Decoder-only Transformerとは?GPT系LLMの構造と生成の仕組みを理解する
Decoder-only Transformerは、GPT系LLMでよく使われる自己回帰型のTransformer構造です。
3文要約
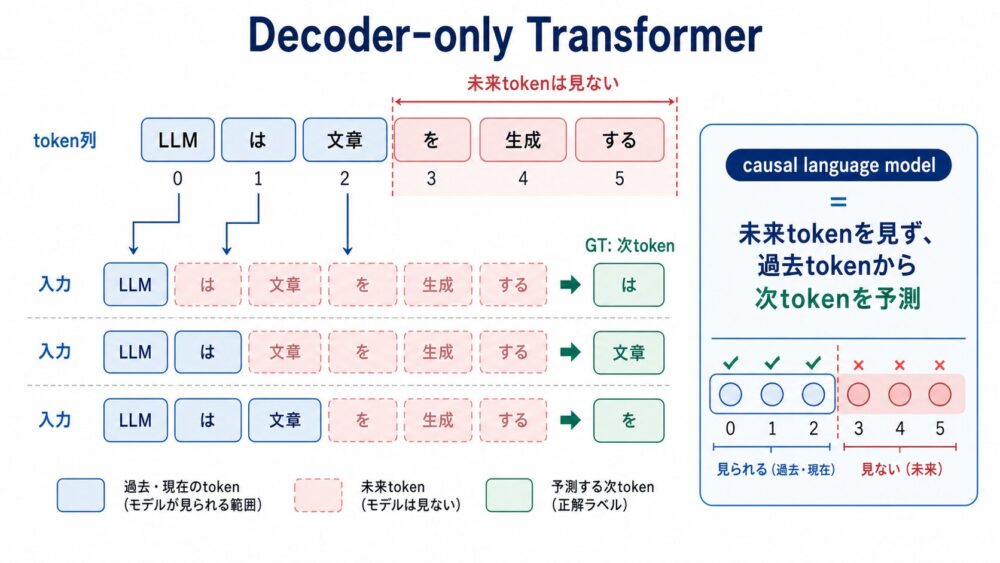
Decoder-only Transformerは、過去のtokenだけを見て次のtokenを予測するように設計されたTransformerです。
GPT-2論文「Language Models are Unsupervised Multitask Learners」では、大規模なWebTextで次token予測を行うだけで、翻訳・要約・質問応答など複数タスクのゼロショット性能が現れることを検証しました。
この構造を理解すると、ChatGPTのような生成AIが「左から右へ文章を伸ばす」理由、causal mask(未来のtokenを見ないためのマスク)、KV Cache(過去のKey/Valueを再利用する推論高速化)の意味がつながります。
論文情報
| 項目 | 内容 |
|---|---|
| 論文タイトル | Language Models are Unsupervised Multitask Learners |
| 著者 | Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever |
| 公開年 | 2019年 |
| 研究機関 | OpenAI |
| 論文リンク | Language Models are Unsupervised Multitask Learners |
| 公式コード | openai/gpt-2 |
| 関連論文 | Attention Is All You Need |
Decoder-only Transformerとは何か
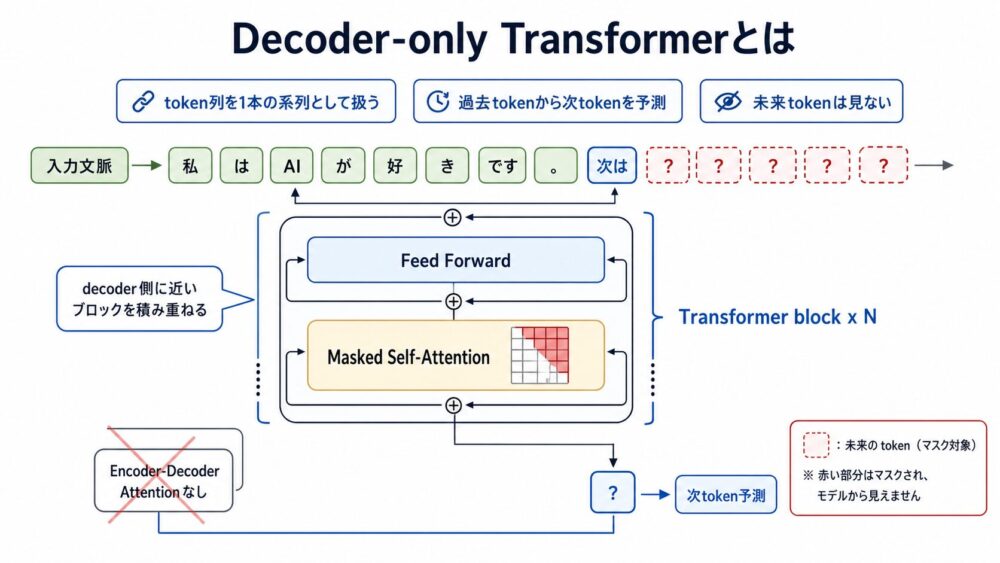
先ほどのPositional Encoding編では、Self-Attentionが語順を扱うために位置情報を必要とすることを整理しました。
今回は、そのSelf-Attentionを使ってGPT系LLMを作るときの代表的な構造であるDecoder-only Transformerを見ていきます。
Decoder-only Transformerとは、Transformerのdecoder側に近いブロックだけを積み重ね、次のtokenを予測する自己回帰型言語モデル(過去の出力を条件に次を生成するモデル)として使う構造です。
ここでいう「decoder」は、元のTransformer論文に出てくる翻訳用decoderと完全に同じではありません。
元のTransformer decoderには、主に次の3要素があります。
| 要素 | 元のTransformer decoder | GPT系Decoder-onlyでの扱い |
|---|---|---|
| Masked Self-Attention | 使う | 使う |
| Encoder-Decoder Attention | encoder出力を見る | 使わない |
| Feed Forward Network | 使う | 使う |
GPT系モデルでは、入力文をencoderで別に読んでからdecoderが参照する構成ではありません。
token列を1本の系列として受け取り、各位置で「それ以前のtoken」だけを見て次のtokenを予測します。
そのため、より正確には「causal language model向けのTransformer stack」と見ると理解しやすいです。
補足:ここでいうTransformer stackとは、Self-AttentionやFeed Forward Networkを含むTransformer blockを何層も重ねた部分です。causal language model(未来tokenを見ず、過去tokenから次tokenを予測する言語モデル)とは、各位置の予測で右側のtokenを使わない言語モデルを指します。たとえば
LLM は 文章までを入力として、次にをが来る確率を高くするように学習します。
なぜGPT系LLMはDecoder-onlyを使うのか
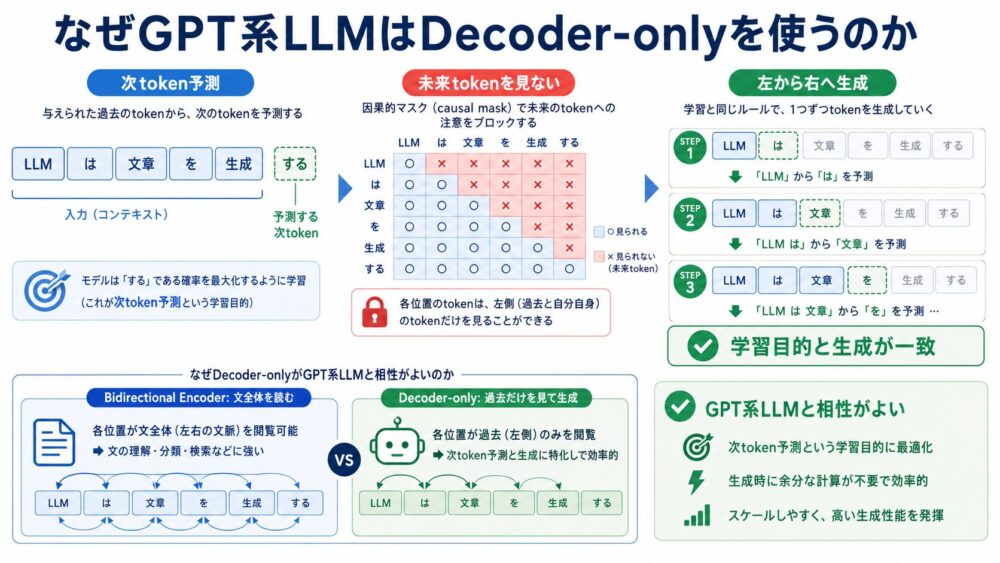
GPT系LLMの中心にある目的は、次のtokenを予測することです。
文脈を $u = (u_1, u_2, \ldots, u_n)$ とすると、言語モデルは次のような確率を最大化するように学習します。
\[
P(u) = \prod_{i=1}^{n} P(u_i \mid u_1, \ldots, u_{i-1})
\]
つまり、文章全体の確率を「これまでのtokenから次のtokenが出る確率」の積として扱います。
この目的関数では、位置 $i$ の予測で未来のtoken $u_{i+1}, u_{i+2}, \ldots$ を見てはいけません。
もし未来を見てしまうと、学習時だけ答えをカンニングしている状態になり、生成時の条件とズレます。
そこでDecoder-only Transformerでは、causal maskを使って未来方向のAttentionを遮断します。
| 観点 | Bidirectional Encoder | Decoder-only |
|---|---|---|
| 代表例 | BERT系 | GPT系 |
| Attentionで見る範囲 | 左右両方向 | 過去方向のみ |
| 得意な使い方 | 文理解、分類、検索、穴埋め | 文章生成、対話、補完 |
| 学習目的の例 | Masked Language Modeling | Next Token Prediction |
| 生成との相性 | 追加設計が必要 | そのまま逐次生成しやすい |
BERTのようなencoder型モデルは、文全体を双方向に見て表現を作れます。
一方で、GPT系のDecoder-onlyモデルは、左から右へtokenを増やす生成タスクと学習目的が自然に一致します。
この一致が、Decoder-only Transformerが生成AIの中心構造になった大きな理由です。
GPT-2論文の主張
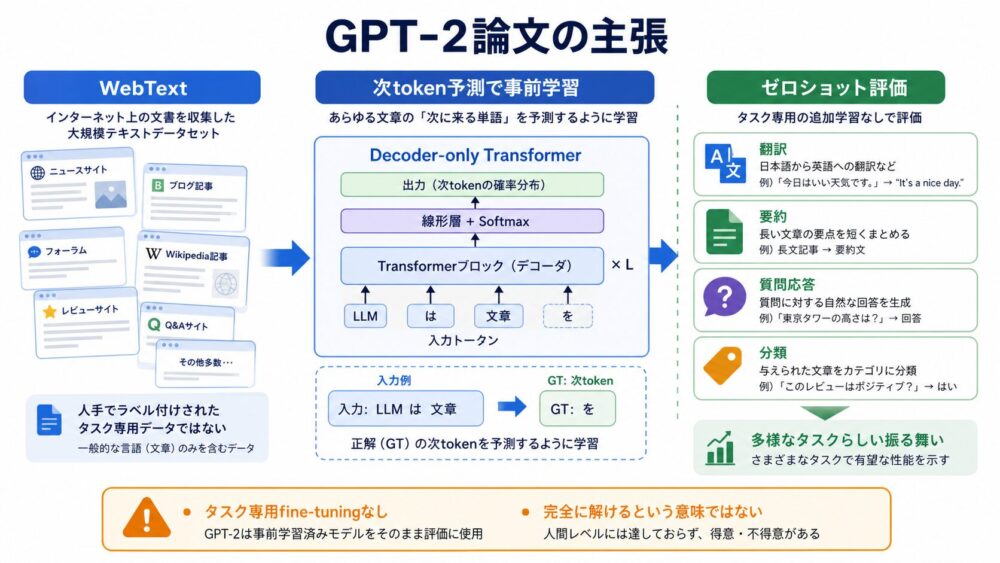
GPT-2論文の主な主張は、十分に大きく多様なテキストで言語モデルを学習すると、明示的なタスク別教師データがなくても複数タスクをある程度こなせる可能性がある、というものです。
論文では、WebTextというデータセットを作り、約45 millionのリンクから抽出したWebページをもとに学習データを構築しています。
このデータセットは、Redditで一定以上評価されたリンクを起点にしており、約8 million documents、約40GBのテキストとして説明されています。
WebTextは、分類ラベルや質問応答ペアのようなタスク別GT(Ground Truth、学習で正解として扱う値)を人手で付けるためのデータセットではありません。
目的は、Web文書をtoken列として読み込み、各位置で「次に来るtoken」をGTとして自己教師あり学習(データ自身から正解を作る学習)することです。
たとえば、LLM は 文章 を 生成 というtoken列がある場合、位置ごとの入力とGTは次のように作れます。
| 学習位置 | モデルへの入力 | GTとして予測したい次token |
|---|---|---|
| 1 | LLM |
は |
| 2 | LLM は |
文章 |
| 3 | LLM は 文章 |
を |
| 4 | LLM は 文章 を |
生成 |
つまりWebTextは、「特定のタスク精度を直接最大化するデータセット」というより、多様なWeb文書の続きを予測する汎用言語モデルの精度を上げるための事前学習データです。
その結果として、文中に含まれる質問応答、要約、翻訳、分類のような形式をモデルが学習し、ゼロショット評価でタスクらしい振る舞いが観察されます。
論文では、最大モデルGPT-2を1.5B parameterのTransformerとして扱い、ゼロショット設定(タスク専用の追加学習なし)で複数の言語処理ベンチマークを評価しました。
ただし、ここで注意したいのは「次token予測だけであらゆるタスクが完全に解ける」と主張しているわけではない点です。
論文が示しているのは、大規模な自己回帰言語モデルが、入力文に含まれる自然言語の指示や例から、タスクらしい振る舞いを引き出せる可能性です。
| 論文で重要な点 | 何が示されたか | 読むときの注意 |
|---|---|---|
| WebText | 多様なWeb文書で言語モデルを学習 | Web由来の偏りや重複リスクがある |
| Zero-shot評価 | タスク別fine-tuningなしで評価 | supervised専用モデルに常に勝つわけではない |
| モデル拡大 | パラメータ数を増やすほど性能が伸びる傾向 | 計算資源とデータ品質が重要 |
| Decoder-only構造 | 次token予測と生成が直結 | 文理解専用の双方向encoderとは性質が違う |
GPT-2論文は、現代のLLMを理解するうえで「大規模事前学習」「自己回帰生成」「プロンプトによるタスク指定」の出発点として重要です。
GPT-2のアーキテクチャ
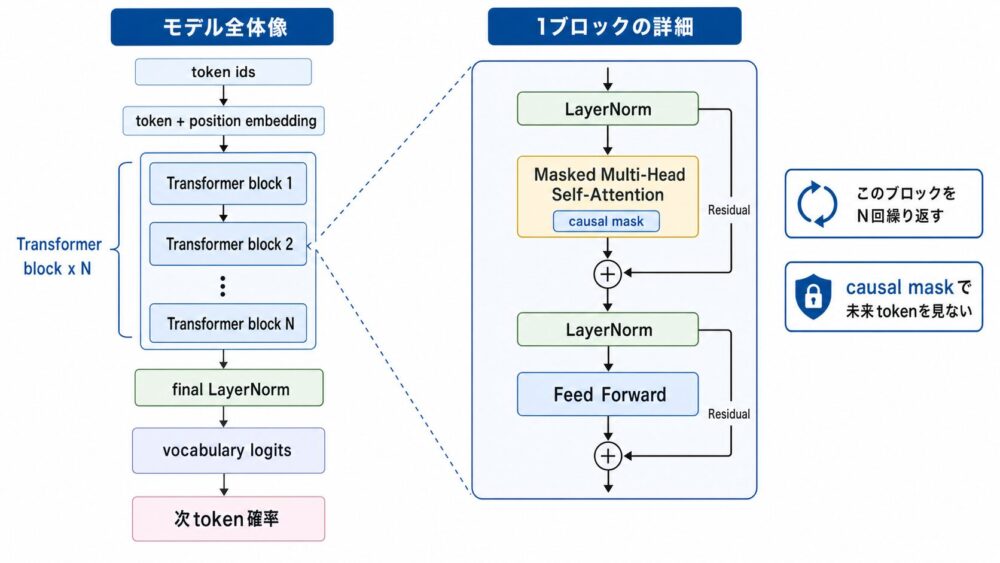
GPT-2は、TransformerをベースにしたDecoder-only言語モデルです。
論文と公式実装から見ると、基本的な流れは次のように整理できます。
token ids
-> token embedding + positional embedding
-> Transformer block x N
-> LayerNorm
-> masked multi-head self-attention
-> residual connection
-> LayerNorm
-> feed forward network
-> residual connection
-> final LayerNorm
-> vocabulary logits
-> next token distributionGPT-2では、Layer Normalization(層ごとに表現のスケールを整える正規化)を各sub-blockの入力側へ移動し、最後に追加のLayerNormを入れています。
これは、深いTransformerを安定して学習するための設計です。
また、残差経路に値が積み上がることを考慮した初期化も使われています。
| GPT-2の設計 | 役割 |
|---|---|
| byte-level BPE | 未知語を減らし、多様な文字列を扱いやすくする |
| learned positional embedding | token位置の情報を入力表現へ加える |
| masked multi-head self-attention | 過去tokenだけを見て文脈を集約する |
| feed forward network | 各位置の表現を非線形に変換する |
| residual connection | 深い層でも勾配と情報を流しやすくする |
| pre-LayerNormに近い配置 | 深いモデルの学習安定性を上げる |
モデルサイズは複数用意されており、層数、隠れ次元、head数を増やしてスケールさせています。
| モデル | 層数 | 隠れ次元 | Attention head数 | 文脈長 |
|---|---|---|---|---|
| small | 12 | 768 | 12 | 1024 |
| medium | 24 | 1024 | 16 | 1024 |
| large | 36 | 1280 | 20 | 1024 |
| XL | 48 | 1600 | 25 | 1024 |
ここでの文脈長1024は、モデルが一度に扱うtoken列の長さです。
現在のLLMではより長いcontext window(入力として保持できる文脈長)が一般的ですが、基本構造はこのDecoder-onlyの考え方からつながっています。
causal maskの仕組み
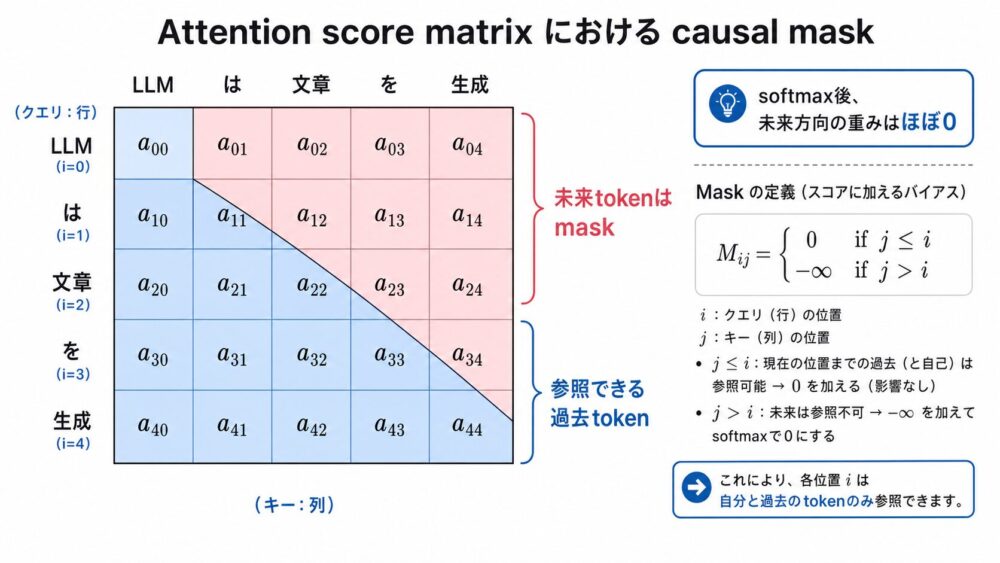
Decoder-only Transformerの中心は、未来tokenを見ないようにするcausal maskです。
たとえば、入力が次のようなtoken列だとします。
LLM は 文章 を 生成 する位置ごとに見てよい範囲は次のようになります。
| 予測位置 | 見てよいtoken | 見てはいけないtoken |
|---|---|---|
LLM の位置 |
LLM |
は 文章 を 生成 する |
は の位置 |
LLM は |
文章 を 生成 する |
文章 の位置 |
LLM は 文章 |
を 生成 する |
生成 の位置 |
LLM は 文章 を 生成 |
する |
Attention scoreを行列で表すと、未来側の上三角部分をマスクします。
\[
\mathrm{Attention}(Q, K, V) =
\mathrm{softmax}\left(
\frac{QK^{\mathrm{T}} + M}{\sqrt{d_k}}
\right)V
\]$M$ はmask行列です。
未来tokenに対応する位置には非常に小さい値を入れ、softmax後の確率がほぼ0になるようにします。
\[
M_{ij} =
\begin{cases}
0 & j \le i \\
-\infty & j > i
\end{cases}
\]
この制約により、学習時には全token位置を並列に計算しながら、各位置の予測条件だけは自己回帰生成と同じにできます。
ここが重要です。
Decoder-only Transformerは、生成時には1 tokenずつ出力しますが、学習時にはcausal maskのおかげで複数位置の次token予測をまとめて計算できます。
Encoder-Decoderとの違い
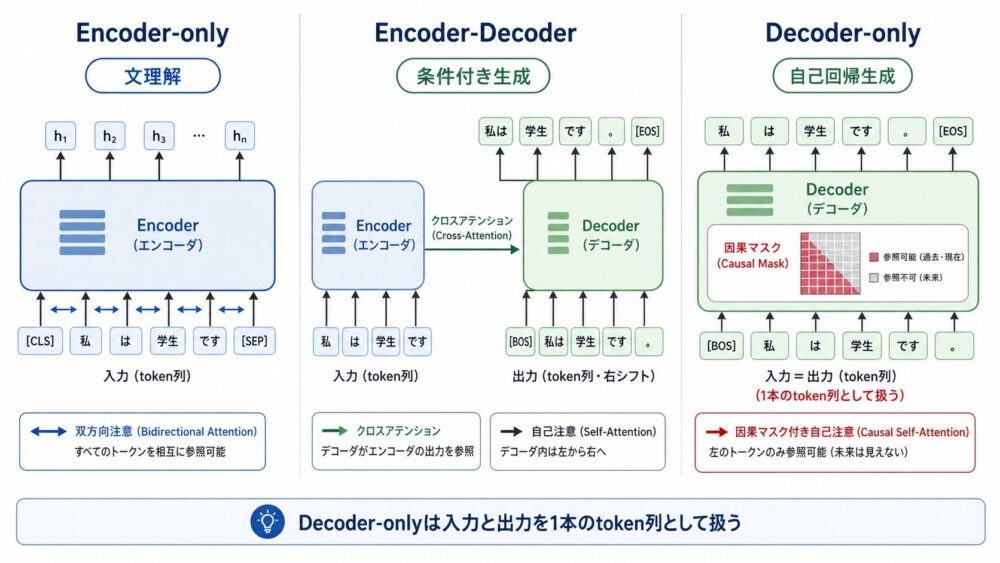
Decoder-onlyを理解するには、Encoder-Decoder Transformerとの違いを見るのが近道です。
| 構造 | 入力の読み方 | 出力の作り方 | 主な用途 | 強み | 注意点 |
|---|---|---|---|---|---|
| Encoder-only | 入力全体を双方向に読む | 分類・埋め込みなど | 検索、分類、文理解 | 文全体の表現が強い | 自然な逐次生成には向きにくい |
| Encoder-Decoder | encoderで入力を読み、decoderで出力 | 条件付き生成 | 翻訳、要約 | 入力と出力を分けやすい | 構造がやや複雑 |
| Decoder-only | 1本の系列を過去方向だけ読む | 次tokenを逐次生成 | 対話、補完、文章生成 | 学習目的と生成が直結 | 入力理解も生成形式で扱う |
Encoder-Decoderは、翻訳のように「入力文」と「出力文」が明確に分かれるタスクに向いています。
たとえば英語文をencoderに入れ、日本語訳をdecoderが生成する構成です。
一方でDecoder-onlyでは、入力指示、文脈、回答をすべて1本のtoken列として扱えます。
User: Decoder-only Transformerとは何ですか?
Assistant: Decoder-only Transformerは...このように、対話形式でも「これまでの全tokenを条件に次tokenを予測する」問題へ落とし込めます。
これが、プロンプト入力と文章生成を同じ枠組みで扱える理由です。
GPT-2が示した「教師なしマルチタスク」の見方
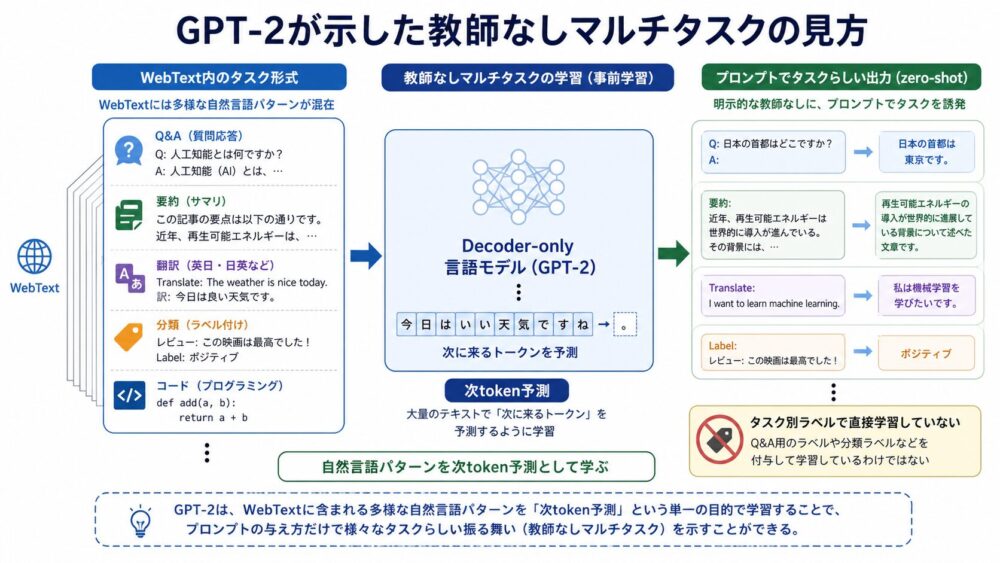
GPT-2論文のタイトルには、Unsupervised Multitask Learnersという表現があります。
ここでいうunsupervised(教師なし)は、タスクごとのラベル付きデータで直接学習していない、という意味です。
ただし、WebTextには自然言語の中に多くのタスク形式が含まれています。
質問と回答、記事と要約、翻訳例、コード断片、箇条書き、レビュー文などです。
Decoder-only言語モデルは、それらをすべて「次のtokenを当てる」問題として学習します。
すると、入力プロンプトにタスクの形式を与えたとき、学習中に見た自然言語パターンを使って、タスクらしい出力を続けられる可能性があります。
| タスク | Decoder-onlyでの見方 |
|---|---|
| 質問応答 | 質問文の後に回答文が続く確率を高くする |
| 要約 | 長文と「要約:」の後に短い説明が続く確率を高くする |
| 翻訳 | 原文と翻訳指示の後に訳文が続く確率を高くする |
| 分類 | 入力文とラベル候補の後に適切なラベルが続く確率を高くする |
この見方は、GPT-3以降のfew-shot prompting(少数例をプロンプトに含める使い方)やinstruction tuning(指示に従うように追加学習する手法)へつながります。
ただし、GPT-2論文の時点では、現在のChatGPTのように人間の指示へ安全かつ一貫して従うためのRLHF(人間の好みに基づく強化学習)やInstruction Tuningが中心ではありません。
GPT-2は、あくまで自己回帰言語モデルのスケーリングにより、タスク非依存の性能がどこまで現れるかを調べた研究として読むのが自然です。
実装者視点:最小のcausal self-attention
Decoder-only Transformerの雰囲気をつかむために、PyTorchでcausal mask付きSelf-Attentionの最小例を見てみます。
以下は教育用の簡略実装です。
実際のLLM実装では、KV Cache、FlashAttention、mixed precision、tensor parallelismなどを考慮します。
import logging
import math
from typing import Optional
import torch
from torch import Tensor, nn
logger = logging.getLogger(__name__)
class CausalSelfAttention(nn.Module):
"""Minimal causal self-attention for a decoder-only Transformer block.
Args:
hidden_size: Width of token representations.
num_heads: Number of attention heads.
dropout: Dropout probability applied to attention weights.
Returns:
This module returns a tensor with shape `(batch, sequence_length, hidden_size)`
from its `forward` method.
Raises:
ValueError: If `hidden_size` is not divisible by `num_heads`.
ValueError: If the input tensor rank is not 3.
Example:
>>> layer = CausalSelfAttention(hidden_size=32, num_heads=4)
>>> x = torch.randn(2, 8, 32)
>>> layer(x).shape
torch.Size([2, 8, 32])
"""
def __init__(self, hidden_size: int, num_heads: int, dropout: float = 0.0) -> None:
super().__init__()
if hidden_size % num_heads != 0:
logger.error(
"hidden_size must be divisible by num_heads",
extra={"hidden_size": hidden_size, "num_heads": num_heads},
)
raise ValueError("hidden_size must be divisible by num_heads")
self.hidden_size = hidden_size
self.num_heads = num_heads
self.head_dim = hidden_size // num_heads
self.qkv = nn.Linear(hidden_size, hidden_size * 3)
self.out = nn.Linear(hidden_size, hidden_size)
self.dropout = nn.Dropout(dropout)
logger.info(
"initialized causal self-attention",
extra={"hidden_size": hidden_size, "num_heads": num_heads},
)
def forward(self, x: Tensor, attention_mask: Optional[Tensor] = None) -> Tensor:
"""Apply masked self-attention.
Args:
x: Input tensor with shape `(batch, sequence_length, hidden_size)`.
attention_mask: Optional additive mask broadcastable to attention scores.
Returns:
Output tensor with shape `(batch, sequence_length, hidden_size)`.
Raises:
ValueError: If `x` does not have shape `(batch, sequence_length, hidden_size)`.
Example:
>>> layer = CausalSelfAttention(hidden_size=32, num_heads=4)
>>> layer(torch.randn(2, 8, 32)).shape
torch.Size([2, 8, 32])
"""
if x.ndim != 3:
logger.error("input tensor must be rank 3", extra={"rank": x.ndim})
raise ValueError("x must have shape (batch, sequence_length, hidden_size)")
batch_size, sequence_length, _ = x.shape
qkv = self.qkv(x)
query, key, value = qkv.chunk(3, dim=-1)
query = self._split_heads(query)
key = self._split_heads(key)
value = self._split_heads(value)
scores = query @ key.transpose(-2, -1)
scores = scores / math.sqrt(self.head_dim)
causal_mask = torch.triu(
torch.ones(sequence_length, sequence_length, device=x.device, dtype=torch.bool),
diagonal=1,
)
scores = scores.masked_fill(causal_mask, torch.finfo(scores.dtype).min)
if attention_mask is not None:
# パディングなどの無効位置を、causal maskと同じ加算形式にそろえるため。
scores = scores + attention_mask
attention_weights = torch.softmax(scores, dim=-1)
attention_weights = self.dropout(attention_weights)
context = attention_weights @ value
context = context.transpose(1, 2).contiguous().view(batch_size, sequence_length, -1)
logger.debug(
"computed causal self-attention",
extra={"batch_size": batch_size, "sequence_length": sequence_length},
)
return self.out(context)
def _split_heads(self, x: Tensor) -> Tensor:
"""Split hidden states into attention heads.
Args:
x: Tensor with shape `(batch, sequence_length, hidden_size)`.
Returns:
Tensor with shape `(batch, num_heads, sequence_length, head_dim)`.
Raises:
RuntimeError: If the input cannot be reshaped to the configured heads.
Example:
>>> layer = CausalSelfAttention(hidden_size=32, num_heads=4)
>>> layer._split_heads(torch.randn(2, 8, 32)).shape
torch.Size([2, 4, 8, 8])
"""
batch_size, sequence_length, _ = x.shape
return x.view(batch_size, sequence_length, self.num_heads, self.head_dim).transpose(1, 2)この実装で重要なのは、torch.triu(..., diagonal=1) によって未来側だけをマスクしている点です。
この1行がないと、学習時に未来tokenを参照できてしまい、自己回帰生成と条件が合わなくなります。
推論時にKV Cacheが重要になる理由
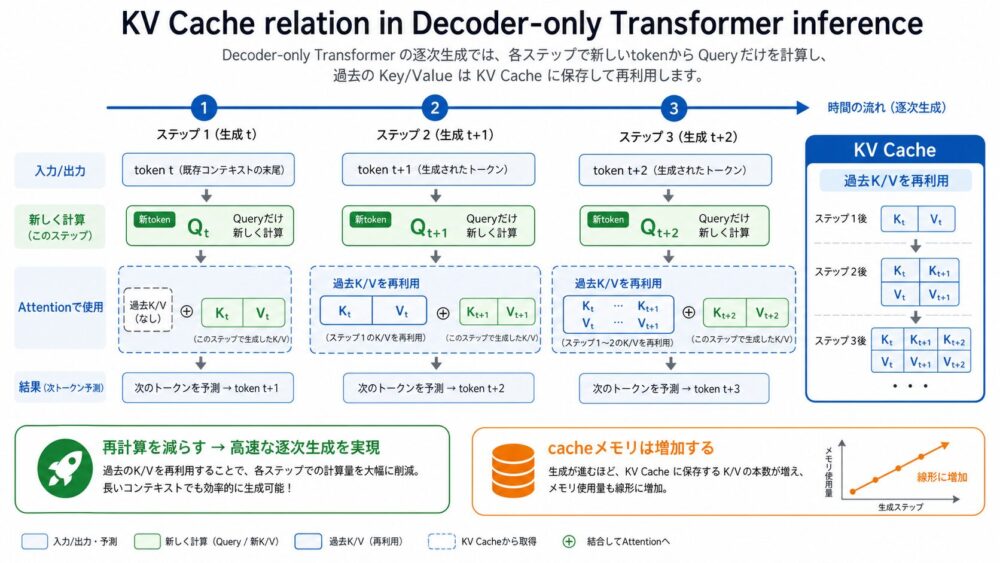 Decoder-only推論でKV Cacheが過去のKeyとValueを再利用する流れ
Decoder-only推論でKV Cacheが過去のKeyとValueを再利用する流れDecoder-only Transformerは、生成時に1 tokenずつ出力します。
たとえば、1000 tokenの文脈から1001個目を生成し、次に1002個目を生成します。
素朴に毎回すべての過去tokenのKeyとValueを再計算すると、生成が長くなるほど無駄が大きくなります。
そこで使われるのがKV Cacheです。
KV Cacheは、過去tokenから計算済みのKeyとValueを保存し、次のtoken生成時に再利用する仕組みです。
| 推論方式 | 各stepで行うこと | メリット | 注意点 |
|---|---|---|---|
| KV Cacheなし | 過去全tokenのQ/K/Vを再計算 | 実装が単純 | 長い生成で遅い |
| KV Cacheあり | 新tokenのQ/K/Vだけ計算し、過去K/Vを再利用 | 逐次生成が高速 | cacheメモリが増える |
Decoder-onlyでは、未来tokenを見ないため、過去のKeyとValueは後から変わりません。
この性質が、KV Cacheと非常に相性がよいです。
次回以降のシリーズでKV Cacheを扱うときも、今回のcausal maskと自己回帰生成の理解が土台になります。
よくある誤解
| 誤解 | 正確な見方 |
|---|---|
| Decoder-onlyは元論文のdecoderをそのまま使う | GPT系ではencoder-decoder attentionを省いた自己回帰LM向け構造として使う |
| Decoder-onlyは入力を理解できない | 入力理解も「文脈を読んで次tokenを出す」形で扱える |
| causal maskは推論時だけ必要 | 学習時にも未来tokenを見ない条件を保つために必要 |
| GPT-2はタスクを明示的に教師あり学習した | 主にWebTextで次token予測を行い、ゼロショット評価した |
| 大きくすれば常に正しい回答になる | データの偏り、事実誤り、安全性、評価条件の問題は残る |
特に「Decoder-onlyはdecoderだから翻訳用のdecoderと同じ」と考えると混乱しやすいです。
GPT系では、encoderからのcross-attentionを持たない、causal mask付きSelf-Attentionの積み重ねとして捉えるのが実装上も分かりやすいです。
GPT-2論文から現代LLMへ

GPT-2論文は、現在のLLMをそのまま完成させた論文ではありません。
しかし、次の考え方を強く印象づけました。
- 大規模Webテキストで次token予測を行うと、多様な言語タスクの能力が現れうる
- タスクごとのモデル設計より、汎用的な自己回帰言語モデルを大きくする方針に可能性がある
- プロンプトにタスクを自然言語で書くと、モデルの振る舞いをある程度制御できる
- Decoder-only Transformerは、学習と生成を同じ次token予測で統一しやすい
GPT-3では、この方向性がさらに大規模化され、few-shot promptingの性能が詳しく検証されました。
その後、Instruction TuningやRLHFにより、単に続きを生成するモデルから、ユーザー指示に従う対話型LLMへ発展していきます。
Decoder-only Transformerは、その流れの中心にある構造です。
まとめ
Decoder-only Transformerは、GPT系LLMを理解するための重要な基礎です。
ポイントは、未来tokenを見ないcausal mask、次token予測、Self-Attentionの積み重ね、そして逐次生成との相性です。
GPT-2論文は、この構造を大規模WebTextで学習させることで、タスク専用の教師あり学習なしに複数タスクのゼロショット性能が現れる可能性を示しました。
ただし、GPT-2の結果は「何でも正しく解ける」ことを意味しません。
Web由来データの偏り、事実性、安全性、評価条件の限界を意識して読む必要があります。
それでも、Decoder-only Transformerの設計は、現在のChatGPTや多くのLLMを理解するうえで避けて通れない土台です。
関連技術
| 技術 | 関係 |
|---|---|
| Tokenization | 入力文字列をtoken列に変換する前処理 |
| Embedding | token idをベクトルへ変換する層 |
| Self-Attention | 文脈内のtoken同士の関係を計算する仕組み |
| Positional Encoding | tokenの順序情報をモデルへ渡す仕組み |
| KV Cache | 生成時に過去のKey/Valueを再利用する高速化手法 |
| Instruction Tuning | 指示に従いやすくする追加学習 |
次に読むべき記事
- LLMとは何か?GPT-3論文で仕組みをわかりやすく解説
- Tokenizationとは?AIは文章をどう分割しているのか
- Self-Attentionとは?文中の単語同士の関係を学ぶ仕組み
- Positional Encodingとは?RoPEでLLMが語順を扱う仕組みを理解する
- KV Cacheとは?LLMの生成を高速化する仕組み
コメント