な領域をスキップして高速化する手法である | 主目的は同じNFE内で計算を有効に配分し、生成品質を上げること。論文も性能向上向けであり、直接的な高速化手法とは区別している |
| パッチごとに別のモデルを使う | 1つのTransformerへパッチ別timestepを条件として与える |
| 独立にランダムなtimestepを与えればよい | ほぼ完成したパッチが学習時に混ざるため、LTGで最大情報量を制御する必要がある |
| difficultyは厳密な不確実性推定である | 論文では相対的なパッチ生成難易度として利用している |
| look-aheadは常にdual-loopより優れる | ImageNet FIDでは強いが、文字生成など反復修正が重要な対象ではdual-loopが有利な場合がある |
| 既存の高速化技術を置き換える | cachingなどの高速化法とは直交し、組み合わせられる可能性がある |
高画質化タスクへの応用を考える
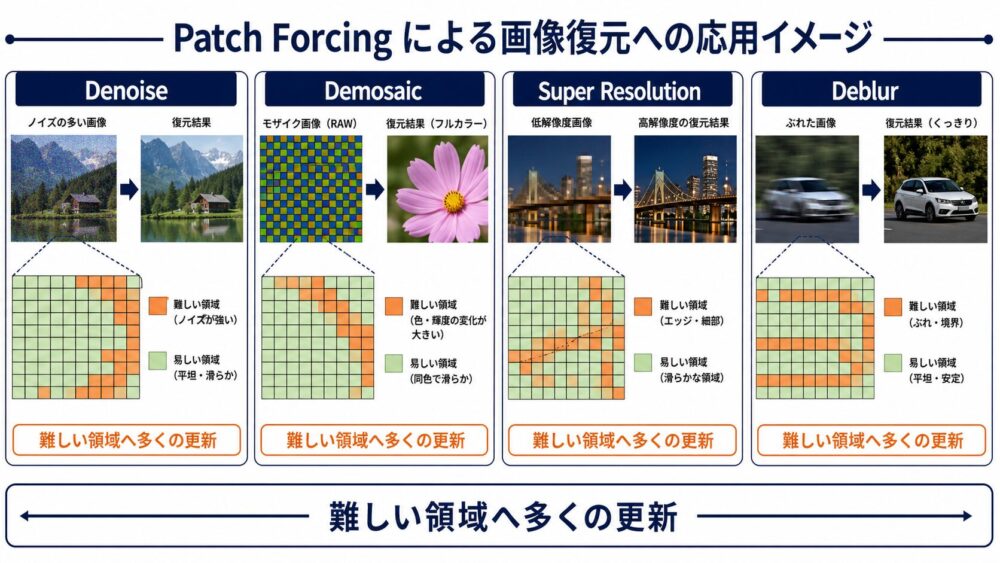
Patch Forcingは画像生成の論文ですが、空間ごとに難易度が違うという前提はDenoise、Demosaic、Super Resolutionにも当てはまります。
| タスク | 簡単になりやすい領域 | 難しくなりやすい領域 | 応用アイデア |
|---|---|---|---|
| Denoise | 平坦部 | 細かなテクスチャ、暗部、輪郭 | 平坦部を先に安定させ、輪郭へ文脈を与える |
| Demosaic | 色変化の少ない領域 | 高周波模様、偽色が出やすい境界 | 難易度に応じて補間更新回数を変える |
| Super Resolution | 大きな面 | 文字、髪、格子、細線 | 低周波構造を先に確定し、高周波復元へ利用する |
| Deblur | 静止背景 | 動体境界、複雑な局所blur | blur推定が難しい領域へ追加更新を配る |
ただし、そのまま移植できるとは限りません。
画像復元では入力画像という強い観測条件があり、領域ごとの難易度は生成モデルとは異なります。
センサノイズ、Bayer配列、レンズ特性など、入力依存のdifficulty設計が必要です。
また、パッチごとに異なる更新状態を持つと、境界の不連続やGPU上の実行効率低下が起きる可能性があります。
スマートフォンやカメラへ搭載する場合は、画質だけでなくlatency、メモリ、電力、実装の分岐コストまで評価する必要があります。
Patch Forcingの課題と今後の展望
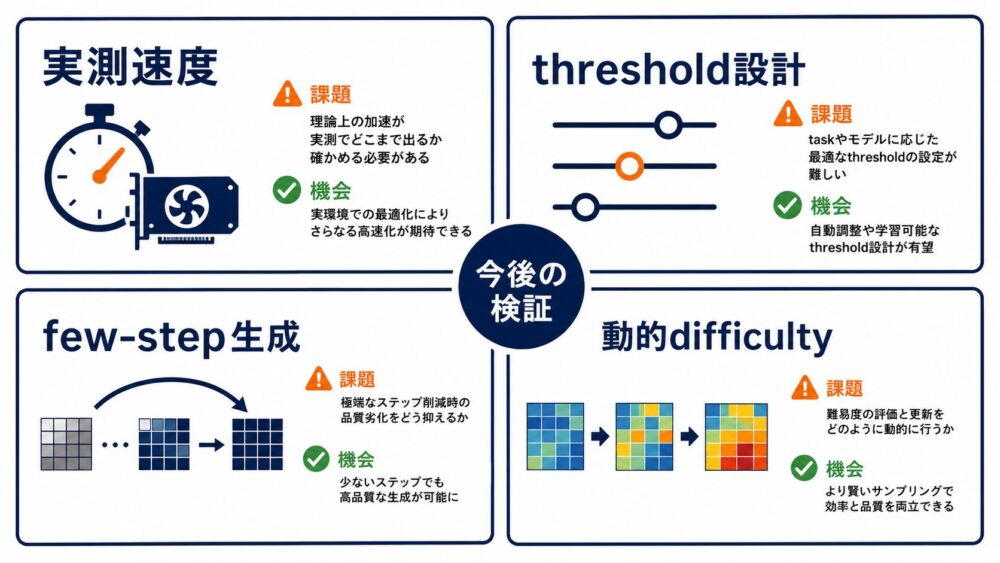
1. NFEが同じでも実測時間が同じとは限らない
論文は主にNFEをそろえて比較しています。
dual-loopやlook-aheadには、difficulty mapの評価、パッチmask、異なるtimestep状態の管理が必要です。
GPUでのwall-clock latencyやメモリアクセス効率は、NFEだけでは分かりません。
2. difficulty thresholdなどの設計が必要
どの割合をconfident patchとして先へ進めるか、inner loopとouter loopを何回にするかで結果が変わります。
補足実験では、confident patchの約40 percentile付近、innerとouterのstep数が比較的均衡した設定が良い傾向です。
3. few-step生成では未検証部分が大きい
論文は、few-stepモデルやdistillation済みモデルへの拡張を今後の方向として挙げています。
大きな時間stepを使うほど適応的な進行が効く可能性がある一方、誤ったdifficulty判断の影響も大きくなると考えられます。
4. 難易度は途中で変わる
初期ノイズからは難しく見えた領域が、周囲の形が決まると簡単になる場合があります。
dual-loopがdifficultyを再計算するのは、この動的な変化へ対応するためです。
固定した難易度mapだけでは十分ではありません。
関連技術
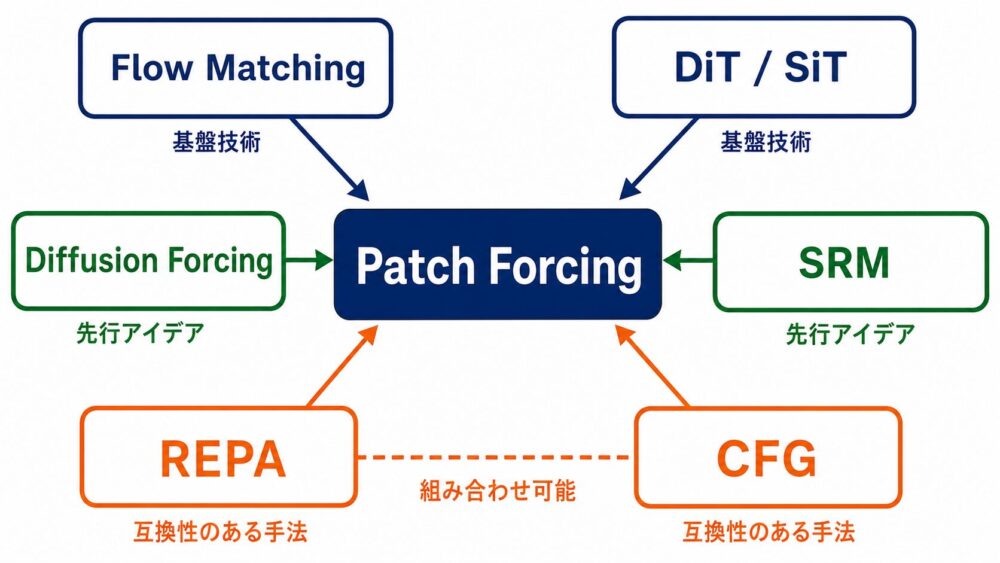
| 技術 | Patch Forcingとの関係 |
|---|---|
| Flow Matching | ノイズからデータへ向かうvelocity fieldを学習する基盤 |
| Diffusion Forcing | 系列要素ごとに異なるノイズレベルを与える考え方 |
| Spatial Reasoning Models | 画像パッチの生成順序と空間推論へDiffusion Forcingを応用 |
| DiT / SiT | パッチtokenとAdaLNを使うTransformer backbone |
| REPA | 中間表現の整合を改善し、Patch Forcingと併用可能 |
| Classifier-Free Guidance | 条件付き生成を強める手法で、Patch Forcingと併用可能 |
| Regional Adaptive Sampling | キャッシュや領域更新で高速化を狙う関連方向。Patch Forcingとは目的が異なる |
Patch Forcingの新しさは、パッチ別ノイズレベルだけではありません。
学習時の最大情報量をLTGで制御し、学習したdifficultyを使って推論順序まで適応させた点にあります。
まとめ
Patch Forcingは、画像生成の計算を空間的に一律配分する前提を見直した手法です。
要点は次の5つです。
- 自然画像には簡単な領域と難しい領域がある
- パッチ別timestepを単純に独立サンプリングするとtrain-test mismatchが起きる
- LTG samplerは最大timestepを制御し、過剰にきれいな文脈への依存を抑える
- difficulty headは更新を多く必要とするパッチを相対的に見つける
- dual-loopとlook-aheadは、簡単な領域を文脈として難しい領域の生成を助ける
ImageNetでは、同じモデル規模とNFEでSiTより低いFIDを示し、通常のPFT、dual-loop、look-aheadの順に改善する傾向が確認されています。
一方で、NFEと実測速度の違い、サンプラーのハイパーパラメータ、few-step生成、文字の反復修正などは今後の検証が必要です。
画像全体を同時にきれいにするだけでなく、「先に決められる場所を文脈にして、迷っている場所へ計算を回す」という考え方は、画像生成と画像復元の両方で発展する可能性があります。
次に読むべき記事
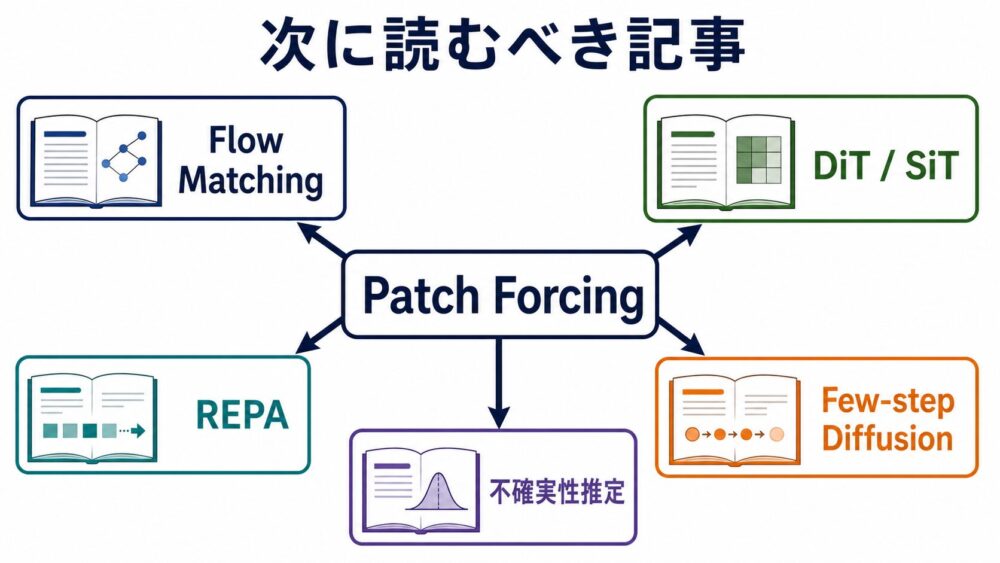
次に読むなら、次のテーマがおすすめです。
- Flow Matchingとは?Diffusionとの違いを数式で理解する
- Diffusion Transformerとは?DiTとSiTの構造を比較する
- REPAとは?画像生成モデルの表現整合を改善する仕組み
- Few-step Diffusionとは?蒸留で画像生成を高速化する方法
- 画像生成モデルの不確実性推定と適応サンプリング
コメント