LLMに長い社内文書や大量の記事を読ませる方法として、RAG(検索拡張生成)と長文コンテキストがよく使われます。
しかし、検索すれば取りこぼしが起き、全部入れれば推論コストやattention dilution(長い文脈の中で重要情報が薄まる現象)が問題になります。
本記事では、arXiv論文「WiCER: Wiki-memory Compile, Evaluate, Refine」をもとに、長文知識をWiki-memory(LLMが参照しやすい構造化された知識メモリ)へ圧縮し、欠落した事実を診断しながら改善する仕組みを解説します。
3文要約
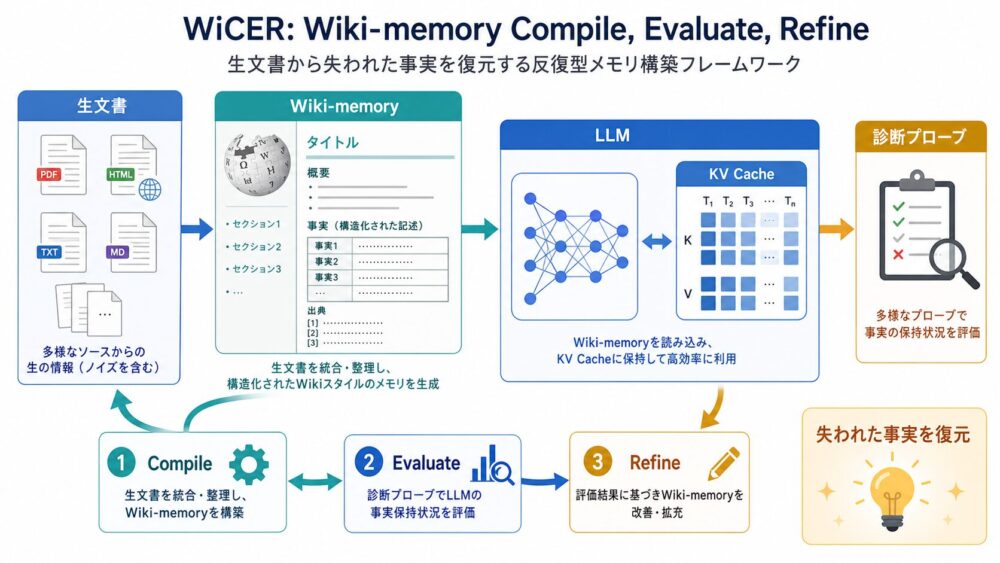
WiCERは、元文書をそのままLLMへ入れるのではなく、ドメイン知識をWiki-memoryとしてコンパイルし、KV cache inference(事前に読み込んだ文脈の注意計算状態を再利用する推論方式)で高速に参照するための手法です。
単純に文書をWikiへ要約すると、重要な事実が落ちるcompilation gap(圧縮時に回答に必要な事実が失われる問題)が起きるため、WiCERは診断用の質問で欠落を見つけ、次のコンパイルでその事実を保持するように反復します。
論文では、17個のRepLiQAドメイン、6,800問の評価で、1〜2回の反復によりblind compilation(診断なしの単純コンパイル)で失われた品質の80%を回復し、catastrophic failure(致命的な回答失敗)を相対的に55%減らしたと報告されています。
論文情報
| 項目 | 内容 |
|---|---|
| 論文タイトル | WiCER: Wiki-memory Compile, Evaluate, Refine Iterative Knowledge Compilation for LLM Wiki Systems |
| 著者 | Juan M. Huerta |
| 発表年 | 2026年 |
| arXiv | arXiv:2605.07068v1 |
| 公開日 | 2026年5月8日 |
| 分野 | Computation and Language, Artificial Intelligence |
| 論文リンク | WiCER: Wiki-memory Compile, Evaluate, Refine |
| DOI | 10.48550/arXiv.2605.07068 |
本記事の目的
この記事の目的は、WiCERを「新しいRAG手法」としてではなく、LLMに知識を持たせる方法の設計問題として理解することです。
LLMアプリケーションでは、次のような悩みがよく出ます。
- RAGで検索したchunk(文書を分割した断片)に必要情報が入らない
- 長文コンテキストに全部入れると遅い、または重要情報が埋もれる
- 要約やWiki化をすると、回答に必要な細かい事実が消える
- 社内ナレッジを更新しても、どの情報がLLM回答に効いているか分かりにくい
WiCERは、この4つ目の問題に踏み込んでいます。
つまり「知識を圧縮したら終わり」ではなく、「圧縮した知識で実際に答えさせ、失敗した質問からWikiを直す」という閉ループを作ります。
背景:RAG、Full-context KV cache、Wiki-memoryの違い

LLMに外部知識を与える代表的な方法は、RAGとfull-context KV cacheです。
RAGは、質問のたびに関連しそうな文書断片を検索し、その断片だけをプロンプトへ入れます。
一方、full-context KV cacheは、ドメイン文書全体を先にコンテキストへ読み込み、そのKV cacheを保存しておき、質問時には短い質問だけを追加して答えます。
| 方式 | 知識の入れ方 | 強み | 弱み | 向きやすい場面 |
|---|---|---|---|---|
| RAG | 質問ごとに関連chunkを検索する | トークン量を抑えやすい | 検索失敗、chunk境界、retriever調整が問題になる | 大規模で頻繁に更新される文書群 |
| Full-context KV cache | 文書全体を先に読み込み、KV cacheを再利用する | 検索漏れがなく、TTFTを短くしやすい | 長文化でattention dilutionが起きる | curated corpus(整理済み文書群)が短めに収まる場合 |
| Wiki-memory | 元文書を構造化Wikiへ圧縮し、cacheで参照する | 知識を管理しやすく、長期運用に向く | 圧縮時の事実欠落が問題になる | 社内FAQ、製品仕様、ドメイン知識ベース |
論文では、30本のPolicygenius記事、約67K tokensのcurated knowledgeでは、full-context KV cacheがRAGより高い平均スコアを示しています。
具体的には、5点満点の評価でfull-contextが4.38、RAGが4.08です。
また、TTFT(Time To First Token、最初のトークンが返るまでの時間)はfull-contextが0.857秒、RAGが6.277秒で、full-contextのほうが7.3倍速いと報告されています。
ただし、これは「整理済みの短めの知識」ではうまくいく、という話です。
RepLiQAのように80文書、55K〜95K tokens、17ドメインへ広げると、full-contextはattention dilutionによりRAGを下回ります。
論文では、RAGが3.64、full-contextが3.47という平均スコアになっています。
ここで自然に出てくる発想が、元文書をそのまま入れるのではなく、構造化されたWikiへコンパイルしてからcacheすることです。
論文解説
ここからは、論文の中心であるWiCERを順番に整理します。
大きな流れは、compilation gapを確認し、WiCERのCompile、Evaluate、Refineの反復ループを見て、実験結果と限界を読む、という構成です。
Compilation gap:Wiki化で重要事実が落ちる問題
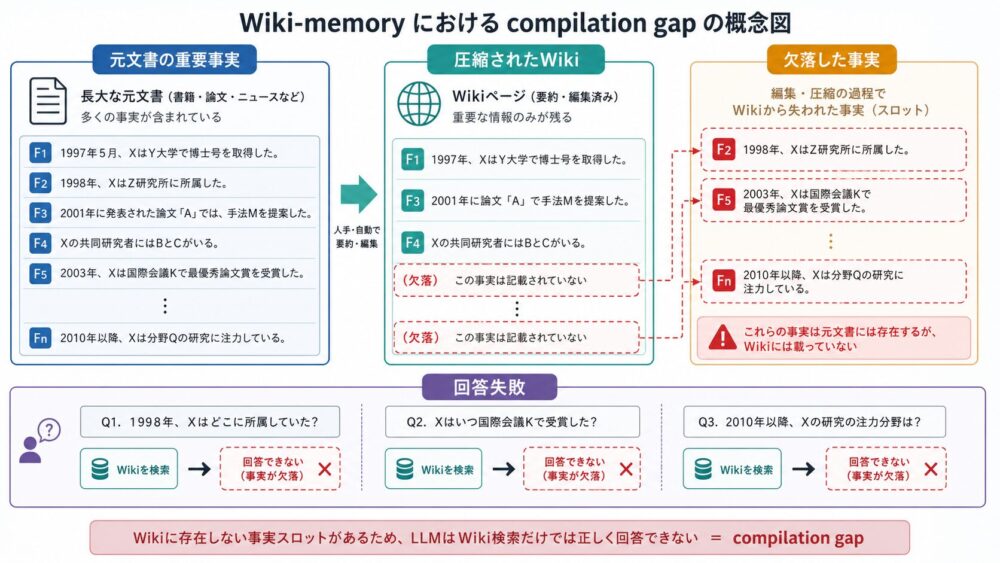
元文書をWiki-memoryへ圧縮すれば、コンテキスト長を減らしつつ、構造化された知識をLLMへ渡せます。
しかし、LLMに「この文書群をWikiにまとめて」と頼むだけでは、回答に必要な細かい事実が落ちます。
これがcompilation gapです。
たとえば、保険、社内規程、製品仕様のような文書では、次のような情報が重要になります。
| 文書内の情報 | 要約で落ちやすい理由 | 質問応答での影響 |
|---|---|---|
| 例外条件 | 本文全体では細部に見える | 特定ケースの回答を間違える |
| 数値しきい値 | 文脈上は補足に見える | 金額、期間、対象条件を間違える |
| 条件分岐 | 要約時に一般則へ丸められる | 「AならB、CならD」を混同する |
| 文書間の差分 | 個別文書では小さい違いに見える | 類似制度や類似製品を混同する |
論文では、blind compilationが2.14〜2.32の平均スコアに落ち、raw full-contextの3.47を大きく下回ったと報告されています。
さらに、catastrophic failure rateは53〜60%に達しています。
これは、単なる文章要約としては読めるWikiでも、質問応答用の知識メモリとしては十分でないことを示しています。
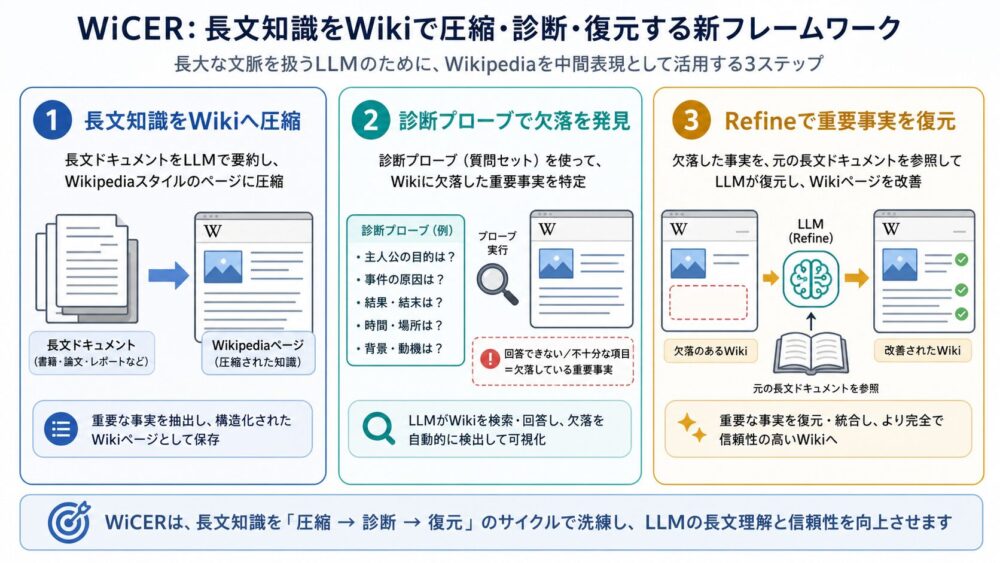
WiCERの基本アイデア:Compile, Evaluate, Refine
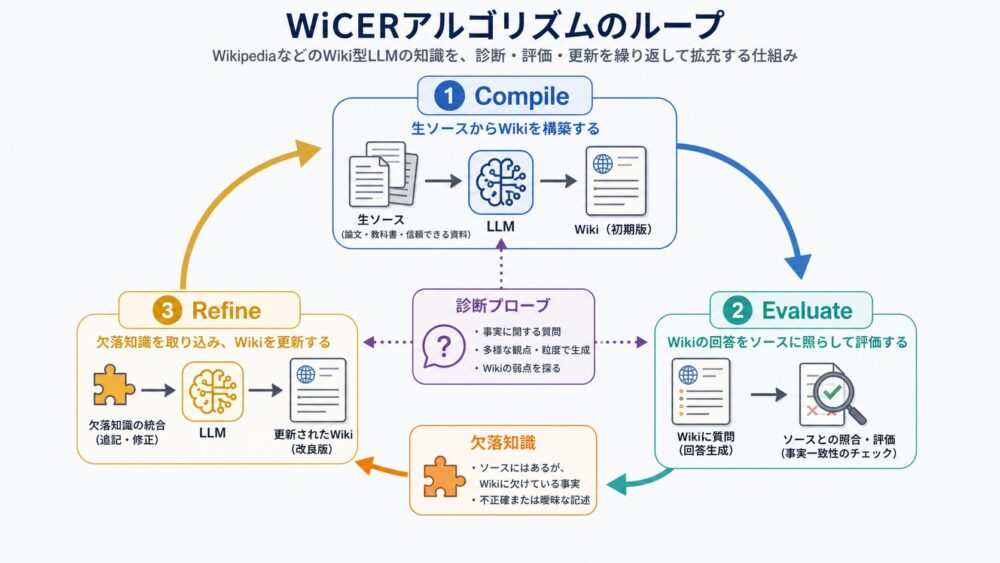
WiCERは、Wiki-memoryを一度作って終わりにしません。
次の3段階を反復します。
- Compile: 元文書からWiki-memoryを作る
- Evaluate: 診断用の質問でWiki-memoryを評価する
- Refine: 失われた事実を特定し、次のWiki作成で保持するように指示する
論文は、この考え方をCEGAR(Counterexample-Guided Abstraction Refinement、反例で抽象化を改善する手法)になぞらえています。
CEGARでは、抽象化されたモデルで見つかった反例を使って、抽象化が粗すぎた部分を修正します。
WiCERでは、Wiki-memoryが答えられなかった質問を反例のように扱い、どの事実が落ちたのかを特定します。
| 段階 | 入力 | 出力 | 役割 |
|---|---|---|---|
| Compile | raw documents | wiki draft | 長文知識を構造化して短くする |
| Evaluate | wiki draft, diagnostic probes | failure cases | Wikiだけで答えられない質問を見つける |
| Diagnose | source, failed question, wiki answer | missing facts | 元文書にはあるがWikiにない情報を特定する |
| Refine | missing facts, previous wiki | refined wiki | 次回のWikiで重要事実を保持する |
この設計の面白い点は、品質改善の単位が「要約をもっと詳しくする」ではないことです。
質問応答で落ちた事実を狙って戻すため、単に全文を長くするよりも、必要な知識を保ちやすくなります。
WiCERを簡略化した擬似コード
論文の考え方を、実装イメージとして書くと次のようになります。
完全な評価系ではありませんが、「失敗した質問から保持すべき事実を次のコンパイルへ渡す」という要点を示しています。
import logging
from dataclasses import dataclass, field
logger = logging.getLogger(__name__)
@dataclass(frozen=True)
class DiagnosticProbe:
"""Wiki-memoryの欠落を調べるための質問。
Args:
question: Wiki-memoryだけで答えさせる質問。
expected_source_id: 正解根拠が含まれる元文書ID。
Returns:
DiagnosticProbeインスタンス。
Raises:
ValueError: questionが空文字の場合。
Example:
>>> probe = DiagnosticProbe("対象外になる条件は?", "policy_001")
>>> probe.expected_source_id
'policy_001'
"""
question: str
expected_source_id: str
def __post_init__(self) -> None:
if not self.question.strip():
logger.error("empty diagnostic question: source=%s", self.expected_source_id)
raise ValueError("question must not be empty")
@dataclass
class WicerState:
"""WiCERの反復状態を保持する。"""
wiki_memory: str
pinned_facts: list[str] = field(default_factory=list)
def refine_wiki_prompt(state: WicerState, failed_facts: list[str]) -> str:
"""次のWikiコンパイルで保持すべき事実をプロンプト化する。
Args:
state: 現在のWiki-memoryと保持済み事実。
failed_facts: 評価で欠落していると診断された事実。
Returns:
LLMへ渡すRefine用プロンプト。
Raises:
ValueError: wiki_memoryが空の場合。
Example:
>>> state = WicerState("## 製品仕様\\n- 基本保証は1年")
>>> prompt = refine_wiki_prompt(state, ["延長保証は購入後30日以内に申請する"])
>>> "延長保証" in prompt
True
"""
if not state.wiki_memory.strip():
logger.error("wiki memory is empty")
raise ValueError("wiki_memory must not be empty")
merged_facts = [*state.pinned_facts, *failed_facts]
logger.info("building refine prompt with %d pinned facts", len(merged_facts))
# 欠落事実を明示的に固定することで、次の圧縮で再び消えるのを防ぐ。
fact_block = "\n".join(f"- {fact}" for fact in merged_facts)
return (
"以下のWiki-memoryを、元文書に忠実なまま更新してください。\n"
"特に、次の事実は質問応答で必要だったため必ず保持してください。\n\n"
f"{fact_block}\n\n"
"現在のWiki-memory:\n"
f"{state.wiki_memory}"
)実運用では、診断用プローブの作り方、失敗判定の基準、元文書からmissing factsを抽出する方法が重要になります。
論文では、単に「重要そうな事実を全部固定する」のではなく、質問応答で実際に失敗した事実をtargeted diagnosis(狙いを定めた欠落診断)で戻す点を強調しています。
実験設定:どの条件で比較したのか
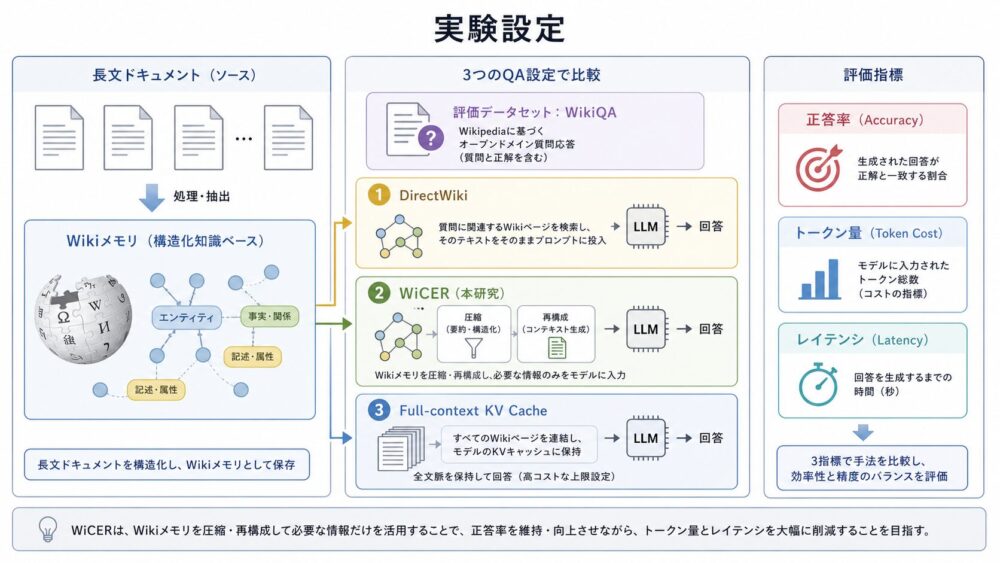
論文では、主に2種類の文書コーパスを使っています。
| コーパス | 内容 | 規模 | 役割 |
|---|---|---|---|
| Policygenius | 保険や estate planning の編集済み記事 | 30記事、約67K tokens、240 QA | curated knowledgeでfull-contextが強いことを確認 |
| RepLiQA | 合成された多ドメインQAベンチマーク | 17 topic、1,360文書、6,800 QA | scale、compilation gap、WiCERの効果を検証 |
モデル設定も実運用寄りです。
Llama 3.1 8B Instructを、llama.cpp上で96K context window、q8_0 KV cache、Flash Attentionで動かしています。
評価は、Claude SonnetによるLLM-as-Judge(LLMを評価者として使う方法)で1〜5点のスコアを付けています。
また、100件の人手評価でjudgeの妥当性も確認し、Pearson相関0.94、完全一致75%、1点以内一致99%と報告されています。
実験結果:WiCERは何を改善したのか
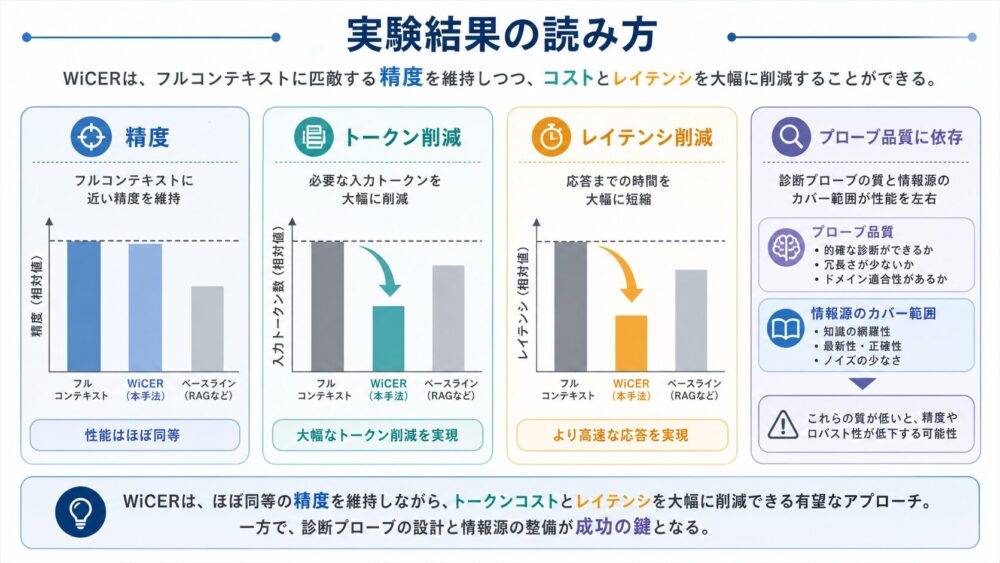
論文の結果は、次の順番で読むと分かりやすいです。
| 比較 | 結果 | 解釈 |
|---|---|---|
| curated knowledgeでのfull-context vs RAG | 4.38 vs 4.08、TTFTは7.3倍速い | 整理済みで短めなら、全部cacheする方式が強い |
| raw RepLiQAでのfull-context vs RAG | 3.47 vs 3.64 | 長くなるとattention dilutionでfull-contextが落ちる |
| blind compilation vs raw full-context | 2.14〜2.32 vs 3.47 | Wiki化だけでは重要事実を落としすぎる |
| WiCER vs blind compilation | +0.95、lost qualityの80%を回復 | 欠落診断つきの反復が効いている |
| generic pinning vs targeted diagnosis | +0.16 vs +0.95 | 一般的に詳しくするより、失敗から戻すほうが有効 |
ここで重要なのは、WiCERがraw full-contextを常に上回ると主張しているわけではないことです。
論文の主張は、blind compilationで大きく落ちた品質を、1〜2回の反復でかなり戻せる、というものです。
平均スコアでは、WiCERが3.24、raw full-contextが3.47です。
つまり、WiCERは「品質を大きく落とさずに、Wiki-memoryという運用しやすい形へ近づける」手法として見るのが自然です。
なぜtargeted diagnosisが効くのか
blind compilationの問題は、LLMが何を落としてはいけないかを知らないまま圧縮している点です。
人間が文書をWiki化するときも、利用者から何度も質問される項目、問い合わせで誤解が多い条件、例外規定は残します。
WiCERは、この利用者質問に相当するものをdiagnostic probesとして作ります。
| 改善方法 | 何を固定するか | 効き方 | トレードオフ |
|---|---|---|---|
| generic pinning | 重要そうな文や見出しを一般的に固定 | 実装は簡単 | 実際の質問に効くとは限らない |
| targeted diagnosis | 失敗質問に必要だった事実を固定 | 回答品質に直結しやすい | 評価プローブと診断処理が必要 |
| raw full-context | 元文書をすべて保持 | 情報欠落は少ない | 長文化、attention dilution、メモリ負荷がある |
WiCERは、知識ベースを「読むための要約」ではなく「質問に答えるための実行可能なメモリ」として扱っています。
この視点が、単なる要約技術との違いです。
LLMサービスや社内ナレッジへの応用
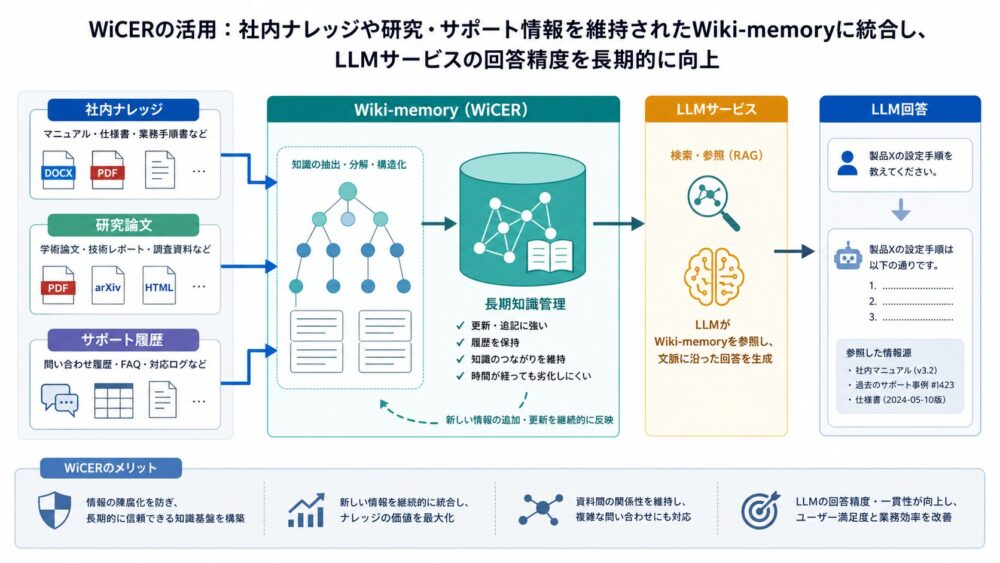
WiCERの考え方は、社内FAQや製品サポートのLLMシステムと相性がよいです。
特に、次のような条件では検討する価値があります。
| 利用場面 | WiCERが効きそうな理由 | 注意点 |
|---|---|---|
| 社内規程QA | 例外条件や申請条件が重要 | 更新履歴と監査ログが必要 |
| 製品仕様QA | 似た製品の差分をWikiに整理できる | 古い仕様が残ると誤回答になる |
| サポートチャット | 実際の問い合わせを診断プローブにできる | 個人情報や機密情報の扱いに注意 |
| 論文・技術文書QA | 長い文献をテーマ別Wikiへ整理できる | 数式や表の事実欠落を検出しにくい |
| 法務・保険・医療の補助 | 条件分岐と根拠参照が重要 | 高リスク領域では人間確認が必須 |
実運用で面白いのは、ユーザーから実際に来た質問を、次のRefineの材料にできる点です。
答えられなかった質問や、人間が修正した回答をdiagnostic probesとして蓄積すれば、知識ベースが利用実態に合わせて改善されます。
ただし、自動でWikiを書き換える場合は、元文書への根拠リンク、差分レビュー、公開前評価を入れないと危険です。
WiCERは「LLMに勝手に知識を作らせる」方法ではありません。
元文書にある事実を、回答に必要な形で落とさず保持するための反復フレームワークです。
よくある誤解
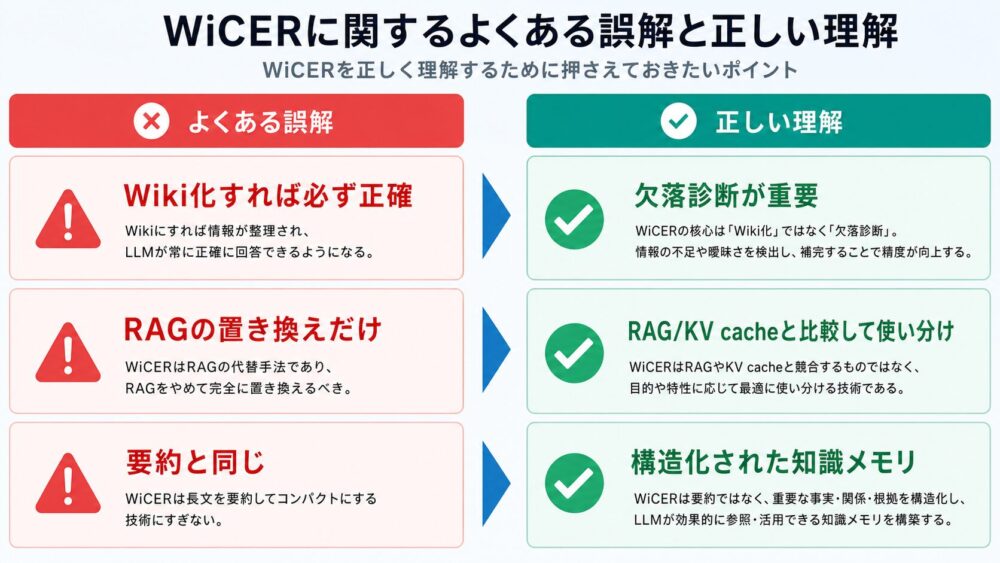
| 誤解 | 正確な見方 |
|---|---|
| WiCERはRAGを置き換える手法である | RAG、full-context KV cache、Wiki-memoryを比較し、Wiki-memoryの弱点であるcompilation gapを埋める手法である |
| Wiki化すれば長文問題は解決する | 単純なWiki化では重要事実が落ち、blind compilationは大きく品質を落とす |
| 要約を長くすればよい | generic pinningより、失敗質問から欠落事実を戻すtargeted diagnosisが効いている |
| KV cacheを使えば常にRAGより良い | curated knowledgeでは強いが、文書数が増えるとattention dilutionでRAGを下回る場合がある |
| WiCERは完全な正解保証を与える | 論文は品質回復を示しているが、プローブ品質、judge、元文書品質に依存する |
関連技術
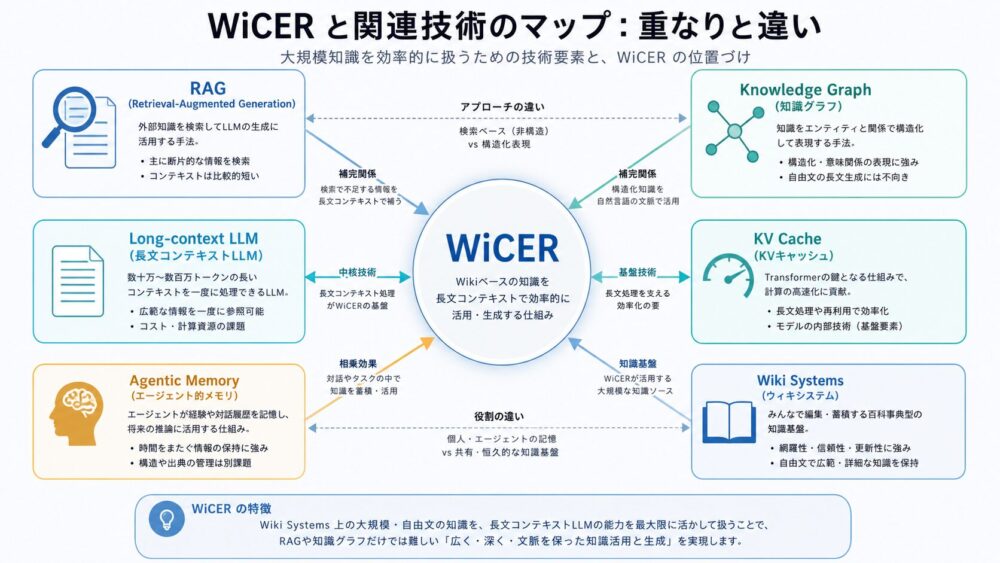
WiCERは、RAG、長文コンテキスト、knowledge graph、agent memoryの中間にあります。
| 関連技術 | 目的 | WiCERとの違い |
|---|---|---|
| RAG | 質問時に関連文書を検索する | WiCERは検索ではなく、事前にWiki-memoryへ知識をコンパイルする |
| CAG | 知識をコンテキストへ事前ロードしてcacheする | WiCERはcacheする知識を反復的に改善する |
| Knowledge Graph | エンティティと関係をグラフで表す | WiCERはflat wiki artifactを対象にしている |
| GraphRAG | グラフ構造を使って検索・要約する | WiCERは静的な構造化だけでなく、評価失敗から再コンパイルする |
| Agent Memory | エージェントが経験や事実を保持する | WiCERは元文書に基づくドメイン知識の保持に焦点を当てる |
まとめ
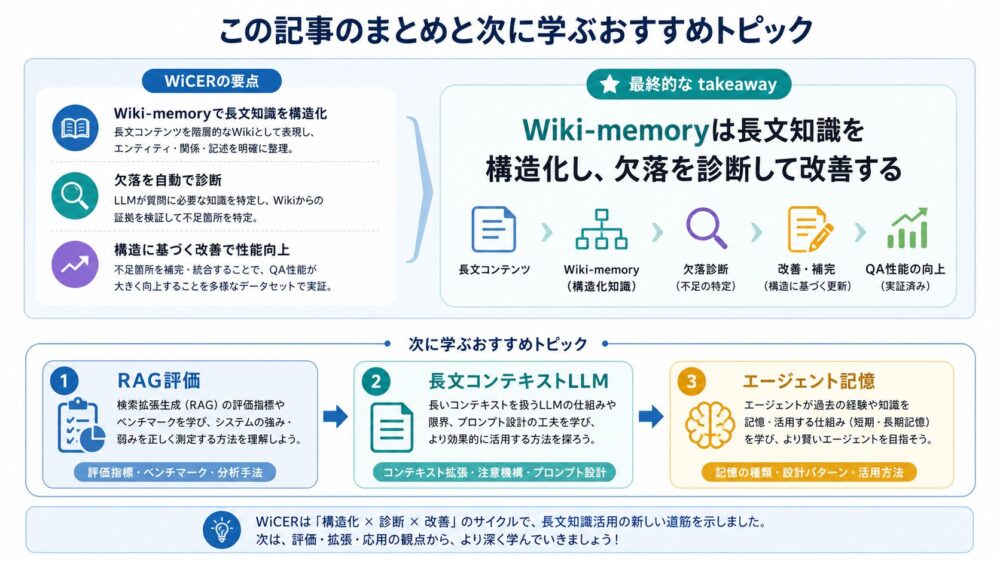
WiCERは、LLMに長文知識を与える方法を、単なる検索や要約ではなく「知識をコンパイルし、評価し、改善する」問題として扱う論文です。
curated knowledgeではfull-context KV cacheがRAGより高精度かつ高速なTTFTを示しますが、文書数が増えるとattention dilutionが起きます。
そこでWiki-memoryへ圧縮したくなりますが、blind compilationでは重要事実が落ちるcompilation gapが起きます。
WiCERは、診断用質問で欠落事実を見つけ、次のコンパイルで保持することで、このgapを大きく縮めます。
個人的には、RAGの次に来る話題として「検索をどう賢くするか」だけでなく、「知識ベースをLLM向けにどう保守するか」が重要になると感じました。
社内文書、仕様書、サポートログ、研究メモのように、長期的に更新される知識を扱う場合、WiCERのcompile-evaluate-refineの考え方はかなり実務的です。
関連記事へのリンク
現時点では、以下の記事とつなげると読みやすいです。
- Decoder-only Transformerとは?GPT系LLMの仕組みを解説
- Embeddingとは?BERT論文から単語・文章をベクトルで表す仕組みを解説
- LLMとは?GPT-3論文から大規模言語モデルの仕組みをやさしく解説
次に読むべき記事
次に読むなら、RAG評価、長文コンテキスト、LLM memoryの3つが相性のよいテーマです。
| 記事案 | 学べること | 優先度 |
|---|---|---|
| RAG評価とは?retrieval failureと回答品質を分けて見る方法 | RAGが失敗する場所を分解できる | 高 |
| KV Cacheとは?LLM推論でなぜ高速化できるのか | WiCERの推論基盤を理解できる | 高 |
| Long-context LLMのattention dilutionとは? | full-context方式の限界を理解できる | 高 |
| GraphRAGとは?Knowledge GraphとRAGを組み合わせる仕組み | 構造化知識との比較ができる | 中 |
| Agent Memoryとは?LLMエージェントの記憶設計を整理 | WiCERを長期記憶の観点で位置づけられる | 中 |

コメント