学習率とは?DALS論文で見る最適化手法の進化と使い分け
3文要約

この論文は、学習率(モデルの重みを1回の更新でどれだけ動かすかを決める値)の設計が、固定値からスケジューリング、パラメータ単位、層単位、層と時間を同時に扱う設計へ進化してきた流れを整理した研究です。
著者らは、DALS(Discriminative Adaptive Layer Scaling、層と学習フェーズに応じて勾配処理を変える最適化手法)を提案し、cosine scheduling、Grokfast、LARSの考え方を1つの枠組みに統合しています。
実験では、DALSがsyntheticタスクで98.0%の最高精度を示す一方、NLPのfine-tuning(事前学習済みモデルを追加学習すること)ではRAdamなどのadaptive optimizerが強く、論文では「どの学習率戦略も全タスクで万能ではない」と示されています。
論文情報
| 項目 | 内容 |
|---|---|
| 論文タイトル | Learning Rate Engineering: From Coarse Single Parameter to Layered Evolution |
| 著者 | Ming-Hong Yao, Di Wang, Jian Cui, Jin-Yan Chen, Zi-Hao Cui, Fa Wang, Chen Wei, Qiu-Ye Yu |
| 発表年 | 2026年 |
| arXiv | arXiv:2604.27295v1 |
| 公開日 | 2026年4月30日 |
| 分野 | AI, Machine Learning, Optimization |
| 論文リンク | Learning Rate Engineering: From Coarse Single Parameter to Layered Evolution |
本記事の目的
Deep Learningでは、モデル構造やデータセットに注目が集まりがちです。
しかし、実際にモデルを学習させると、 「学習率を少し変えただけで精度が大きく変わる」 「fine-tuningではAdamWが安定するのに、scratch学習ではSGD系が強いことがある」 「下層と上層で同じ学習率を使ってよいのか迷う」 という問題に何度も出会います。
この論文は、こうした現場感のある悩みを、 学習率設計の進化として整理しています。
単にDALSという新しい手法を紹介するだけではなく、 SGD、cosine decay、Adam、LARS、STLR、RAdam、Grokfastなどが、 それぞれどの問題を解決しようとしてきたのかを見通せる点が面白い論文です。
学習率とは何か
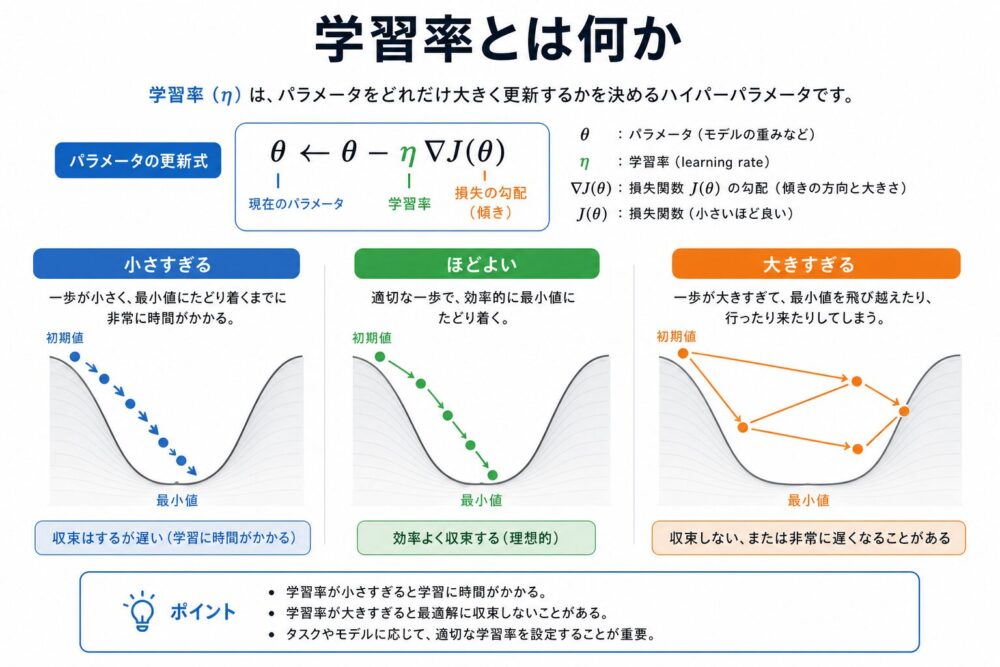
学習率は、gradient descent(損失が小さくなる方向へパラメータを更新する方法)における更新幅です。
基本式は次のように書けます。
\[
\theta_{t+1} = \theta_t – \eta \nabla_\theta J(\theta_t)
\]
ここで、\(\theta_t\)は時刻\(t\)のモデルパラメータ、 \(\nabla_\theta J(\theta_t)\)は損失関数の勾配、 \(\eta\)が学習率です。
直感的には、学習率は「坂道を下るときの歩幅」です。
| 学習率 | 起きやすいこと | 直感 |
|---|---|---|
| 大きすぎる | 損失が発散する、最小値を飛び越える | 大股で歩きすぎて谷を通り過ぎる |
| 小さすぎる | 学習が遅い、局所的な改善に時間がかかる | 小刻みに進みすぎて目的地に着かない |
| ほどよい | 速さと安定性のバランスが取れる | 最初は大きく進み、近づいたら慎重に進む |
問題は、ニューラルネットワークのすべての層にとって、 「ほどよい歩幅」が同じとは限らないことです。
論文解説
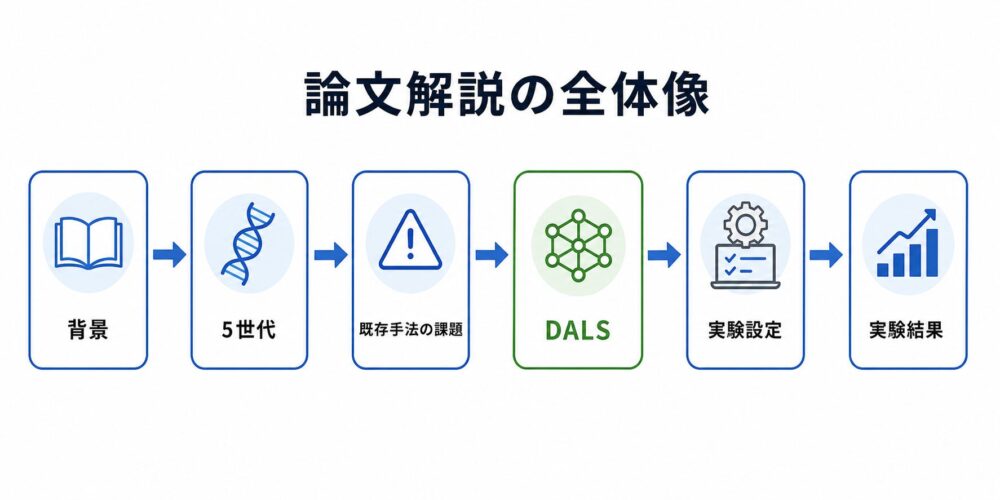
ここからは、論文本文で扱われている内容を順に整理します。
まず単一学習率の課題を確認し、 次に学習率戦略の5世代、 既存手法の限界、 提案手法であるDALS、 実験設定と結果を見ていきます。
背景:単一の学習率では全層を満足させにくい
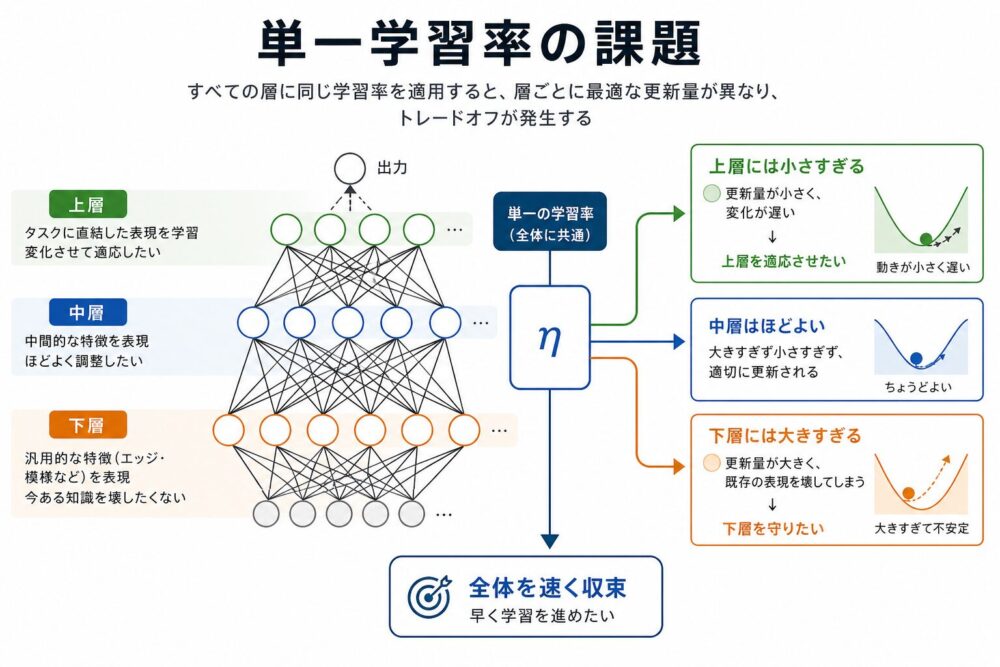
論文では、単一学習率の難しさを「impossible trinity」として説明しています。
ここでのtrinityは、 次の3つを同時に満たすことの難しさです。
| 要求 | 望ましい学習率 | 理由 |
|---|---|---|
| 下層の一般知識を保つ | 小さい学習率 | 事前学習済み特徴を壊したくない |
| 上層をタスクに素早く適応させる | 大きい学習率 | 新しい分類器やタスク固有表現を早く学びたい |
| 全体の収束を速くする | 状況に応じた学習率 | 初期は大きく、終盤は小さくしたい |
たとえば、画像モデルの下層はエッジや色のような汎用特徴を扱い、 上層は犬、車、病変、商品カテゴリのようなタスク固有特徴を扱います。
LLMやBERT系モデルでも同じです。 下層はtokenの局所的な構文や語彙情報、 上層はタスクに近い意味表現や分類境界に関わることがあります。
すべての層に同じ学習率を使うと、 下層には大きすぎるが、上層には小さすぎる、 という状態が起きます。
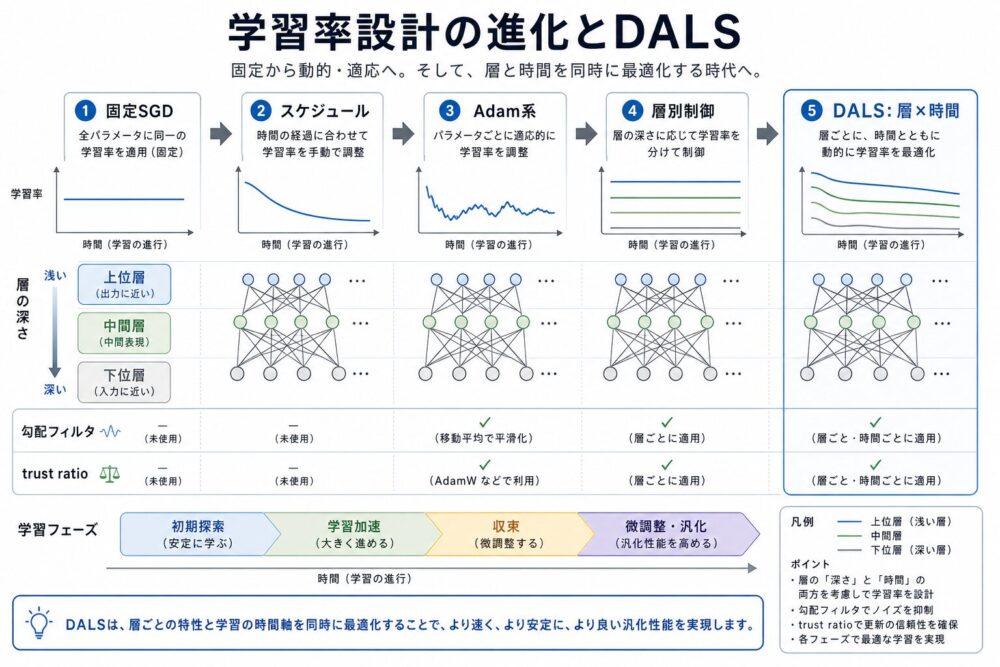
学習率戦略の5世代

論文の大きな貢献の1つは、学習率戦略を5世代に分けて整理している点です。
| 世代 | 粒度 | 代表例 | 何を改善したか | トレードオフ |
|---|---|---|---|---|
| Gen1 | 全パラメータで固定 | Fixed SGD | 実装が単純で挙動を読みやすい | タスクや学習段階に合わせにくい |
| Gen2 | 全体学習率を時間で変更 | Step decay, Cosine decay, SGDR | 初期は速く、終盤は安定させやすい | 層ごとの差は扱えない |
| Gen3 | パラメータ単位 | AdaGrad, RMSProp, Adam, AdamW | 勾配履歴に応じて自動調整できる | 訓練レジームによって汎化差が出る |
| Gen4 | 層単位 | Discriminative LR, LARS, LAMB | 下層と上層で更新幅を変えられる | 固定的な層バイアスが悪く働く場合がある |
| Gen5 | 層と時間の同時制御 | STLR, RAdam, Lookahead, SAM, Grokfast, DALS | 学習段階と層の役割を同時に扱える | 実装とハイパーパラメータが複雑になる |
この整理で重要なのは、 世代が進むほど「どの単位で学習率や勾配を制御するか」が細かくなることです。
初期のSGDでは、 すべてのパラメータが同じ\(\eta\)を共有します。
cosine decayでは、 時間\(t\)に応じて全体の学習率を変えます。
Adamでは、 各パラメータの勾配履歴を見て更新量を調整します。
LARSやdiscriminative fine-tuningでは、 層ごとに更新幅を変えます。
DALSはさらに、 層の深さと学習フェーズの両方を使って、 勾配処理の強さを変えます。
既存手法の課題
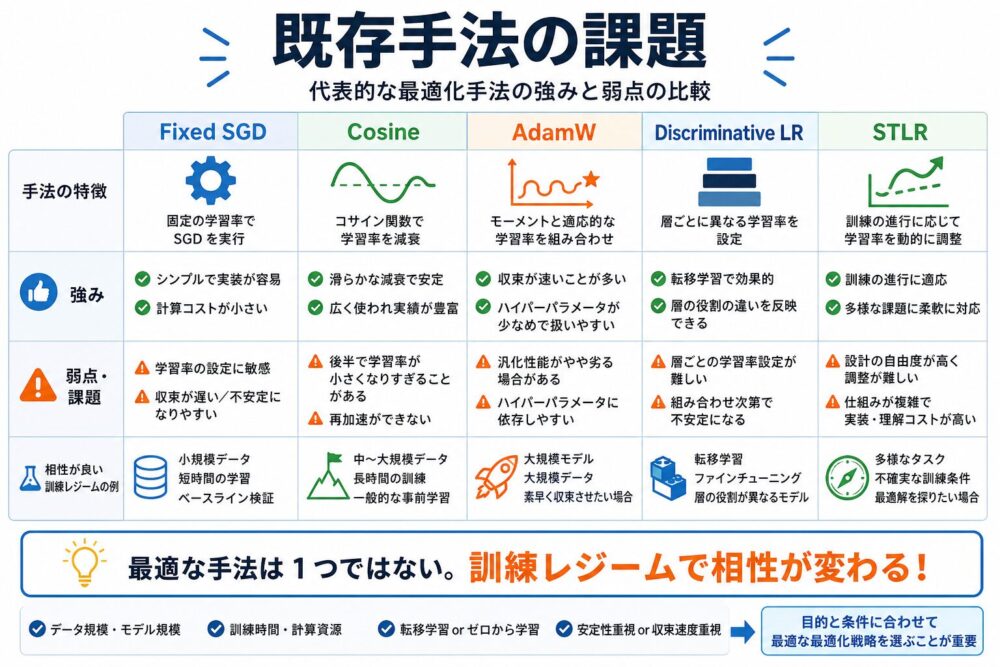
既存手法は、それぞれ明確な強みがあります。
ただし、論文では、 ある訓練レジームで有効なバイアスが、 別の訓練レジームでは悪く働くことを強調しています。
ここでの訓練レジームとは、 scratch training(ランダム初期化から学習すること)なのか、 fine-tuningなのか、 小規模データなのか、 大規模データなのか、 という学習条件のまとまりです。
| 手法 | 強み | 弱み | 向きやすい場面 |
|---|---|---|---|
| Fixed SGD | 単純でscratch学習で強い場合がある | 学習率調整が手動になりやすい | 小〜中規模のscratch学習 |
| Cosine decay | 終盤を安定させやすい | 層ごとの差は扱えない | 画像分類などのscratch学習 |
| Adam/AdamW | fine-tuningで扱いやすい | scratch学習でSGD系に負ける場合がある | Transformerのfine-tuning |
| Discriminative LR | 下層を保護しやすい | 下層も学ぶ必要があるscratchでは不利 | 事前学習済みモデルのfine-tuning |
| STLR+Discriminative | ULMFiT系のfine-tuningと相性がよい | scratchでは下層の学習率が小さくなりすぎる | pretrained特徴を保ちたい場合 |
| DALS | 層とフェーズを同時に扱う | 実装が複雑で検証範囲はまだ限定的 | scratchとfine-tuningの両方を意識した比較 |
特に面白いのは、 STLR+Discriminativeの失敗です。
Discriminative fine-tuningは、 上層ほど大きい学習率、 下層ほど小さい学習率を使います。
事前学習済みモデルでは、 下層に汎用特徴が入っているため、 これは合理的です。
しかし、scratch学習では下層もゼロから特徴を学ぶ必要があります。 このとき下層の学習率を強く抑えると、 下層が十分に動けず、モデル全体の学習が止まりやすくなります。
DALSとは何か
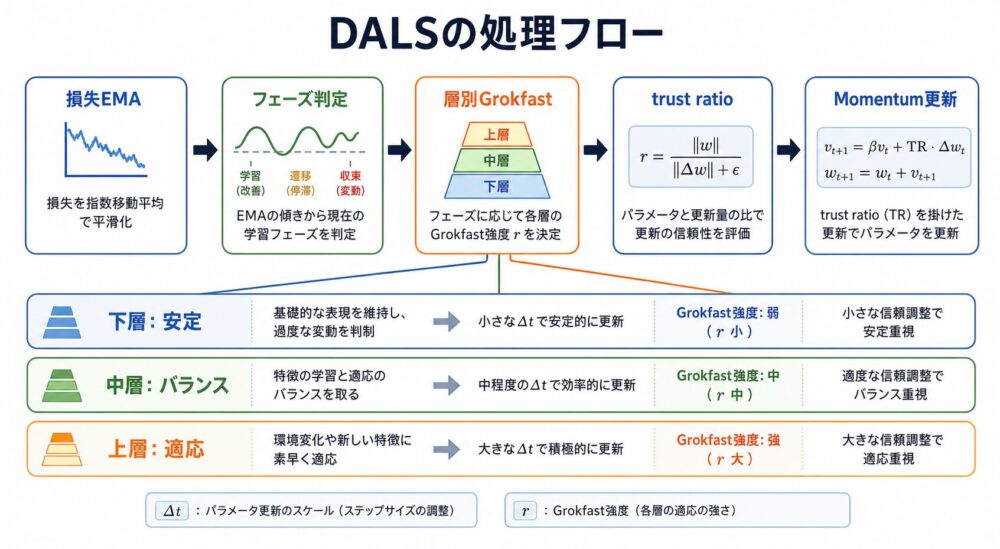
DALSは、 Discriminative Adaptive Layer Scalingの略です。
名前だけ見るとdiscriminative fine-tuningの派生に見えますが、 論文の主張では、 DALSは固定的に「下層を小さく、上層を大きく」する手法ではありません。
むしろ、 下層を常に抑える方向バイアスを避け、 学習フェーズと層の深さに応じて勾配処理を調整する手法です。
DALSは大きく4つの部品で構成されます。
| 部品 | 元になった考え方 | DALSでの役割 |
|---|---|---|
| Warmup + cosine schedule | Gen2の学習率スケジュール | 学習序盤の安定化と終盤の減衰 |
| Depth-aware Grokfast filtering | Grokfast | 層の深さと学習フェーズに応じて勾配を平滑化 |
| LARS-style trust ratio | LARS | パラメータノルムと勾配ノルムの比で更新量を調整 |
| Momentum update | SGD momentum | 勾配方向を安定させる |
DALSの仕組み1:学習フェーズを損失改善率で見る
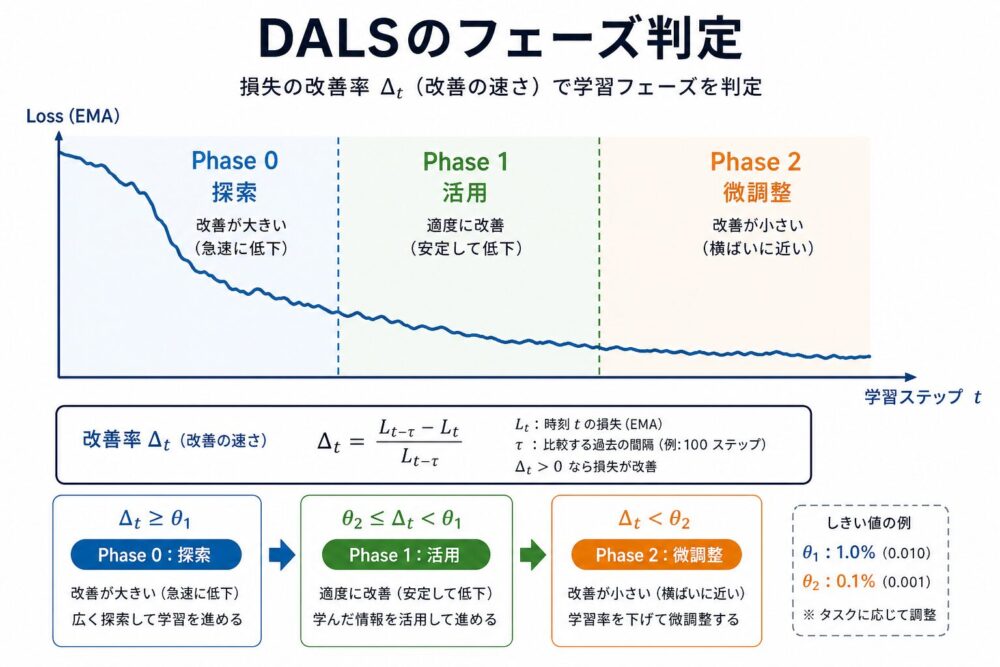
DALSでは、損失のEMA(Exponential Moving Average、指数移動平均)を使って、 現在の学習フェーズを見ます。
論文では、損失改善率を次のように表しています。
\[
\Delta_t =
\frac{
L^{\mathrm{ema}}_{t-1} – L^{\mathrm{ema}}_t
}{
|L^{\mathrm{ema}}_{t-1}|
}
\]
ここで、 \(L^{\mathrm{ema}}_t\)は時刻\(t\)の損失の指数移動平均です。
改善率\(\Delta_t\)に応じて、 学習フェーズを次のように分けます。
| フェーズ | 条件 | 意味 | 勾配処理の直感 |
|---|---|---|---|
| Phase 0 | \(\Delta_t > 0.01\) | Exploration | 損失が大きく下がっているので生の勾配を活かす |
| Phase 1 | \(0.002 < \Delta_t \le 0.01\) | Exploitation | ある程度安定して改善している |
| Phase 2 | \(\Delta_t \le 0.002\) | Refinement | 収束に近いためノイズを抑えたい |
ここがDALSの重要な点です。
学習率そのものはwarmup + cosine scheduleで変えますが、 フェーズ判定は主に勾配フィルタリングの強さに使われます。
つまり、 「今は勢いよく学んでいるから勾配を遅らせすぎない」 「終盤はノイズを抑えて慎重に更新する」 という制御を入れています。
DALSの仕組み2:層の深さで勾配の混ぜ方を変える
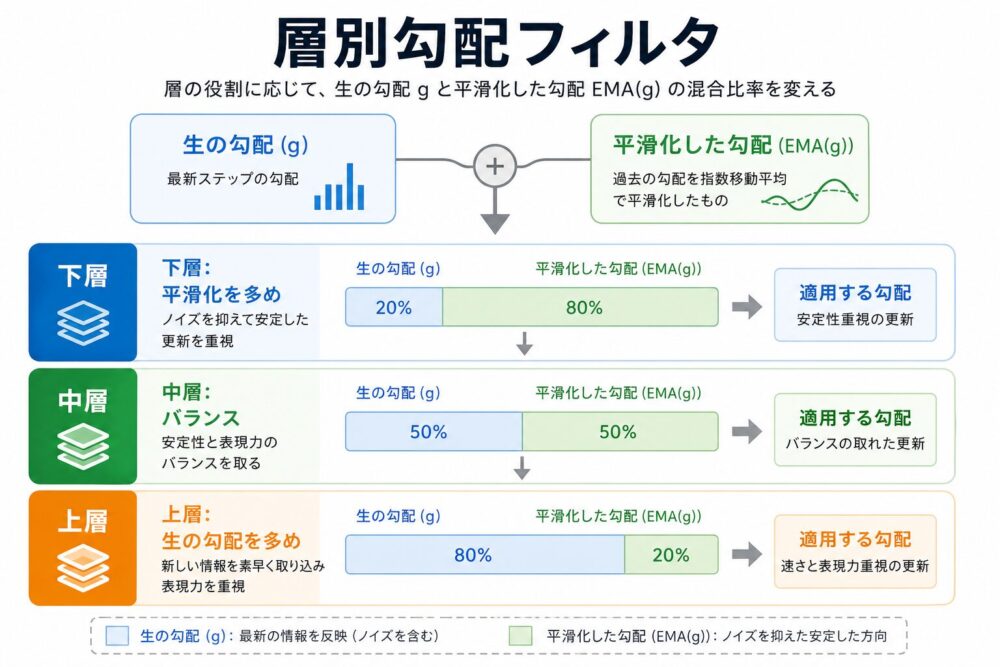
DALSでは、 各層の深さを\(d_l = l/(L-1)\)で表します。
下層は\(d_l \approx 0\)、 上層は\(d_l \approx 1\)です。
勾配のEMAを次のように更新します。
\[
\tilde{g}^l_t =
\alpha_l \tilde{g}^l_{t-1}
+ (1 – \alpha_l) g^l_t
\]
そのうえで、 生の勾配\(g^l_t\)と平滑化された勾配\(\tilde{g}^l_t\)を混ぜます。
\[
\hat{g}^l_t =
(0.3 + 0.4d_l)g^l_t
+ (0.7 – 0.4d_l)\tilde{g}^l_t
\]
この式から、 下層では平滑化された勾配の比率が大きくなり、 上層では生の勾配の比率が大きくなることが分かります。
直感的には、 下層は多くの層を通ってきたノイズの影響を受けやすいため安定性を重視し、 上層はタスク固有の変化に素早く反応させる、 という設計です。
DALSの仕組み3:LARS風のtrust ratioで更新量を整える
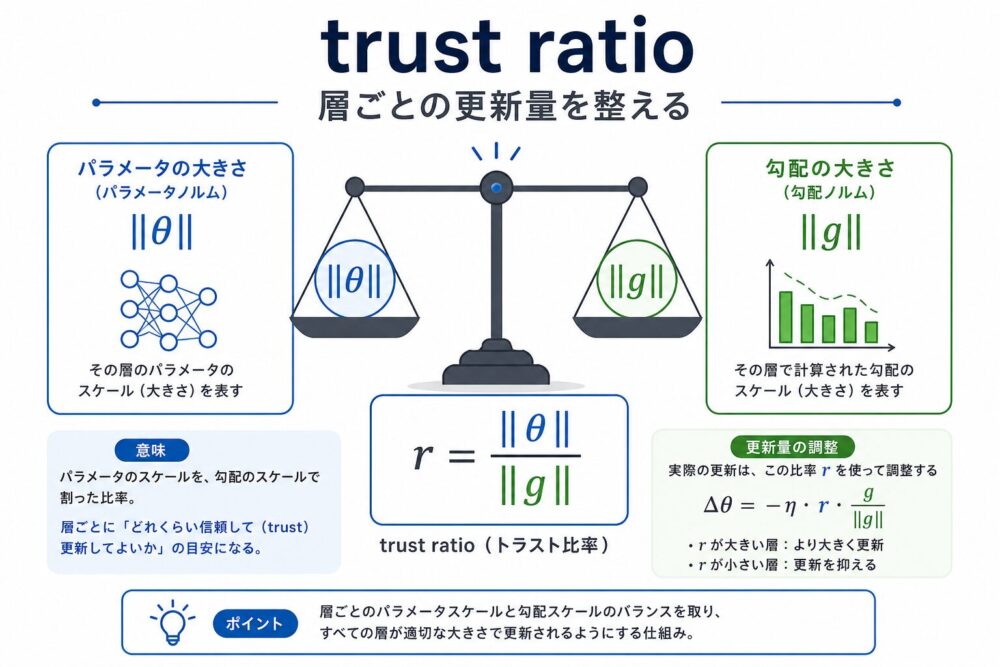
DALSは、LARS(Layer-wise Adaptive Rate Scaling、層ごとのノルム比で更新量を調整する方法)の考え方も使います。
論文では、trust ratioを次のように表します。
\[
r^l_t =
\mathrm{clamp}
\left(
\gamma
\frac{
\|\theta^l\|_2
}{
\|\hat{g}^l_t\|_2 + \epsilon
},
0.2,
5.0
\right)
\]
\(\gamma\)はtrust coefficientで、 論文では0.02が使われています。
clamp(値を指定範囲に切り詰める処理)で、 trust ratioが0.2から5.0の範囲に収まるようにします。
更新式は次のようになります。
\[
\theta^l_t =
\theta^l_{t-1}
– \eta^l_t r^l_t m^l_t
\]
ここで\(m^l_t\)はmomentumで平滑化された更新方向です。
trust ratioを入れることで、 パラメータの大きさに対して勾配が大きすぎる層を抑え、 逆に勾配が小さすぎる層を補正できます。
DALSの3つのバリエーション
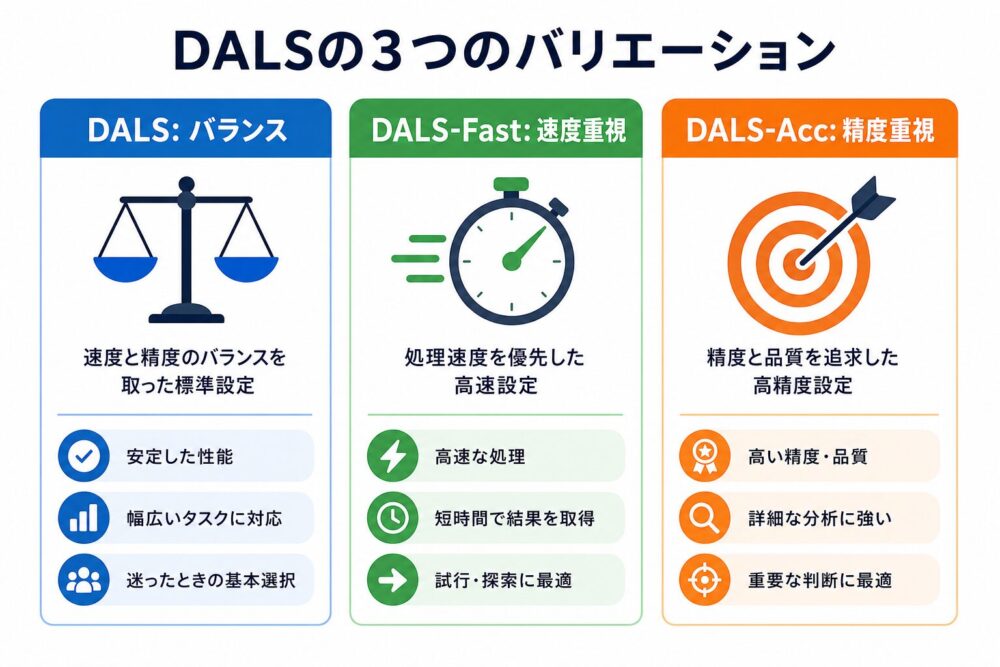
論文では、DALS本体に加えて、 速度重視と精度重視のバリエーションも評価しています。
| 手法 | 狙い | 主な変更 | 論文で示された傾向 |
|---|---|---|---|
| DALS | バランス型 | 標準設定 | syntheticで98.0% |
| DALS-Fast | 早期収束 | base LRを0.05に上げ、warmupを2%に短縮し、Phase 0でGrokfast filteringを回避 | syntheticで90%到達が3epoch |
| DALS-Acc | 精度重視 | SGDR風のwarm restart、weight decay増加、強めのGrokfast filtering | 長期学習で局所解回避を狙う |
ここで注意したいのは、 DALS-Fastが「常に最も良い」という意味ではない点です。
論文では、DALS-Fastは早く90%に届く一方で、 最終精度はDALS本体よりわずかに低いと示されています。
プロトタイピングではDALS-Fast、 最終モデルではDALSまたはDALS-Acc、 という使い分けが考えられます。
実験設定
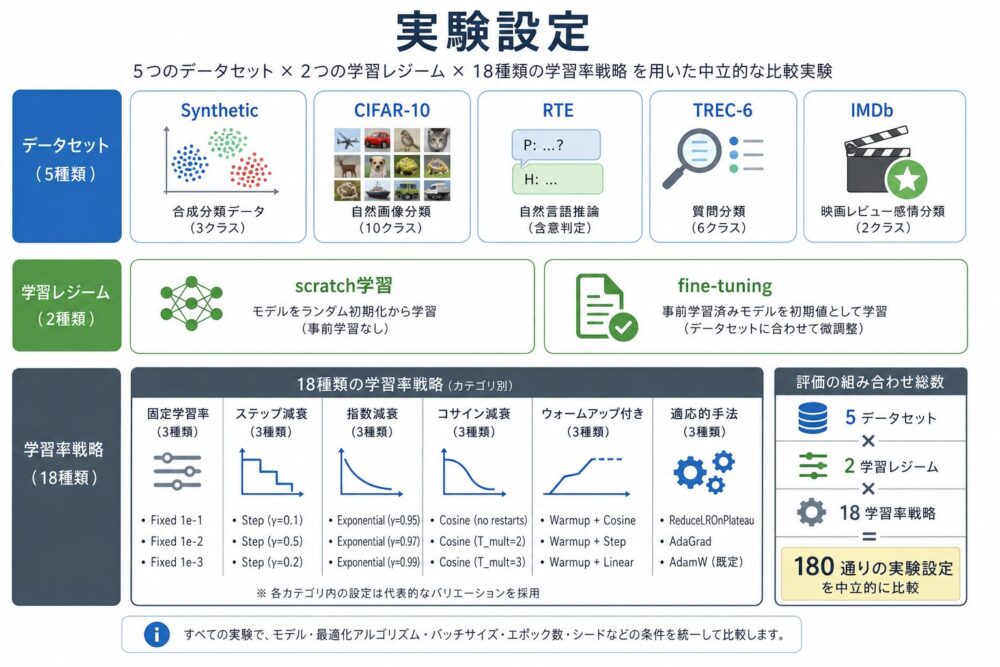
論文では、18種類の学習率戦略を5つのデータセットで比較しています。
| データセット | 訓練レジーム | モデル | 目的 |
|---|---|---|---|
| Synthetic | scratch | 4層MLP | 最適化挙動を見やすくする |
| CIFAR-10 | scratch | 小規模ConvNet | 画像分類のscratch学習を見る |
| RTE | fine-tuning | DistilBERT | 小規模NLUタスクを見る |
| TREC-6 | fine-tuning | DistilBERT | 質問分類を見る |
| IMDb | fine-tuning | DistilBERT | 感情分類を見る |
この構成は、 「単一のベンチマークで勝った手法」を探すというより、 どの手法がどの条件で強いのかを見る設計です。
実験結果:万能な学習率戦略はなかった
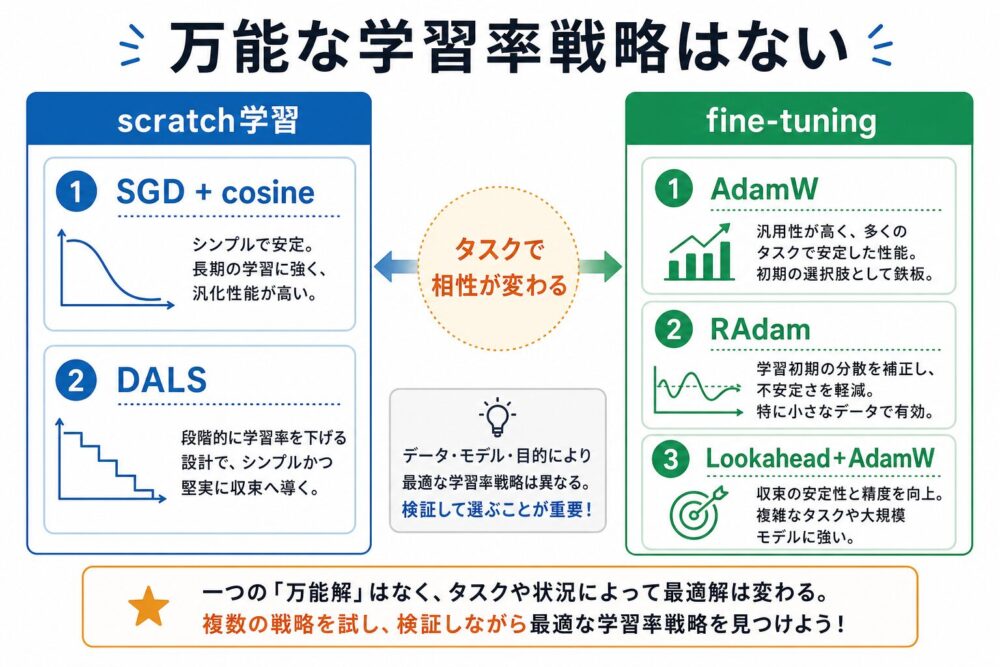
主要な結果を抜き出すと、次のようになります。
| 観点 | 論文で示された結果 | 読み方 |
|---|---|---|
| synthetic | DALSが98.0%で最高 | phaseとdepthを使う設計がscratchの単純タスクで効いた |
| CIFAR-10 | Cosine Decay SGDが80.2%で最高 | 画像分類のscratchではSGD系スケジュールが強い |
| RTE | RAdamが62.8%で最高 | 小規模fine-tuningではadaptive optimizerが有利 |
| TREC-6 | Adam、AdamW、Lookahead+AdamWが97.6% | Transformer fine-tuningではAdam系が安定 |
| IMDb | RAdamが91.2%で最高 | 大きめのNLP fine-tuningでもadaptive optimizerが強い |
論文の中心的な結論は、 「学習率戦略はタスクや訓練レジームに依存する」です。
DALSはsyntheticでは最良ですが、 CIFAR-10ではCosine Decay SGDに負けています。
また、NLP fine-tuningではRAdamやAdamW系が強く、 DALSは競争力はあるものの、全タスクでトップではありません。
これは実務上かなり重要です。
新しい最適化手法が出たとき、 「既存のoptimizerを全部置き換えるべきか」 と考えがちですが、 論文の結果はむしろ、 学習条件に合わせて選ぶべきだと示しています。
STLR+Discriminativeの失敗から分かること
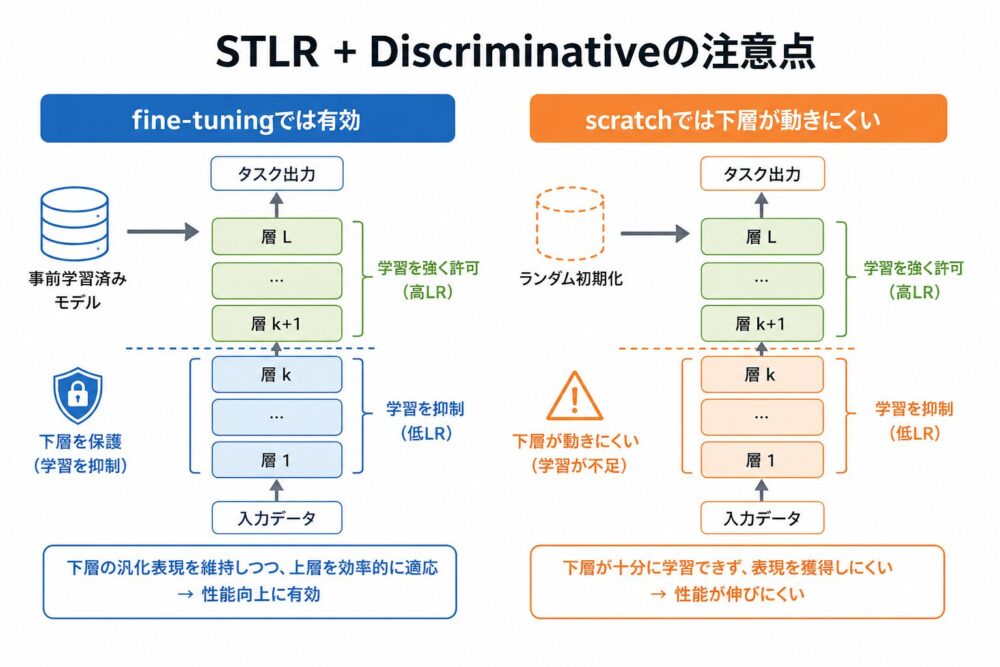
論文で特に印象的なのは、 STLR+Discriminativeが一部条件で大きく失敗している点です。
STLR(Slanted Triangular Learning Rate、序盤に急上昇し、その後ゆっくり減衰する学習率スケジュール)は、 ULMFiTで使われた手法です。
Discriminative fine-tuningと組み合わせると、 下層ほど小さい学習率、 上層ほど大きい学習率になります。
これはfine-tuningでは自然です。 下層の事前学習済み特徴を壊さず、 上層だけタスクに適応させやすいからです。
しかしscratch学習では、 下層にも十分に学習してもらう必要があります。
論文では、STLR+DiscriminativeがTREC-6で43.6%に落ちたことが報告されています。
この結果は、 「事前学習済みモデルを守るための設計」を、 「ランダム初期化から学ぶモデル」にそのまま使う危険性を示しています。
よくある誤解

| 誤解 | 正確な情報・解釈 |
|---|---|
| AdamWを使えば学習率設計は不要 | AdamWでもbase learning rate、warmup、weight decayの設計は重要です |
| fine-tuningで強い手法はscratchでも強い | 事前学習済み特徴を守る設計はscratchでは逆効果になることがあります |
| 層別学習率は常に下層を小さくすればよい | 下層が学習済み特徴を持つかどうかで意味が変わります |
| DALSは全ベンチマークで最高精度の手法 | 論文ではsyntheticで最高ですが、CIFAR-10やNLP fine-tuningでは別手法が上回ります |
| 学習率スケジュールだけを複雑にすればよい | 層、勾配ノイズ、パラメータノルムも更新の安定性に関わります |
高画質タスクへの応用を考える

Denoise(ノイズ除去)、Demosaic(ベイヤー配列からRGB画像を復元する処理)、Super Resolution(低解像度画像を高解像度化する処理)のような高画質タスクでも、 学習率設計は重要です。
高画質タスクでは、 低層がエッジ、テクスチャ、色の局所統計を扱い、 高層がシーン構造や意味的な補正を扱うことがあります。
そのため、 下層と上層で同じ学習率を使うと、 次のような問題が起きる可能性があります。
| 課題 | 起きること | DALS的な考え方での対策 |
|---|---|---|
| 下層が壊れる | エッジや色再現が不安定になる | 下層の勾配を平滑化して安定させる |
| 上層が適応しない | タスク固有の補正が遅い | 上層では生の勾配比率を高める |
| 終盤で画質が揺れる | PSNRやSSIMが伸びにくい | refinement段階で勾配ノイズを抑える |
| データセットが小さい | 過学習しやすい | trust ratioやweight decayとの併用を慎重に見る |
ただし、これは本論文の直接的な実験結果ではありません。
本論文では、DenoiseやSuper Resolutionのベンチマークは評価していません。
高画質タスクに使う場合は、 画像復元タスク特有の損失関数、 perceptual loss(人間の見た目に近い特徴空間で測る損失)、 patch学習、 データ拡張との相互作用を別途検証する必要があります。
実務での使い分け
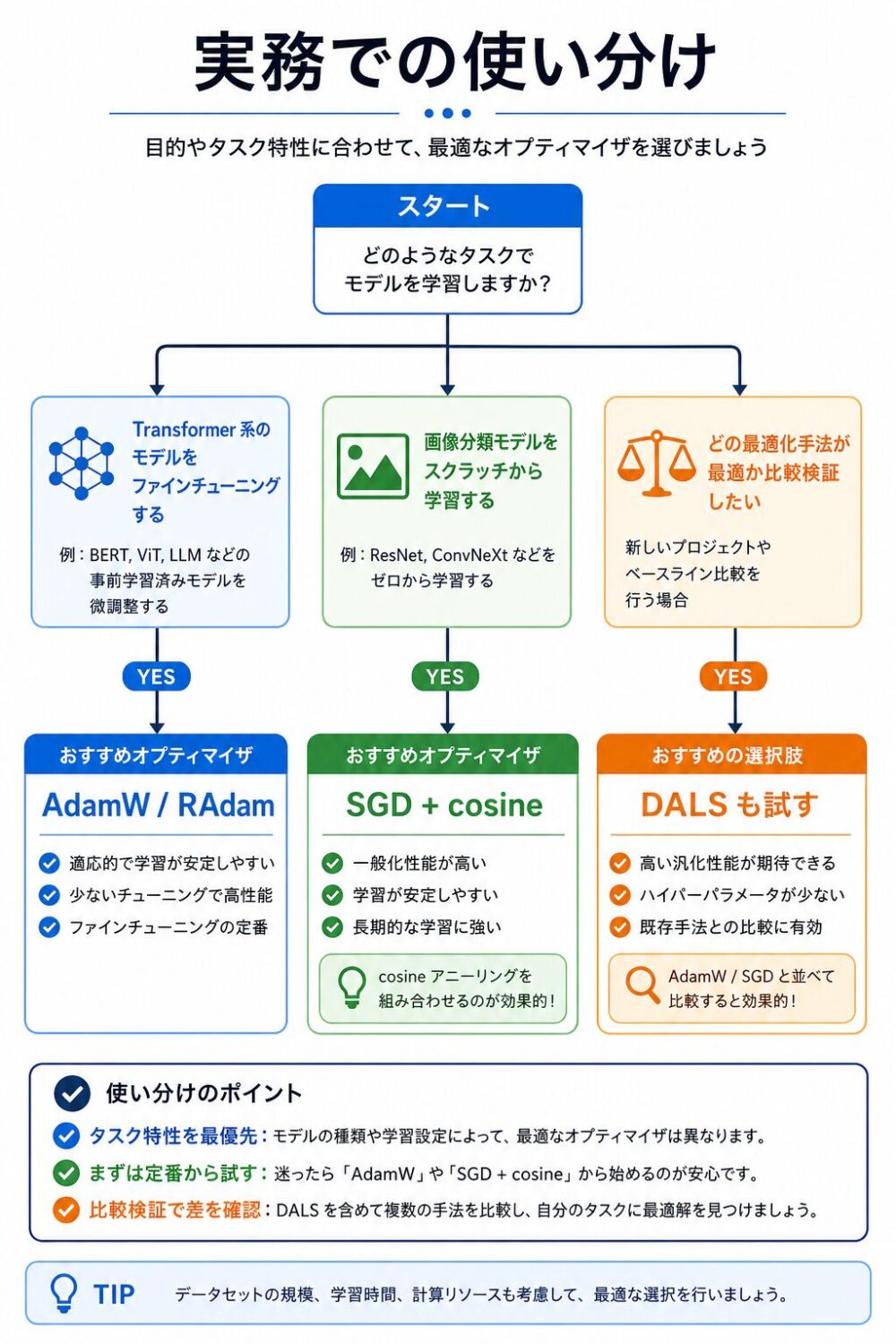
この論文から、すぐに使える判断軸を整理すると次のようになります。
| 状況 | まず試したい候補 | 理由 |
|---|---|---|
| Transformerをfine-tuningする | AdamW、RAdam、Lookahead+AdamW | 論文でもNLP fine-tuningでadaptive系が強い |
| 小〜中規模の画像分類をscratchで学習する | SGD + cosine decay | CIFAR-10ではCosine Decay SGDが最高 |
| 最適化挙動を比較したい | Fixed SGD、Cosine SGD、AdamW、DALSを並べる | レジーム差を見やすい |
| 下層を守りたいfine-tuning | Discriminative LR、STLR系 | 事前学習済み特徴を保つ目的に合う |
| scratchとfine-tuningの両方を1つの考え方で扱いたい | DALS | 固定的な下層抑制ではなくphase/depthで調整する |
実務では、 最初からDALSだけを使うより、 ベースラインとしてAdamWやSGD + cosine decayを置き、 DALSを比較対象に入れるのが安全です。
特に、論文の評価は16ページの比較実験として有用ですが、 大規模Transformer、Vision Transformer、拡散モデル、画像復元モデルでの検証は今後の課題として残っています。
関連技術
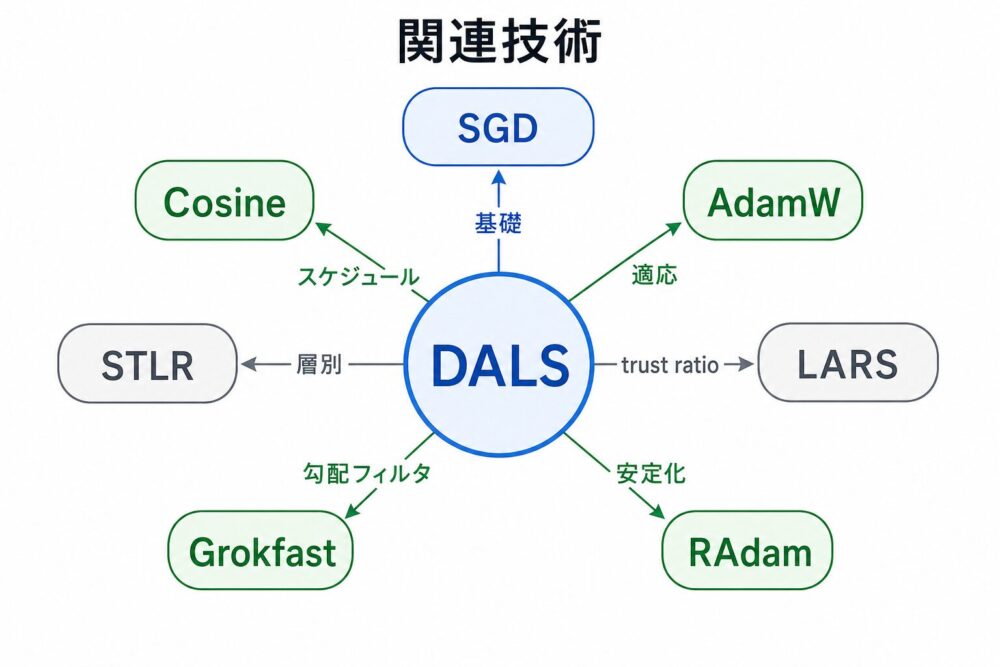
| 技術 | 概要 | DALSとの関係 |
|---|---|---|
| SGD | 勾配方向に一定幅で更新する基本手法 | DALSのmomentum updateの基礎 |
| Cosine Annealing | cos関数で学習率を滑らかに下げる | DALSのスケジュール要素 |
| AdamW | Adamからweight decayを分離した手法 | fine-tuningの強力な比較対象 |
| LARS | 層ごとのパラメータノルムと勾配ノルムで更新量を調整 | DALSのtrust ratioの元 |
| STLR | 序盤に急上昇し、その後ゆっくり下がる学習率 | DALSが避けたい固定的バイアスの比較対象 |
| Grokfast | 勾配の遅い成分を強調する手法 | DALSのgradient filtering要素 |
| RAdam | Adamの分散推定をwarmup的に補正する手法 | NLP fine-tuningで強い比較対象 |
まとめ
Learning Rate Engineering論文は、 学習率設計を単なるハイパーパラメータ調整ではなく、 「どの粒度で、いつ、どの層を、どれだけ動かすか」という設計問題として捉え直しています。
DALSは、 warmup + cosine schedule、 depth-aware Grokfast filtering、 LARS-style trust ratio、 momentum updateを組み合わせ、 固定的な「下層は小さく、上層は大きく」という方向バイアスを避けようとする手法です。
実験では、 DALSはsyntheticタスクで98.0%の最高精度を示し、 DALS-Fastは90%到達を3epochに短縮しています。
一方で、CIFAR-10ではCosine Decay SGD、 NLP fine-tuningではRAdamやAdamW系が強く、 論文全体としては「万能な学習率戦略はない」というメッセージが強く出ています。
実務で大事なのは、 新手法を万能薬として扱うことではありません。
scratch学習なのか、 fine-tuningなのか、 下層を守るべきなのか、 全層を積極的に学ばせるべきなのかを見極めて、 学習率戦略を選ぶことです。
関連記事へのリンク
- WindowQuantとは?動画VLMのKV Cacheを軽量化する混合精度量子化手法を解説
- 【論文解説】LLMはなぜ日本文化に寄りがちなのか?CROQで見る文化・地域バイアス
- 【LLM解説シリーズ】Transformerとは?Attention is All You Needをわかりやすく解説
次に読むべき記事
| 記事案 | 狙い |
|---|---|
| AdamWとは?Adamとの違いとweight decayをわかりやすく解説 | fine-tuningでよく使うoptimizerの基礎を整理する |
| Cosine Annealingとは?学習率スケジュールの仕組みを解説 | Gen2の代表手法を深掘りする |
| LARSとLAMBとは?大規模バッチ学習を支える層別スケーリング | DALSのtrust ratioの背景を理解する |
| RAdamとは?warmupなしで安定化を狙うAdam系最適化手法 | 論文でNLP fine-tuningに強かった手法を解説する |
| Grokfastとは?遅い勾配成分を強調する学習加速手法 | DALSのgradient filtering要素を掘り下げる |

コメント