【LLM解説シリーズ】Self-Attentionとは?Scaled Dot-Product Attentionを数式と実装から理解する
Self-Attentionは、同じtoken列の中で各tokenが他のtokenをどれくらい参照するかを計算し、文脈を含んだ表現へ更新する仕組みです。
3文要約
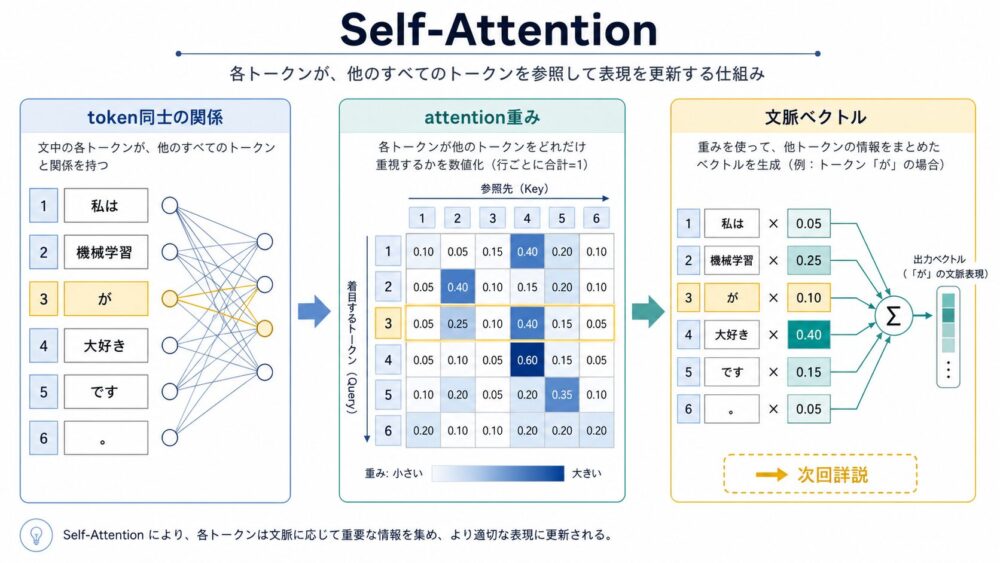
Self-Attention(同じ系列内のtoken同士が互いを参照する仕組み)は、Transformerや現在のLLM(Large Language Model、大規模言語モデル)の中核にある計算です。
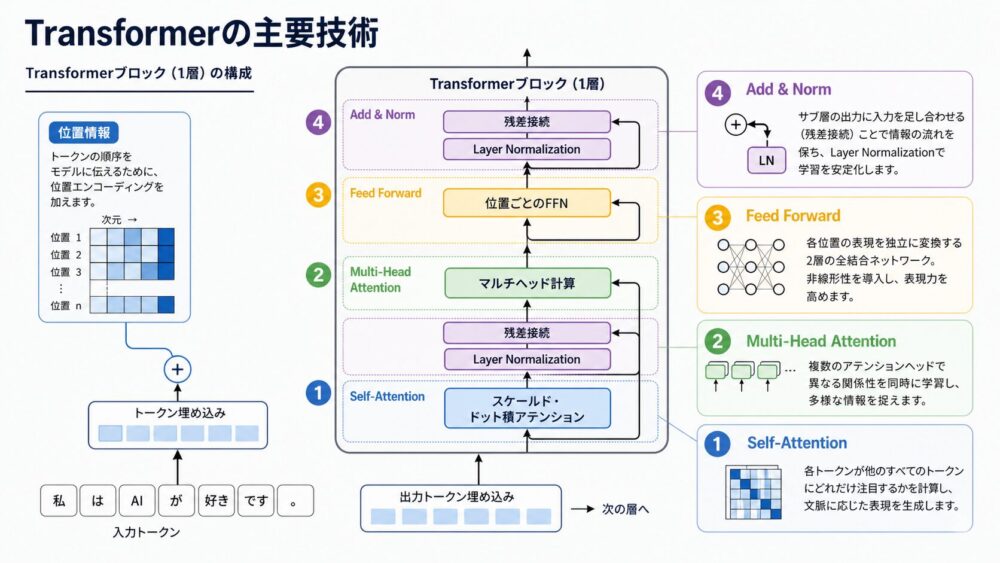
VaswaniらのTransformer論文では、Query、Key、Valueを使うScaled Dot-Product Attentionを定式化し、複数headで並列に計算するMulti-Head Attentionを提案しています。
LLMを実装目線で理解するには、\(QK^T\)、softmax、mask、tensor形状、\(O(n^2)\) の計算量をまとめて押さえることが重要です。
論文情報
| 項目 | 内容 |
|---|---|
| 論文タイトル | Attention Is All You Need |
| 著者 | Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin |
| 初版公開日 | 2017年6月12日 |
| 最終改訂 | 2023年8月2日 v7 |
| 採択 | NeurIPS 2017 |
| 分野 | Computation and Language, Machine Learning |
| arXiv | Attention Is All You Need |
| DOI | 10.48550/arXiv.1706.03762 |
Self-Attentionが必要になる背景
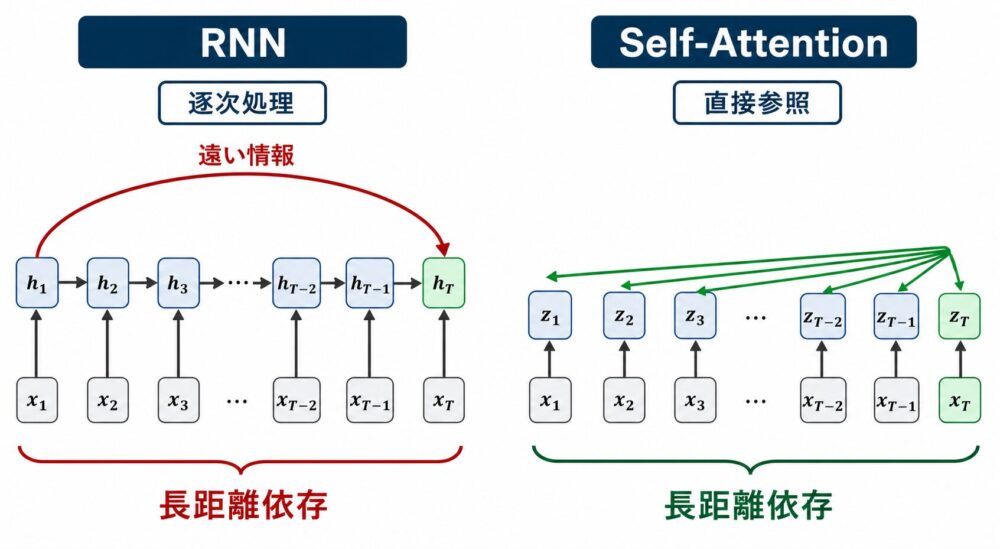
先ほどのTransformer編では、Transformer全体を「Attentionを中心に系列を処理するアーキテクチャ」として整理しました。
今回は、その中心部であるSelf-Attentionを掘り下げます。
RNN(Recurrent Neural Network、前の状態を次へ渡しながら系列を処理するニューラルネットワーク)は、tokenを順番に処理します。
この方法は順序を扱いやすい一方で、長い文では遠くの情報が届くまでに多くのステップが必要になります。
Self-Attentionは、同じ層の中で全token同士の関係を計算します。
たとえば 私は 機械学習 が 大好き です という文では、大好き が 私 や 機械学習 を直接参照できます。
| 観点 | RNN | Self-Attention |
|---|---|---|
| 処理順 | 左から右など逐次的 | 層内では全位置をまとめて計算しやすい |
| 遠いtokenの関係 | 情報経路が長くなりやすい | 1層で直接スコアを計算できる |
| 位置情報 | 処理順に含まれる | Positional Encodingなどで別途加える |
| 計算量の注意点 | 長さ方向の逐次性が重い | token数に対して \(O(n^2)\) になりやすい |
つまりSelf-Attentionは、長距離依存を扱いやすくする一方で、全tokenペアを比較するため長文では計算・メモリが重くなります。
Scaled Dot-Product Attentionの式
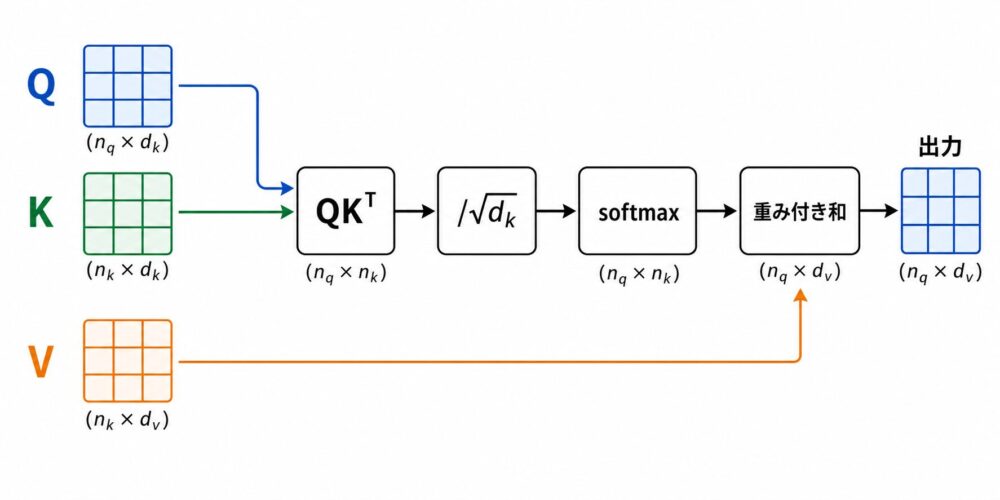
Transformer論文のAttentionは、次の式で表されます。
\[
\mathrm{Attention}(Q, K, V) =
\mathrm{softmax}\left(
\frac{QK^T}{\sqrt{d_k}}
\right)V
\]
ここで、\(Q\)、\(K\)、\(V\) はそれぞれQuery、Key、Valueです。
直感的には、QueryとKeyで「どこを見るか」を決め、Valueから「何を混ぜるか」を取り出します。
| 記号 | 役割 | 直感 |
|---|---|---|
| \(Q\) | Query | 今のtokenが探している手がかり |
| \(K\) | Key | 各tokenが照合用に持つ手がかり |
| \(V\) | Value | 重みに応じて実際に混ぜる情報 |
| \(d_k\) | Keyの次元数 | 内積スコアのスケール調整に使う値 |
処理を分解すると、次の4ステップです。
- 入力表現から \(Q\)、\(K\)、\(V\) を作る。
- \(QK^T\) でQueryとKeyの相性スコアを計算する。
- \(\sqrt{d_k}\) で割り、softmaxでattention weightへ変換する。
- attention weightで \(V\) を重み付き和する。
なぜ \(\sqrt{d_k}\) で割るのか
Dot-Product Attentionでは、QueryとKeyの内積がスコアになります。
次元数 \(d_k\) が大きいと、内積の値も大きくなりやすくなります。
そのままsoftmax(入力値を合計1の確率分布へ変換する関数)に入れると、分布が極端に尖り、勾配(学習時に重みを更新する信号)が小さくなりやすいです。
そこでTransformer論文では、スコアを \(\sqrt{d_k}\) で割ってスケールを調整します。
| 方法 | スコア | 特徴 |
|---|---|---|
| Dot-Product Attention | \(QK^T\) | シンプルで行列積にしやすいが、次元が大きいとsoftmaxが尖りやすい |
| Scaled Dot-Product Attention | \(QK^T / \sqrt{d_k}\) | 次元数によるスコア肥大を抑える |
| Additive Attention | feedforward networkでスコア計算 | Bahdanau Attentionで使われる形。計算形が異なる |
Q/K/Vを具体例で見る
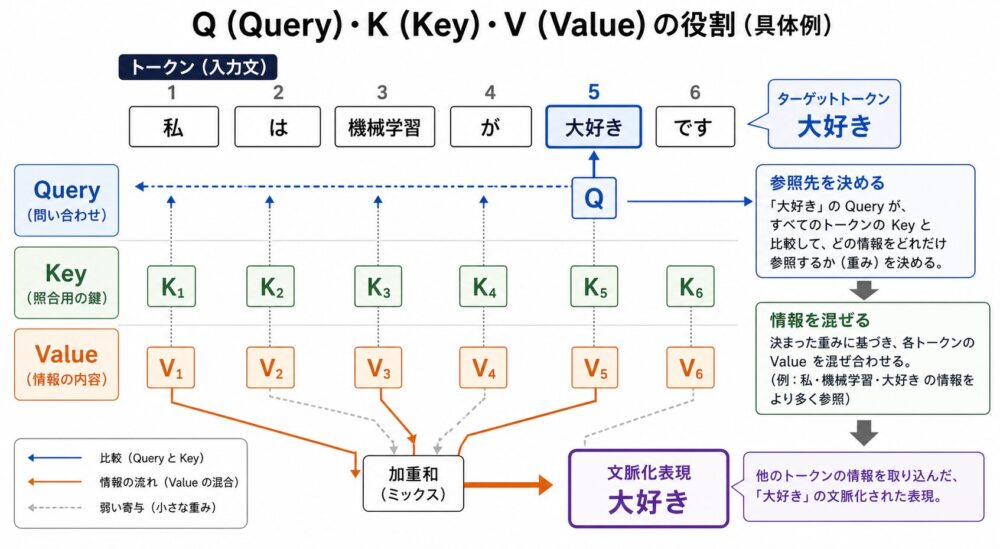
例として、私は 機械学習 が 大好き です というtoken列を考えます。
Self-Attentionでは、各tokenの埋め込みベクトルから3種類のベクトルを作ります。
\[
Q = XW^Q,\quad K = XW^K,\quad V = XW^V
\]
\(X\) は入力token表現、\(W^Q\)、\(W^K\)、\(W^V\) は学習される重み行列です。
大好き の表現を更新するとき、大好き から作ったQueryが、全tokenのKeyと照合されます。
私 や 機械学習 のKeyと相性が高ければ、それらのValueが強く混ざります。
| 対象token | Queryとの相性の例 | Valueとして混ざる情報の例 |
|---|---|---|
私 |
主語として関係しやすい | 誰が好きなのか |
機械学習 |
目的語として関係しやすい | 何が好きなのか |
大好き |
自分自身の意味も保持しやすい | 述語としての意味 |
です |
文末表現として補助的 | 丁寧さや文の終端 |
この計算により、各tokenは単独の単語ベクトルではなく、文脈を反映したベクトルへ更新されます。
tensor形状で理解するSelf-Attention
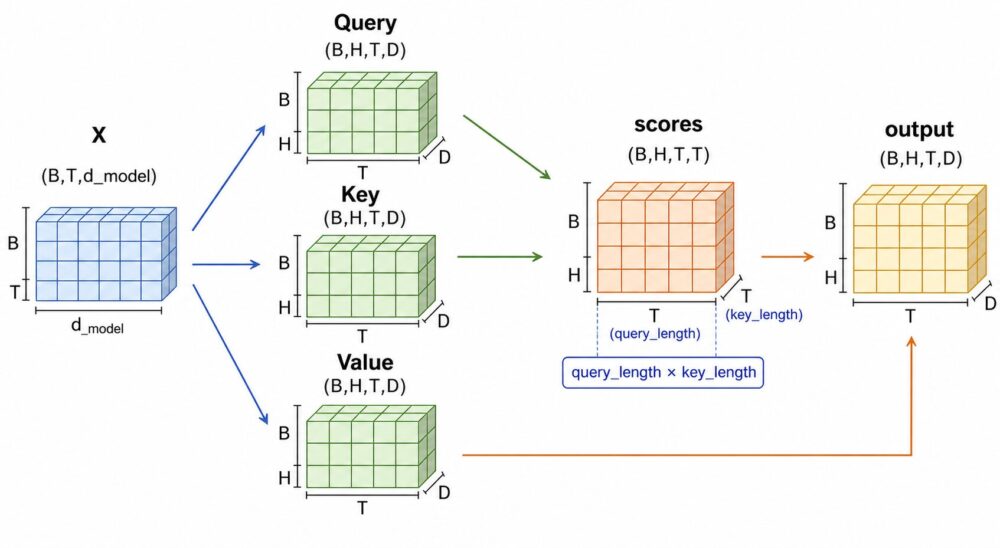
実装では、形状を追うと理解しやすくなります。
batch sizeを \(B\)、系列長を \(T\)、head数を \(H\)、headごとの次元を \(D\) とします。
| tensor | 典型的な形状 | 意味 |
|---|---|---|
| 入力 \(X\) | (B, T, d_model) |
tokenごとの入力表現 |
| Query | (B, H, T, D) |
各headのQuery |
| Key | (B, H, T, D) |
各headのKey |
| Value | (B, H, T, D) |
各headのValue |
| score | (B, H, T, T) |
各Query位置から各Key位置を見るスコア |
| weight | (B, H, T, T) |
softmax後のattention weight |
| output | (B, H, T, D) |
各headの出力 |
重要なのは、scoreの最後の2次元が (query_length, key_length) になることです。
Self-Attentionでは同じ系列内を見るため、多くの場合は (T, T) の行列になります。
ここが \(O(T^2)\) の計算・メモリにつながります。
maskの役割
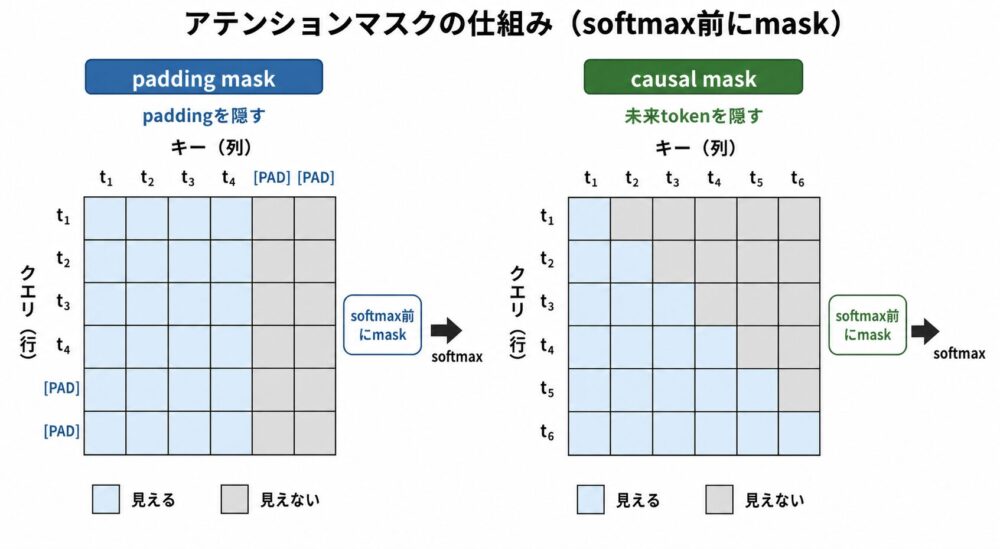
Self-Attentionには、見てよい位置と見てはいけない位置があります。
代表的なのはpadding maskとcausal maskです。
| mask | 目的 | 使う場面 |
|---|---|---|
| padding mask | padding tokenを参照しない | batch内で系列長をそろえるとき |
| causal mask | 未来tokenを参照しない | GPT系の次token予測やDecoderの自己回帰生成 |
GPT系LLMでは、次tokenを予測するときに未来の答えを見てはいけません。
そのため、位置 \(i\) のtokenは位置 \(i\) 以前だけを参照できるようにします。
maskはsoftmaxの前に入れます。
softmax後に0を掛けるだけだと、確率分布の正規化が崩れるためです。
たとえばsoftmax後の重みが [0.2, 0.3, 0.5] で、最後の位置を見てはいけないとします。
softmax後に単純に0を掛けると [0.2, 0.3, 0.0] になり、合計は0.5になります。
これでは、残った見える位置の重みが合計1になるというattention weightの前提が崩れます。
一方、softmax前に見えない位置のscoreを非常に小さい値にしておけば、softmax後は見える位置だけで再正規化されます。
つまり、maskは「不可視位置を消す」だけでなく、「見える位置だけで確率分布を作り直す」ためにsoftmax前へ入れる必要があります。
Multi-Head Attentionとの関係
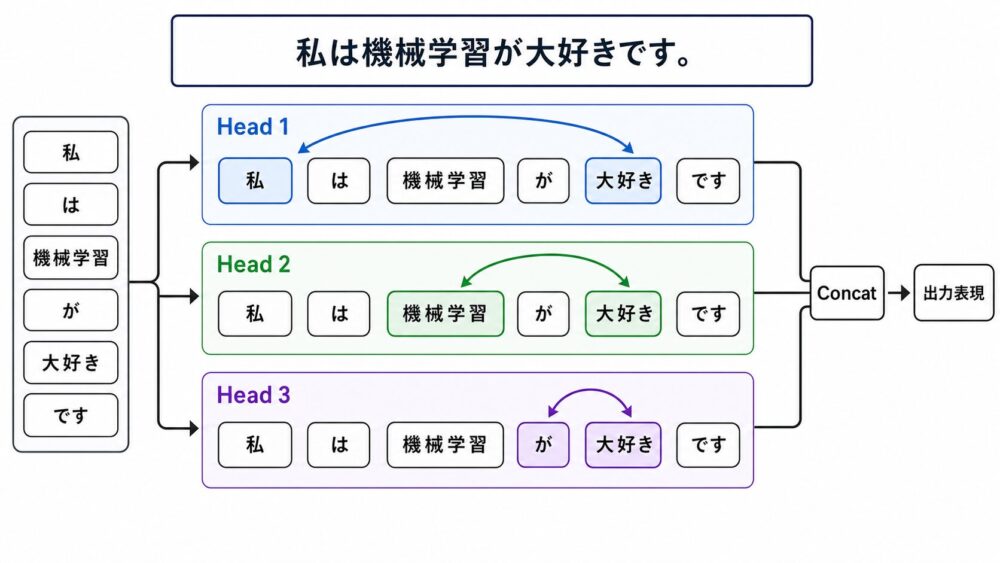
Transformerでは、Self-Attentionを1つだけ使うのではなく、複数のheadで並列に計算します。
\[
\mathrm{MultiHead}(Q, K, V) =
\mathrm{Concat}(\mathrm{head}_1, \ldots, \mathrm{head}_h)W^O
\]
\[
\mathrm{head}_i =
\mathrm{Attention}(QW_i^Q, KW_i^K, VW_i^V)
\]
headは、Q/K/Vを作る投影とAttention計算の1単位です。
複数headを使うことで、モデルは異なる関係を並列に見られます。
| headで見たい関係の例 | 説明 |
|---|---|
| 近いtoken関係 | 直前・直後の局所的なつながり |
| 主語と述語 | 離れた位置にある構文的な関係 |
| 指示語 | 「これ」「それ」が何を指すか |
| 言い換え・意味関係 | 意味的に近いtokenのつながり |
Transformer baseでは、\(d_\mathrm{model}=512\)、head数 \(h=8\)、各headの次元 \(d_k=64\) です。
大きな512次元のAttentionを1つ使うのではなく、64次元のAttentionを8個計算して結合します。
実装イメージ:PyTorchで書くScaled Dot-Product Attention
以下は、Self-Attentionの中心計算だけをPyTorchで書いた例です。
実務では torch.nn.functional.scaled_dot_product_attention を使う場面も増えていますが、数式とtensor形状を対応させるには手書き実装が役立ちます。
import logging
from typing import Optional
import torch
from torch import Tensor
logger = logging.getLogger(__name__)
def scaled_dot_product_attention(
query: Tensor,
key: Tensor,
value: Tensor,
attention_mask: Optional[Tensor] = None,
) -> Tensor:
"""Compute scaled dot-product attention.
Args:
query: Query tensor with shape `(batch, heads, query_length, head_dim)`.
key: Key tensor with shape `(batch, heads, key_length, head_dim)`.
value: Value tensor with shape `(batch, heads, key_length, head_dim)`.
attention_mask: Optional boolean mask broadcastable to
`(batch, heads, query_length, key_length)`. `True` means visible.
Returns:
Tensor with shape `(batch, heads, query_length, head_dim)`.
Raises:
ValueError: If `key` and `value` have different sequence lengths.
ValueError: If `query` and `key` have different head dimensions.
Example:
>>> q = torch.randn(2, 8, 4, 64)
>>> k = torch.randn(2, 8, 4, 64)
>>> v = torch.randn(2, 8, 4, 64)
>>> out = scaled_dot_product_attention(q, k, v)
>>> out.shape
torch.Size([2, 8, 4, 64])
"""
if key.size(-2) != value.size(-2):
logger.error("key_length and value_length must match")
raise ValueError("key and value must have the same sequence length")
if query.size(-1) != key.size(-1):
logger.error("query and key head dimensions must match")
raise ValueError("query and key must have the same head dimension")
head_dim: int = query.size(-1)
scores: Tensor = query @ key.transpose(-2, -1)
scores = scores / (head_dim**0.5)
if attention_mask is not None:
logger.debug("applying attention mask before softmax")
# softmax前に消すことで、不可視位置へ確率質量が流れないようにするためです。
scores = scores.masked_fill(~attention_mask, torch.finfo(scores.dtype).min)
weights: Tensor = torch.softmax(scores, dim=-1)
logger.debug("computed attention weights", extra={"shape": tuple(weights.shape)})
return weights @ value
causal maskは次のように作れます。
from torch import Tensor
def build_causal_mask(sequence_length: int, device: torch.device) -> Tensor:
"""Build a causal attention mask.
Args:
sequence_length: Number of tokens in the sequence.
device: Device where the mask should be allocated.
Returns:
Boolean tensor with shape `(1, 1, sequence_length, sequence_length)`.
`True` means the key position is visible.
Raises:
ValueError: If `sequence_length` is less than 1.
Example:
>>> mask = build_causal_mask(3, torch.device("cpu"))
>>> mask[0, 0].int()
tensor([[1, 0, 0],
[1, 1, 0],
[1, 1, 1]], dtype=torch.int32)
"""
if sequence_length < 1:
logger.error("sequence_length must be positive")
raise ValueError("sequence_length must be positive")
token_positions: Tensor = torch.arange(sequence_length, device=device)
visible: Tensor = token_positions[:, None] >= token_positions[None, :]
logger.debug("built causal mask", extra={"sequence_length": sequence_length})
return visible.unsqueeze(0).unsqueeze(0)
Self-Attentionの計算量
Self-Attentionは、すべてのQuery位置とKey位置の組み合わせを比較します。
系列長を \(T\)、head次元を \(D\) とすると、score計算の主な計算量はおおよそ \(O(T^2D)\) です。
また、attention weightは (T, T) の行列になるため、メモリも \(O(T^2)\) で増えます。
| 系列長 | attention scoreの要素数 | 直感 |
|---|---|---|
| 1,000 | 1,000,000 | まだ扱いやすいことが多い |
| 8,000 | 64,000,000 | メモリが効き始める |
| 32,000 | 1,024,000,000 | 単純実装ではかなり重い |
この制約が、FlashAttention、Sparse Attention、Linear Attention、KV Cache、GQA/MQAといった後続技術につながります。
ただし、KV Cacheは学習時のSelf-Attention全体を軽くする技術ではなく、主にDecoder推論で過去tokenのKey/Valueを再利用するための仕組みです。
Transformer論文の実験結果をSelf-Attention目線で読む
論文では、TransformerがWMT 2014 English-to-Germanで28.4 BLEU、English-to-Frenchで41.8 BLEUを報告しています。
この結果は、Self-Attention単体の効果だけを切り出したものではありません。
Multi-Head Attention、Feed Forward、残差接続、Layer Normalization、Positional Encoding、学習設定を含むTransformer全体の結果です。
Self-Attentionの重要性を読むなら、次の点がポイントです。
| 観点 | 読み方 |
|---|---|
| 並列化 | RNNの逐次処理を避け、学習を並列化しやすくした |
| 長距離依存 | 1層で任意のtokenペアを直接比較できる |
| 表現力 | 複数headで異なる関係を同時に扱える |
| 限界 | 長文では \(O(T^2)\) の計算・メモリが課題になる |
現代LLMの会話性能を、当時のBLEUだけで直接説明することはできません。
それでも、Self-Attentionを中心にした構造が、後の大規模言語モデルへつながったことは重要です。
よくある誤解
| 誤解 | 正確な見方 |
|---|---|
| Self-Attentionは単語の意味を辞書のように取り出す | 実際にはtoken表現同士のスコアから重み付き和を作る計算 |
| attention weightを見れば理由が完全に分かる | 参照傾向は見えるが、因果的な説明としては慎重に扱う必要がある |
| Multi-Head Attentionは単に同じ計算を8回繰り返すだけ | headごとに別の投影行列を持ち、異なる表現空間で関係を見られる |
| maskはsoftmax後に掛ければよい | softmax前に不可視位置を極小値にするのが基本 |
| Self-Attentionだけで語順が分かる | 位置情報は別途Positional EncodingやRoPEなどで与える必要がある |
| KV Cacheで学習時の \(O(T^2)\) が消える | KV Cacheは主に自己回帰推論で過去のKey/Valueを再利用する仕組み |
まとめ
Self-Attentionは、同じtoken列の中で各tokenが他のtokenを重み付きで参照する計算です。
Scaled Dot-Product Attentionでは、\(QK^T / \sqrt{d_k}\) で参照スコアを作り、softmaxで重みに変換し、その重みでValueを混ぜます。
Multi-Head Attentionは、この計算を複数の表現空間で並列に行い、異なる関係を同時に扱えるようにします。
causal maskやpadding maskは、見てよい位置を制御するためにsoftmax前へ入れます。
Self-Attentionは強力ですが、全tokenペアを比較するため長文では \(O(T^2)\) の計算・メモリが課題になります。
LLMの高速化や長文対応を理解するには、このSelf-Attentionの基本形を押さえておくことが出発点になります。
関連技術
| 技術 | Self-Attentionとの関係 |
|---|---|
| Positional Encoding | Self-Attentionに語順情報を与える仕組み |
| RoPE | 現代LLMでよく使われる相対位置寄りの位置表現 |
| Decoder-only Transformer | causal mask付きSelf-Attentionを中心に次tokenを生成する構造 |
| KV Cache | 推論時に過去のKey/Valueを再利用する仕組み |
| FlashAttention | Attention計算のメモリアクセスを最適化する手法 |
| GQA/MQA | Query headとKey/Value headの数を調整し、推論メモリを抑える設計 |
次に読むべき記事
- LLMは語順をどう理解する?Positional EncodingとRoPEの基礎
- GPT系LLMの構造とは?Decoder-only Transformerをやさしく解説
- KV Cacheとは?LLMの生成を高速化する仕組み
- FlashAttentionとは?Attentionを高速化する技術

コメント