概念図:実際の製品回路を理解しやすく簡略化した図。
CPUとGPUの違いは、「CPUは逐次処理、GPUは並列処理」という二分法だけでは説明できません。
CPUにもマルチコア、SMT(Simultaneous Multithreading、1つの物理コアで複数の命令列を扱う仕組み)、SIMD(Single Instruction Multiple Data、1命令で複数データを処理する方式)、AVX、AVX-512、AMX(Advanced Matrix Extensions、行列演算向け拡張)があります。
本記事では、CPUとGPUの違いを、コア数ではなく、制御回路、キャッシュ、演算器、SIMT、warp、メモリ待ちの隠し方という回路構成から整理します。
本記事の目的
この記事の目的は、CPUとGPUの違いを「CPUは遅い、GPUは速い」「GPUはコア数が多い」という説明で終わらせないことです。
CPUとGPUは、どちらも現代的な並列計算機です。
ただし、設計上の優先順位が違います。
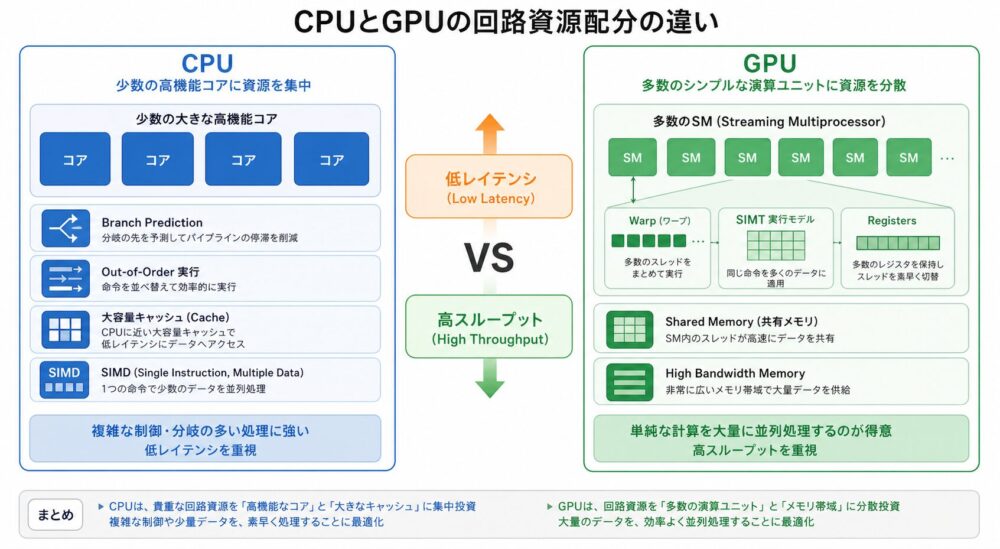
CPUは、OS、制御処理、分岐の多いプログラム、少量データの処理を低レイテンシ(待ち時間が短いこと)で進めるために、少数の高機能コアへ多くの制御回路とキャッシュを割きます。
GPUは、行列積、畳み込み、画像処理、映像処理、物理シミュレーション、AIのように、同じ演算を大量データへ繰り返す処理で高スループット(単位時間あたりの処理量が大きいこと)を出すために、多数の演算器、多数warp、SIMT実行、高帯域メモリへ回路資源を割きます。
この記事は、CPU、GPU、NPU(Neural Processing Unit、ニューラルネットワーク向けアクセラレータ)の役割分担を理解するための基礎記事です。
3文要約
CPUは、少数の高機能コアと複雑な制御回路によって、不規則で分岐の多い処理を低レイテンシに実行します。
GPUは、多数の演算器と多数warp(NVIDIA GPUで通常32 threadからなる実行単位)を使い、同じ演算を大量データへ適用することで高スループットを得ます。
GPUの本質は単なるコア数の多さではなく、制御、キャッシュ、演算器、メモリ待ちの隠し方における設計方針の違いです。
論文・一次資料情報
本記事は単一論文の要約ではありません。
CUDAの並列実行モデル、GPU computingの初期整理、NVIDIA公式CUDA資料、Intel公式最適化資料を組み合わせ、CPUとGPUの違いを説明します。
| 種別 | タイトル | 著者・組織 | 年 | この記事で参照する内容 | リンク |
|---|---|---|---|---|---|
| 技術論文 | Scalable Parallel Programming with CUDA | John Nickolls, Ian Buck, Michael Garland, Kevin Skadron | 2008 | CUDAのthread、thread block、shared memory、GPUで大量並列処理を表現する基本思想 | Scalable Parallel Programming with CUDA |
| 論文 | GPU Computing | John D. Owens, Mike Houston, David Luebke, Simon Green, John E. Stone | 2008 | GPUをデータ並列計算装置として捉える背景、GPUが得意なワークロード、CPUとの役割分担 | GPU Computing |
| 公式ガイド | CUDA C++ Programming Guide | NVIDIA | 2026年確認版 | SIMT、thread hierarchy、warp、SM、shared memory、GPUメモリモデル | CUDA C++ Programming Guide |
| 公式ガイド | CUDA C++ Best Practices Guide | NVIDIA | 2026年確認版 | 並列化、メモリスループット、occupancy(SM上に同時滞在するwarpやblockの多さ)、coalescing、branch divergence | CUDA C++ Best Practices Guide |
| 公式マニュアル | Intel 64 and IA-32 Architectures Optimization Reference Manual | Intel | 2024 | CPUの命令レイテンシ、スループット、out-of-order実行、分岐、キャッシュ、SIMD、AVX系最適化 | Intel 64 and IA-32 Architectures Optimization Reference Manual |
この記事での切り分け
| 区分 | 本記事での扱い |
|---|---|
| 論文・公式資料が示している事実 | CUDAのthread hierarchy、GPUが多数軽量threadを扱うこと、CPU/GPUで最適化対象が異なること |
| 世代依存の仕様 | SM内の演算器数、cache容量、Tensor Coreの形状、warp scheduler数、AVX/AMX対応可否 |
| 理解を助ける比喩 | CPUを少数の熟練作業者、GPUを多数の作業レーンとして説明する部分 |
| 筆者による解釈 | 「本質はコア数ではなく回路資源配分」という整理 |
CPUとGPUの違いを一言で整理する
CPUとGPUは、優劣ではなく、最適化対象が異なります。
注意点として、CPUの1コアとGPUの1 CUDA Coreは同じ単位ではありません。
CPUコアは、命令フェッチ、分岐予測、命令デコード、スケジューリング、out-of-order実行、キャッシュ、複数の実行器を含む大きな実行単位です。
一方、CUDA Coreは主に演算レーンとして扱われる要素であり、SM(Streaming Multiprocessor、GPU内の実行資源)やwarp scheduler、register file、shared memory、メモリ階層と一体で見なければ実行単位を理解できません。
| 観点 | CPU | GPU |
|---|---|---|
| 最適化対象 | 低レイテンシ | 高スループット |
| 基本思想 | 少数の処理を素早く完了する | 同種の処理を大量に同時実行する |
| コア | 少数・高機能 | 多数・比較的軽量 |
| 制御回路 | 複雑 | 相対的に軽量 |
| メモリ待ち対策 | キャッシュ、投機実行、out-of-order実行 | 多数warpへの切り替え |
| 分岐処理 | 得意 | warp内の分岐で効率が低下しやすい |
| 得意な処理 | OS、制御、不規則処理、少量処理 | 行列積、画像、映像、畳み込み、大量反復 |
| 並列処理 | マルチコア、SMT、SIMD | SIMT、多数warp、多数演算器 |
CPUの回路構成:なぜ複雑な処理を素早く実行できるのか
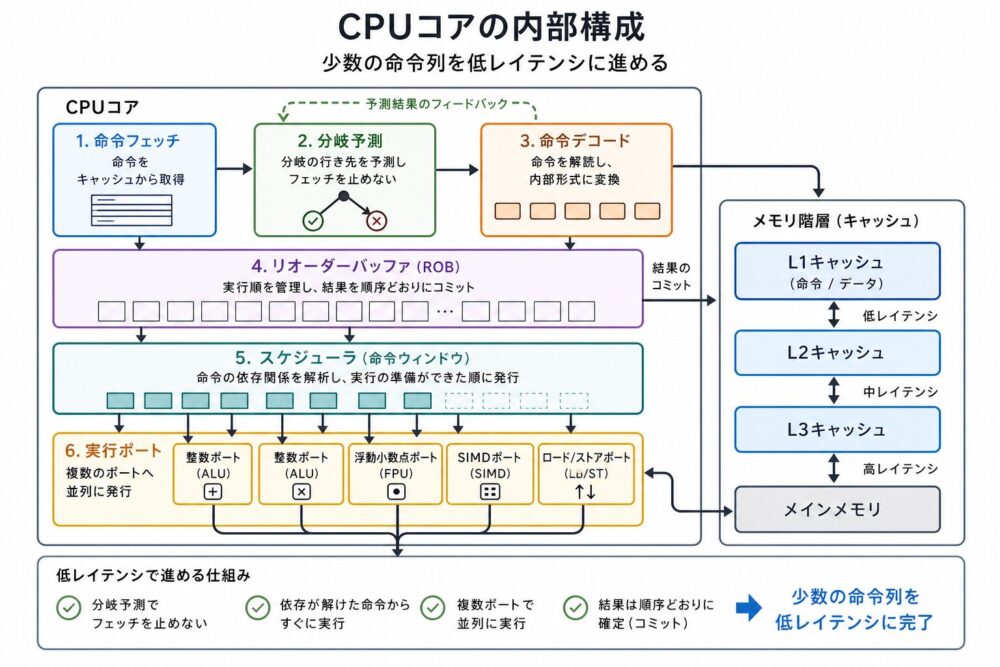
CPUコアは、少数の命令列を高速に進めるために複雑な制御回路を持ちます。
たとえば、現代的な高性能CPUでは、次のような仕組みが重要です。
| 構成要素 | 役割 | なぜ低レイテンシに効くか |
|---|---|---|
| 分岐予測 | if文やloopの進み先を予測する | 分岐結果を待たずに先の命令を準備できる |
| 投機実行 | 予測した経路の命令を先に実行する | 予測が当たると待ち時間を隠せる |
| out-of-order実行 | プログラム順とは別に実行可能な命令を先に出す | メモリ待ちや依存の少ない命令を先に進められる |
| 命令デコード | 複雑な命令を内部で扱いやすい形へ変換する | 実行器へ効率よく命令を供給する |
| 実行ポート | ALU、FPU、load/store、SIMDなどへ命令を発行する | 複数種類の処理を並行して進める |
| キャッシュ階層 | L1/L2/L3 cacheで近い場所にデータを置く | DRAMアクセスの頻度と待ち時間を減らす |
IntelのOptimization Reference Manualは、命令のレイテンシとスループット、メモリアクセス、分岐、SIMD命令の使い方を最適化対象として扱います。
これは、CPUが「1命令ずつ素朴に順番実行する装置」ではないことを示しています。
CPUは、分岐予測や投機実行で将来の経路を予測し、out-of-order実行で独立した命令を先に進め、cacheでDRAMアクセスを減らします。
つまり、CPUは少数の命令列を賢く高速化するために、多くの回路資源を制御と近接メモリへ使っています。
CPUにも並列計算機能がある
「CPUは逐次処理だけ」という説明は不正確です。
CPUには、少なくとも次の並列性があります。
| CPUの並列化方式 | 概要 | GPUとの違い |
|---|---|---|
| マルチコア | 複数のCPUコアで処理する | コア数はGPUの演算レーンほど多くないが、各コアが高機能 |
| SMT | 1つの物理コアで複数threadの実行資源を共有する | GPUの多数warp保持とは規模と目的が異なる |
| SIMD | 1命令で複数データを処理する | GPUのSIMTと似た面があるが、プログラミングモデルと実行単位が異なる |
| AVX / AVX2 / AVX-512 | x86系CPUの広いベクトル命令 | 対応幅や性能はCPU世代に依存する |
| AMX | 行列演算向けのタイル型拡張 | AI推論や行列演算に寄せたCPU側の拡張 |
CPUの強みは、少量、不規則、分岐が多い、低レイテンシが求められる処理です。
OSの制御、I/O、タスクスケジューリング、ユーザー操作への応答、条件分岐の多いビジネスロジックなどでは、CPUの複雑な制御回路が効きます。
GPUの回路構成:なぜ大量並列計算に強いのか
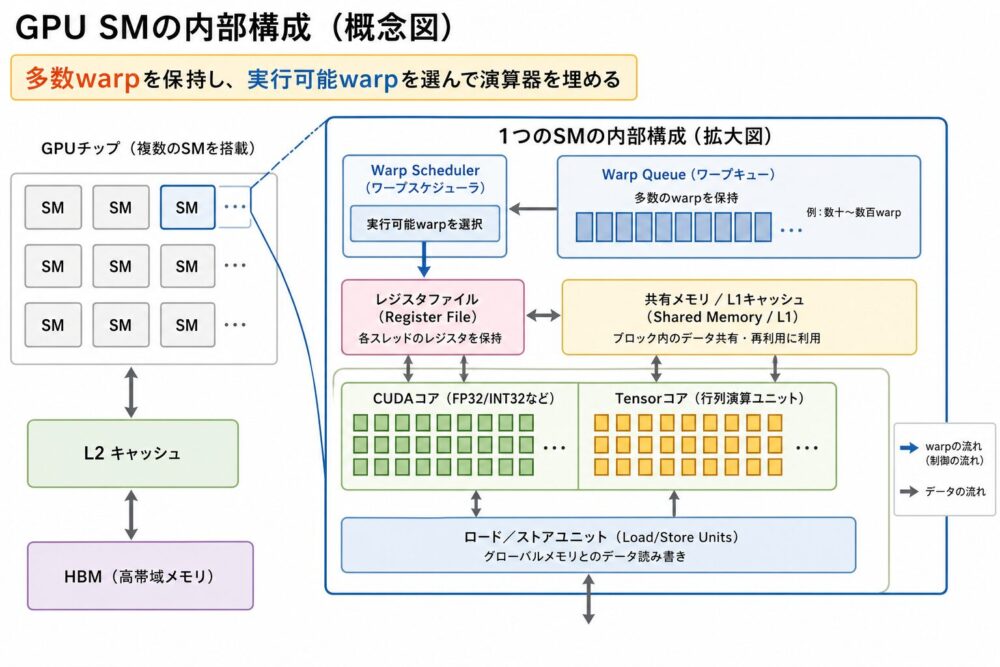
GPUは、多数のSMから構成されます。
SMの中には、Warp Scheduler、Registers(threadごとの値を保持する近接保存領域)、Shared Memory(thread block内で共有できるオンチップメモリ)、演算器群、load/store unit、Tensor Core(行列積和に特化した演算器)などがあります。
CUDA論文では、CUDAがthread group hierarchy、shared memory、barrier synchronizationを提供し、thread blockを独立にスケジュールできる構造として説明されています。
CUDA Programming GuideとCUDA Best Practices Guideでも、GPUは多数の軽量threadを並列に実行し、大量データへ同じ処理を適用する設計として説明されています。
GPUは、CPUのように1本の命令列を複雑に最適化するより、多数のthreadとwarpを同時に保持し、実行可能なwarpを選んで演算器を埋める方向に設計されています。
ここで重要なのは、GPUが単に「CPUよりコア数が多い」だけではないことです。
GPUは、半導体面積、電力、回路資源を、複雑な制御回路よりも、並列演算器、register file、shared memory、L2 cache、高帯域メモリ、warp状態保持へ多く振り向けます。
そのため、GPUの実行単位はCUDA Core単体ではなく、SM、warp、scheduler、register file、shared memory、L2、HBM/GDDRを含む構成として見る必要があります。
SIMT、thread、warp、SM:GPUの並列実行単位
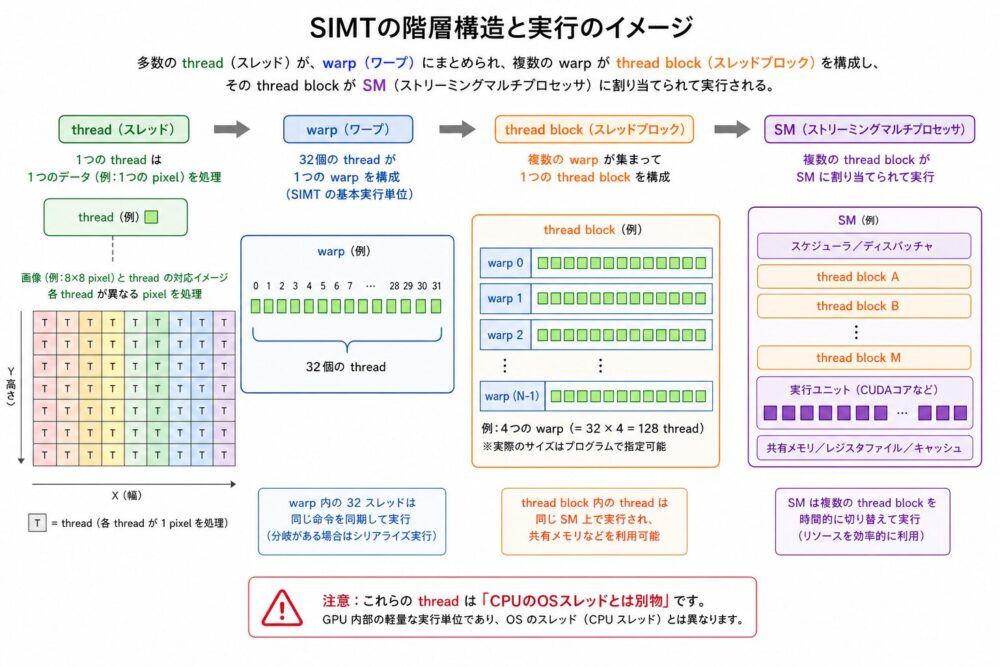
GPUの並列実行を理解するには、階層を分けて見る必要があります。
| 用語 | 概要 | 注意点 |
|---|---|---|
| thread | カーネル内でデータの一部を担当する論理実行単位 | CPUのOSスレッドと同一視しない |
| warp | NVIDIA GPUで通常32 threadからなる実行単位 | warp内threadは基本的に同じ命令を実行する |
| thread block | 複数threadをまとめた単位 | 同じblock内ではShared Memoryを共有できる |
| SM | warpやthread blockを実行するGPU内の実行資源 | scheduler、register file、shared memory、演算器を含む |
| Warp Scheduler | 実行可能なwarpを選んで命令を発行する回路 | メモリ待ちを隠す鍵になる |
| SIMT | Single Instruction Multiple Thread | SIMDに近いが、threadという抽象を持つ |
NVIDIA GPUでは、warpは通常32 threadで構成されます。
warp内の32 threadは、基本的に同じ命令を実行し、異なるデータを処理します。
画像処理で考えると、各threadが異なるpixelやfeature map(ニューラルネットワークの中間特徴マップ)の位置を担当します。
たとえば、1つのwarpが32個のpixelに同じフィルタ処理を適用する、という見方ができます。
CPUのSIMDも、1命令で複数データを処理するため、この点では似ています。
ただし、GPUのSIMTは、CUDA threadというプログラミング上の抽象を持ち、warp単位で実行され、SM上に多数のwarpを常駐させる点が異なります。
CPUとGPUは、メモリ待ちをどう隠すか
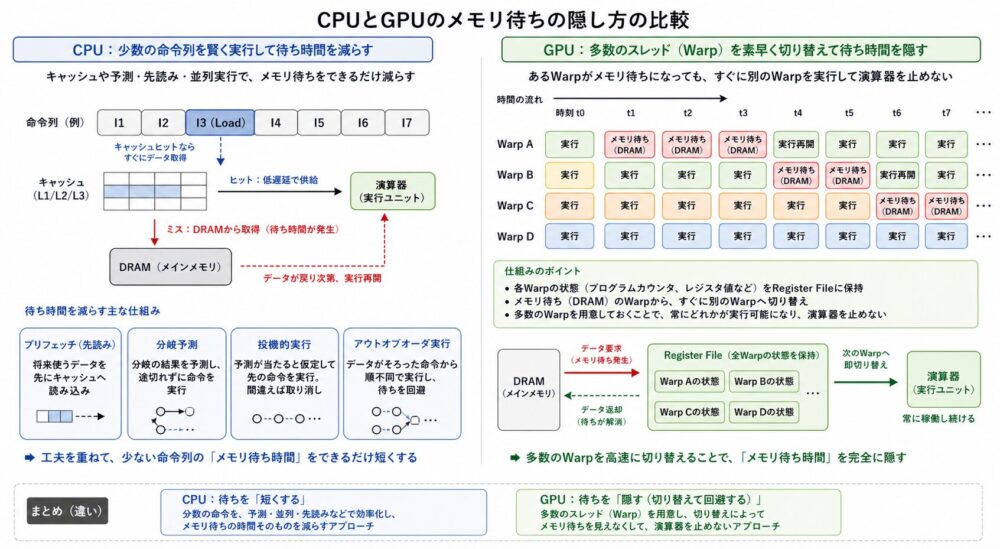
CPUとGPUの違いは、メモリ待ちの隠し方にも表れます。
CPUの場合
CPUは、少数の命令列を低レイテンシに処理するために、待ち時間をできるだけ減らします。
| 仕組み | 役割 |
|---|---|
| 大きなcache階層 | DRAMへ行く回数を減らす |
| prefetch | 将来使いそうなデータを先に読む |
| 分岐予測 | 分岐結果を待たずに先の命令を準備する |
| 投機実行 | 予測した経路を先に実行する |
| out-of-order実行 | 待っていない命令を先に進める |
CPUは、少数の命令列を賢く高速化することで待ち時間を減らします。
GPUの場合
GPUは、待ち時間そのものを完全になくすより、多数warpを切り替えることで待ち時間を隠します。
| 仕組み | 役割 |
|---|---|
| 多数warpをSM内へ常駐 | 実行候補を多く持つ |
| warp切り替え | あるwarpがDRAM待ちなら別warpを実行する |
| register file | active threadの状態をオンチップに保持する |
| Shared Memory / L2 | 遠いメモリへのアクセスを減らす |
| memory coalescing | 連続したアクセスをまとめ、帯域を使いやすくする |
GPUは、待っているwarpを一時停止し、別のwarpを実行することで待ち時間を隠します。
CUDA Best Practices Guideは、CPU threadが比較的重くcontext switchが高コストなのに対し、GPU threadは軽量で、あるwarpが待つと別warpを実行できることを説明しています。
warp divergence:GPUが苦手な分岐処理
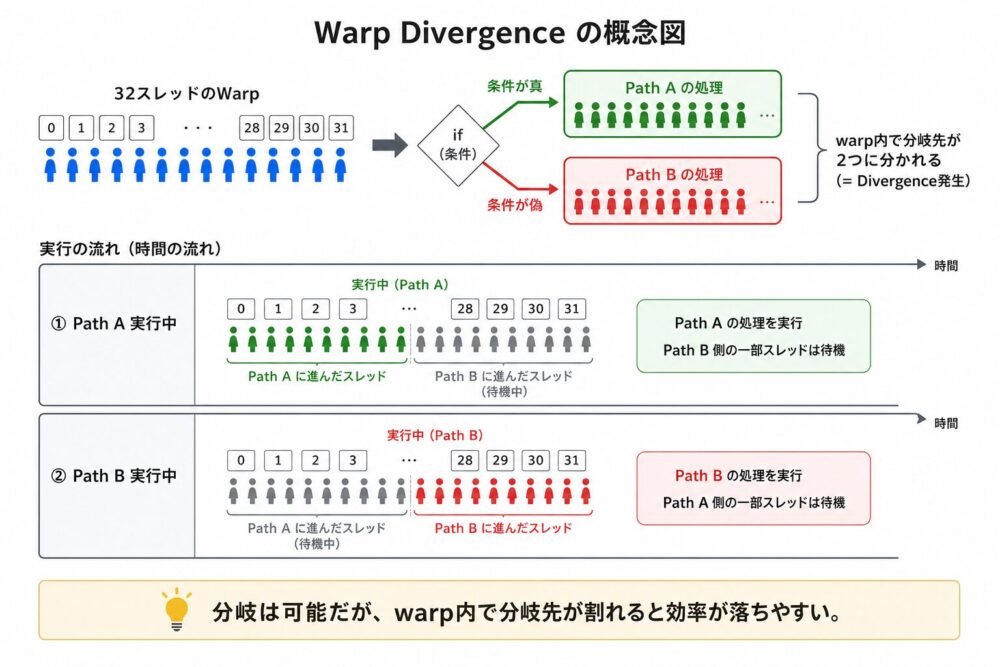
GPUにも分岐処理能力はあります。
ただし、warp内のthreadが同じ分岐へ進む場合と、threadごとに異なる分岐先へ進む場合では効率が違います。
warp内の32 threadが同じ分岐先へ進むなら、GPUは効率よく実行できます。
一方、warp内でthreadごとに分岐先が異なると、GPUは各分岐経路を順番に実行する必要があります。
片方の分岐を実行中は、もう片方のthreadが実質的に待機します。
これをwarp divergence(warp内の分岐先が割れて実行効率が落ちる現象)と呼びます。
不規則な分岐、ポインタ追跡、木構造、グラフ探索、少量処理でGPUが不利になりやすいのは、このような実行単位とメモリアクセスの性質が関係します。
ただし、「GPUでは分岐を使えない」は誤解です。
分岐は実行できます。
問題は、warp内で分岐先が細かく割れたときに、演算器の利用効率が下がりやすいことです。
| よくある誤解 | 正確な情報・解釈 |
|---|---|
| GPUはCPUより常に高速 | 大量の同型データ並列処理で強いが、不規則処理ではCPUが有利になり得る |
| GPUはコア数が多いから速い | 本質は演算器、SIMT、メモリ帯域、多数warp、回路資源配分の組み合わせ |
| CPUは並列処理できない | CPUもマルチコア、SMT、SIMD、AVX、AMXを持つ |
| GPUは分岐を実行できない | 実行可能だが、warp内で分岐先が異なると効率が落ちやすい |
| CUDA CoreはCPUコアと同じ | CUDA Coreは主に演算レーンであり、CPUコアとは回路規模・役割が異なる |
| GPUはキャッシュを使わない | GPUにもL1/L2 cacheがあり、Shared MemoryやRegistersと組み合わせて使う |
行列積・畳み込み・画像処理でGPUが強い理由
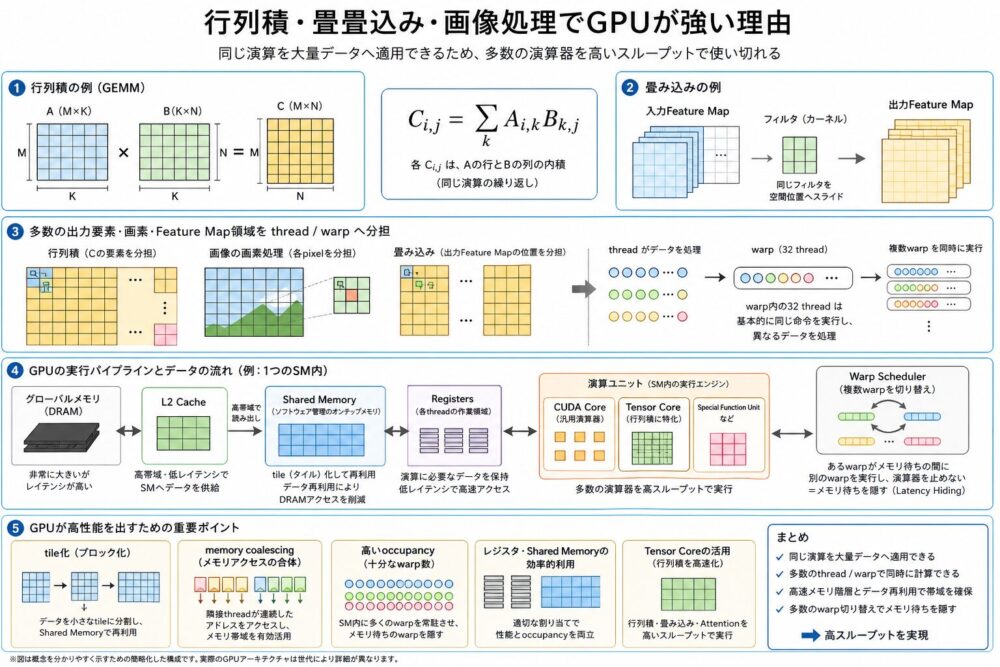
概念図:多数の出力要素やpixelをthread/warpへ分担できる。
行列積は、GPUが得意な処理を理解する代表例です。
\[ C_{i,j} = \sum_k A_{i,k}B_{k,j} \]
この式では、多数の \( C_{i,j} \) を並列に計算できます。
たとえば、あるthreadやwarpがC行列の一部、pixelの一部、feature mapの一部を担当します。
畳み込み、Attention(入力同士の関係を重み付けして集約する処理)、画像フィルタ、粒子シミュレーションにも、同じ演算を大量データへ繰り返す構造があります。
ただし、GPU性能は演算器数だけでは決まりません。
Shared Memory、Registers、L2、memory coalescing、tile化によって、演算器へデータを供給し続ける必要があります。
Tensor Coreは、行列積をさらに高速に実行する専用演算器です。
ただし、Tensor Coreの入力形状、対応精度、命令形式、性能はGPU世代に依存します。
カメラAI・画像処理でのCPUとGPUの役割分担
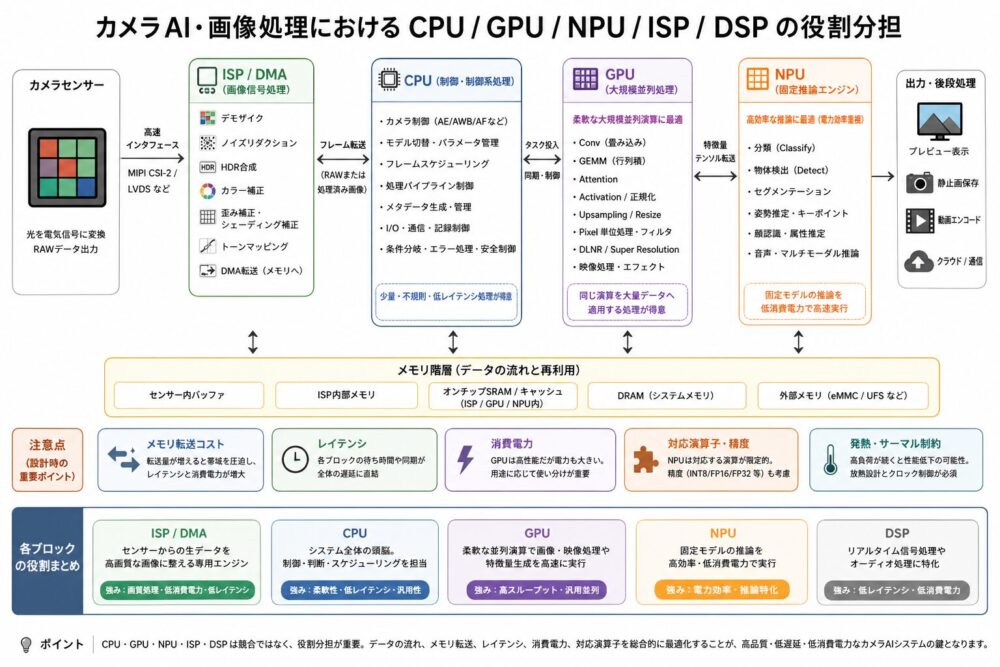
概念図:カメラAIではメモリ転送、レイテンシ、消費電力、対応演算子も重要になる。
カメラAIでは、CPUとGPUは競合するだけではなく、役割分担します。
| 処理 | CPUが向く理由 | GPUが向く理由 |
|---|---|---|
| カメラ制御 | 条件分岐、I/O、例外処理が多い | 主担当ではない |
| モデル切り替え | 状態管理や判断が必要 | 大量演算部分は担当できる |
| フレームスケジューリング | レイテンシ制約を見ながら制御する | kernel実行を担当 |
| ISP・DMA・I/O制御 | デバイス制御に向く | 演算に集中する |
| Conv / GEMM | 小規模ならCPUでも可能 | 大規模な同型演算に強い |
| Attention | 制御はCPU、演算はGPUに分けやすい | 行列積とsoftmax周辺で効きやすい |
| Activation / Upsampling | 制御はCPU | pixelやfeature map単位の処理に向く |
DLNR(Deep Learning Noise Reduction、深層学習ノイズ低減)、Demosaic(カラーフィルタ配列からRGBを復元する処理)、Super Resolution(超解像)、動画処理では、大量のpixelやfeature mapへ似た処理を繰り返すため、GPUが活用されやすくなります。
実際のカメラシステムでは、CPU、GPU、NPU、ISP(Image Signal Processor、画像信号処理器)、DSP(Digital Signal Processor、信号処理向けプロセッサ)が役割分担します。
GPUだけが速ければよいわけではありません。
メモリ転送、ISPとの接続、レイテンシ、消費電力、対応演算子、ドライバ、ランタイム、メモリ共有方式も重要です。
CPU・GPU・NPUの位置づけ
CPU、GPU、NPUは競合するだけの関係ではありません。
実際のAIシステムでは、制御はCPU、大規模で柔軟な並列演算はGPU、固定的で電力効率を重視する推論はNPU、という形で役割分担されることが多くなります。
| 観点 | CPU | GPU | NPU |
|---|---|---|---|
| 主な強み | 制御、低レイテンシ、汎用性 | 柔軟な大規模並列処理 | 行列積・畳み込みの高効率推論 |
| 並列化方式 | マルチコア、SMT、SIMD | SIMT、warp、SM | PE Array、Dataflow、Systolic Array |
| 柔軟性 | 高い | 高いがGPUプログラミングが必要 | 比較的限定的 |
| 電力効率 | 用途次第 | 高い並列性能 | 固定モデル推論で高くなりやすい |
| 得意な処理 | 制御・不規則処理 | 大量データ並列 | 規則的なAI推論 |
GPUは柔軟です。
研究段階のモデル、独自演算、動的shape、未確定の処理フローではGPUが便利です。
NPUは、対応演算子やデータフローには制約がありますが、固定的な畳み込みや行列積を高効率に処理しやすい設計です。
まとめ
CPUは、複雑で不規則なプログラムを少数の高機能コアで低レイテンシに処理するための回路構成です。
GPUは、同じ演算を大量データへ適用する処理に対し、多数の演算器と多数warpの切り替えによって高スループットを得るための回路構成です。
GPUの本質は、単なるコア数の多さではなく、制御、キャッシュ、演算器、メモリ帯域、並列実行単位への回路資源の配分がCPUと異なる点にあります。
「CPUは逐次処理、GPUは並列処理」とだけ覚えると、CPUのSIMDやAMX、GPUの分岐効率、メモリ帯域、warp schedulingの重要性を見落とします。
より正確には、CPUは少数の不規則な処理を低レイテンシに進める設計であり、GPUは大量の同型処理を高スループットに進める設計です。
関連技術
| 関連技術 | 概要 |
|---|---|
| CPU | 汎用プロセッサ。制御、不規則処理、低レイテンシ処理に強い |
| GPU | 大量データ並列処理向けプロセッサ。SIMTと多数演算器で高スループットを狙う |
| CUDA | NVIDIA GPU向けの並列計算プラットフォームとプログラミングモデル |
| SIMT | Single Instruction Multiple Thread。多数threadが基本的に同じ命令を異なるデータへ適用する方式 |
| SIMD | Single Instruction Multiple Data。1命令で複数データを処理する方式 |
| thread | CUDA kernel内の論理実行単位 |
| warp | NVIDIA GPUで通常32 threadからなる実行単位 |
| thread block | 複数threadをまとめ、Shared Memoryを共有できる単位 |
| SM | Streaming Multiprocessor。warp、scheduler、register、shared memory、演算器を含むGPU実行資源 |
| Warp Scheduler | 実行可能なwarpを選び、命令を発行する回路 |
| warp divergence | warp内threadの分岐先が割れ、効率が落ちる現象 |
| branch prediction | CPUが分岐先を予測する仕組み |
| speculative execution | 予測した経路を先に実行する仕組み |
| out-of-order execution | 実行可能な命令をプログラム順と異なる順序で進める仕組み |
| cache hierarchy | L1/L2/L3などの近接メモリ階層 |
| Shared Memory | CUDA thread block内で共有できるオンチップメモリ |
| Registers | threadごとの値を保持する近接保存領域 |
| Tensor Core | NVIDIA GPUの行列積和向け専用演算器 |
| NPU | ニューラルネットワーク推論向けアクセラレータ |
| Systolic Array | データを隣接PEへ規則的に流しながら計算する配列構造 |
次に読むべき記事
| 記事 | リンク | 読む理由 |
|---|---|---|
| GPUはなぜ行列積をtile化するのか | GPUの行列積はなぜタイル化するのか?warp・Shared Memory・Tensor Coreから理解する | 本記事のGPU側を、GEMMとtile化に絞って深掘りする |
| GPUとNPUは何が違うのか | https://kasblo.com/ai-paper/npu-systolic-array-dataflow/ | GPUとNPUの設計思想を比較する |
| NPUはなぜPE Array内でデータ再利用しやすいのか | NPUはなぜDRAMアクセスを減らしやすいのか?PE ArrayとSystolic ArrayをGPUとの違いから理解する | NPU側のデータフローとPE Arrayを理解する |
| TPUv1・TPUv2・TPUv3の推論・学習対応の違い | https://kasblo.com/ai-paper/tpu-v1-v2-v3-training-inference/ | TPU世代ごとの推論・学習対応を理解する |
| Tensor Coreとは何か | https://kasblo.com/ai-paper/gpu-tiled-gemm-warp-tensor-core/ | GPUの行列積専用演算器を深掘りする |
| warp、thread、SMとは何か | https://kasblo.com/ai-paper/gpu-tiled-gemm-warp-tensor-core/ | CUDA実行単位を単独で復習する |
コメント