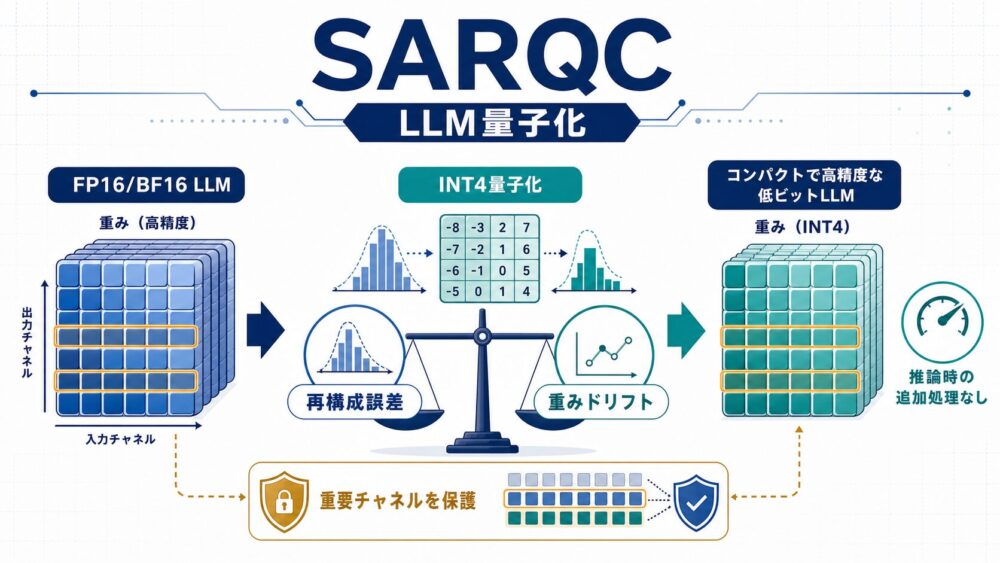
LLM(大規模言語モデル)をINT4やINT3へ量子化すると、モデルを小さくして推論を高速化できます。
しかし、少量のキャリブレーションデータ上で出力誤差だけを小さくしても、量子化後の重みが元の重みから大きくずれ、未知の入力で精度が落ちる場合があります。
本記事では、重みのずれを正則化し、重要なチャネルほど強く守るSARQC(Saliency-Aware Regularized Quantization Calibration)の仕組みを、数式、既存手法との違い、実験結果、実装上の注意点まで論文ベースで解説します。
3文要約
SARQCは、LLMの学習後量子化で使う再構成誤差に、元の浮動小数点重みからのずれを抑える正則化項を加える手法です。
すべての重みを一様に守るRQCを発展させ、活性化値と重みの統計から得たsaliency(出力への重要度)に応じて、重要なチャネルの重みドリフトを強く抑えます。
論文では、AWQ型のグリッド探索とGPTQ型のGramベース法の両方へ組み込め、特に2〜3bitやキャリブレーションデータが少ない条件でperplexity(次トークン予測の不確かさ)とzero-shot精度を改善し、推論時の追加処理は不要と報告しています。
論文情報
| 項目 | 内容 |
|---|---|
| 論文タイトル | Saliency-Aware Regularized Quantization Calibration for Large Language Models |
| 著者 | Yanlong Zhao, Xiaoyuan Cheng, Huihang Liu, Baihua He, Xinyu Zhang, Harrison Bo Hua Zhu, Wenlong Chen, Li Zeng, Zhuo Sun |
| 研究機関 | University of Science and Technology of China、University College London、Shanghai University of Finance and Economics、Imperial College Londonほか |
| 発表年 | 2026年 |
| arXiv提出 | 2026年5月7日、v2は2026年5月8日 |
| 論文リンク | Saliency-Aware Regularized Quantization Calibration for Large Language Models |
| arXiv PDF | |
| 公式実装 | Riceormice/SARQC |
本記事はv2を対象にします。
論文の実験結果と、筆者による実運用への解釈は分けて記載します。
本記事の目的
LLM量子化では、「何bitにするか」や「どの量子化形式を使うか」に注目しがちです。
一方、この論文は、量子化パラメータを決めるキャリブレーション目的関数そのものを見直しています。
本記事では、次の順番で整理します。
- weight-only PTQとキャリブレーションの基礎
- 再構成誤差だけでは不十分になり得る理由
- RQCが重みドリフトをどう抑えるか
- SARQCが重要なチャネルをどう保護するか
- AWQ型とGPTQ型の既存パイプラインへどう組み込むか
- denseモデルとMoEモデルでの実験結果
- 実サービスやエッジAIへ適用するときの注意点
対象読者は、LLMの量子化に関心があるAI初学者から、AWQやGPTQを利用するMLエンジニアまでです。
背景:LLMの学習後量子化とキャリブレーション
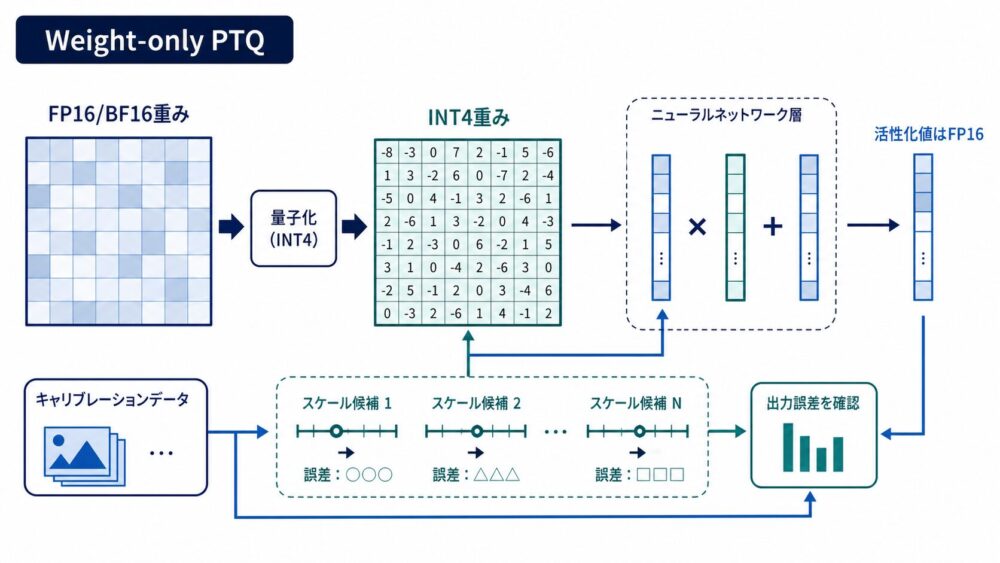
量子化は、FP16やBF16で表現された重みを、INT4などの少ないbit数へ写像する処理です。
論文が扱う対称量子化では、浮動小数点の重み \(w\) を次のように整数へ変換します。
\[
w_{\mathrm{INT-N}}
=
\mathrm{round}\left(
\frac{w_{\mathrm{FP16}}}{\eta}
\right),
\qquad
\eta
=
\frac{\max |w|}{2^{N-1}-1}
\]
\(N\) はbit数、\(\eta\) は量子化ステップです。
推論時には、整数重みを \(\widehat{w}=\eta w_{\mathrm{INT-N}}\) として近似的に復元し、浮動小数点の活性化値と計算します。
weight-only PTQ(重みだけを学習後に量子化する手法)は、活性化値を浮動小数点のまま保つため、モデルサイズとメモリ帯域を減らしつつ、既存のLLMへ比較的導入しやすい方法です。
ただし、丸めにより必ず誤差が生じます。
そこで、多くのPTQは少量のキャリブレーションデータをモデルへ通し、各層の量子化前後の出力が近くなるように、scale、zero point、clipping、丸め方などを決めます。
第 \(l\) 層の元の重みを \(\mathbf{W}_l\)、量子化後に逆量子化した重みを \(\widehat{\mathbf{W}}_l\)、キャリブレーション入力を \(\mathbf{X}_l\) とすると、標準的な目的は次の再構成誤差を最小化することです。
\[
\min_{\widehat{\mathbf{W}}_l \in \mathcal{Q}}
\left\|
\mathbf{W}_l\mathbf{X}_l
–
\widehat{\mathbf{W}}_l\mathbf{X}_l
\right\|_{\mathrm{F}}^2
\]
\(\mathcal{Q}\) は量子化方式から選べる重みの集合、\(\|\cdot\|_{\mathrm{F}}\) はFrobeniusノルム(行列要素の二乗和の平方根)です。
| 手法 | 主な探索・補正 | キャリブレーションで重視するもの |
|---|---|---|
| AWQ | 活性化統計に基づくチャネルscaleの探索 | 重要チャネルを考慮した出力再構成 |
| GPTQ | Gram行列を使う逐次的な重み誤差補正 | 層出力の二次近似誤差 |
| RQC | 既存目的に一様な重みドリフト正則化を追加 | 出力再構成と元の重みへの近さ |
| SARQC | saliencyで重み付けした正則化を追加 | 出力再構成と重要チャネルの保護 |
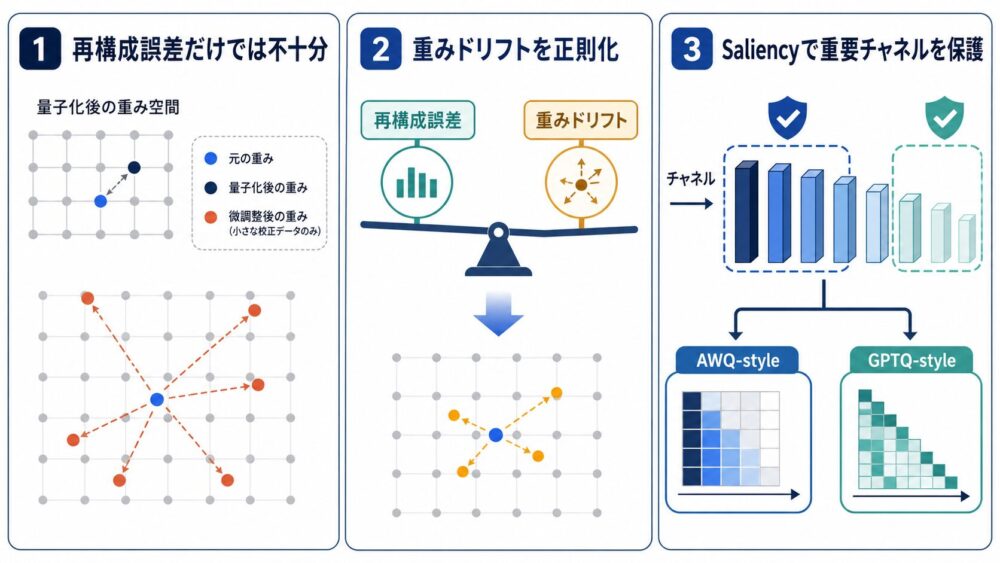
従来の量子化キャリブレーションはなぜ精度劣化を招くのか
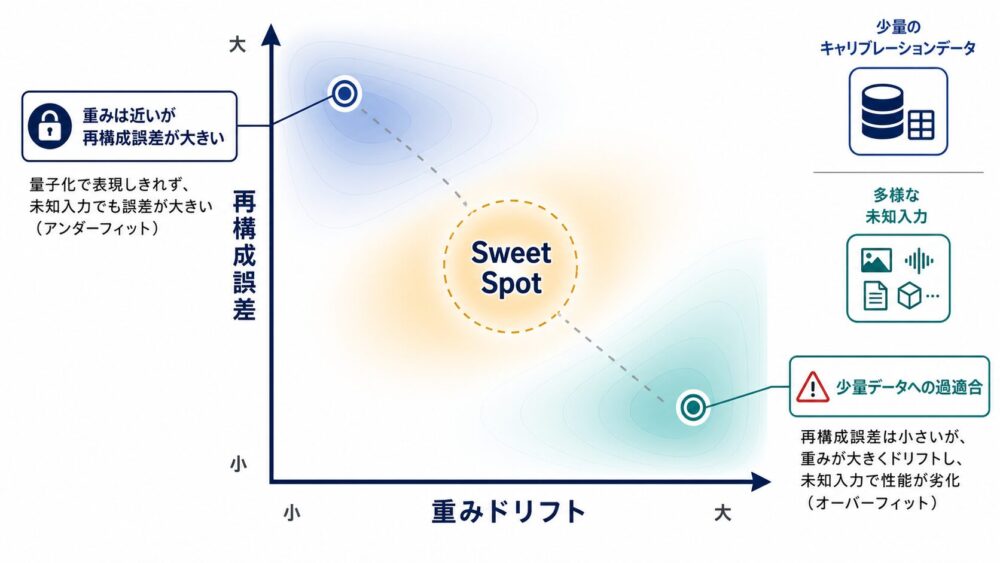
キャリブレーションデータ上の出力が一致していても、量子化後の重み自体が元の重みと近いとは限りません。
これは、限られた入力 \(\mathbf{X}_l\) に対して、似た出力を作る量子化候補が複数存在するためです。
標準的な目的関数は、その中からキャリブレーション誤差が最小の候補を選びます。
しかし、その候補が元の重みから大きく離れていると、キャリブレーションデータと異なる入力で誤差が拡大する可能性があります。
論文は、このずれをweight drift(重みドリフト)と呼んでいます。
\[
\Delta \mathbf{W}_l
=
\widehat{\mathbf{W}}_l-\mathbf{W}_l
\]
論文の一般化リスク解析では、重みドリフトを半径 \(R\) 以下に制限した量子化候補について、真の下流リスクとキャリブレーション上の経験リスクとの差を次の形で評価しています。
\[
\left|
\mathcal{R}(\widehat{\mathbf{W}}_l)
–
\widehat{\mathcal{R}}_{\mathrm{cal}}(\widehat{\mathbf{W}}_l)
\right|
\le
R^2 M_X^2
\sqrt{
\frac{
\log \frac{2|\mathcal{Q}_R|}{\delta}
}{2n}
}
\]
\(n\) はキャリブレーション標本数、\(M_X\) は入力ノルムの上限、\(\mathcal{Q}_R\) は元の重みから半径 \(R\) 以内の量子化候補集合です。
この上界は、重みドリフト \(R\) が大きいほど、また標本数 \(n\) が少ないほど緩くなります。
ただし、この定理が直接保証するのは層単位の再構成リスクです。
LLM全体の下流タスク精度を直接保証する定理ではない点には注意が必要です。
論文の主張は、「キャリブレーション誤差だけを下げる」より、「誤差と重みドリフトのsweet spot(両者の釣り合う領域)を探す」方が一般化に有利だというものです。
論文解説:RQCとSARQCの仕組み
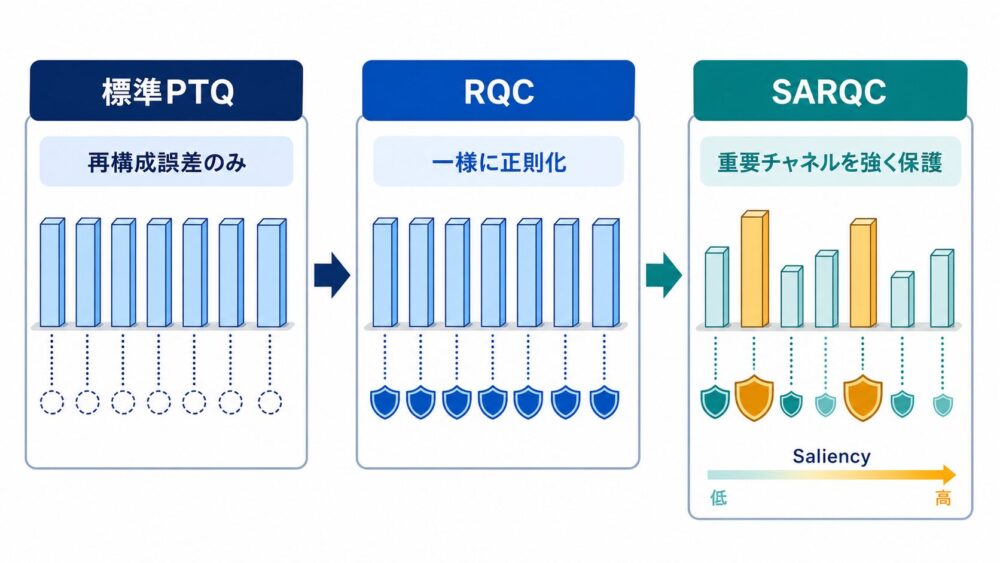
RQC:元の重みから離れすぎないようにする
RQC(Regularized Quantization Calibration)は、標準的な再構成誤差へ重みドリフトのペナルティを追加します。
\[
\min_{\widehat{\mathbf{W}}_l \in \mathcal{Q}}
\left\|
\mathbf{W}_l\mathbf{X}_l
–
\widehat{\mathbf{W}}_l\mathbf{X}_l
\right\|_{\mathrm{F}}^2
+
\lambda
\left\|
\widehat{\mathbf{W}}_l-\mathbf{W}_l
\right\|_{\mathrm{F}}^2
\]
\(\lambda\) は、再構成誤差と元の重みへの近さを調整する正則化係数です。
\(\lambda=0\) なら従来の再構成誤差だけに戻ります。
\(\lambda\) を大きくすると元の重みに近い候補を優先しますが、大きすぎるとキャリブレーション入力に対する出力再構成を犠牲にします。
| \(\lambda\) の状態 | 再構成誤差 | 重みドリフト | 想定される問題 |
|---|---|---|---|
| 0または小さすぎる | 小さくしやすい | 大きくなり得る | キャリブレーションデータへ過適合しやすい |
| 中程度 | 両者を均衡 | 抑制 | 下流性能のsweet spotになり得る |
| 大きすぎる | 大きくなり得る | 強く抑制 | 有効な量子化候補まで避ける可能性 |
RQCは、すべてのチャネルのずれを一様に扱います。
ここから一歩進め、「重要なチャネルのずれほど強く罰する」のがSARQCです。
SARQC:重要なチャネルほど強く守る
SARQCでは、対角行列 \(\mathbf{S}_l\) を使ってチャネルごとのsaliencyを表します。
\[
\min_{\widehat{\mathbf{W}}_l \in \mathcal{Q}}
\underbrace{
\left\|
\mathbf{W}_l\mathbf{X}_l
–
\widehat{\mathbf{W}}_l\mathbf{X}_l
\right\|_{\mathrm{F}}^2
}_{\mathcal{L}_{\mathrm{recon}}}
+
\lambda
\underbrace{
\left\|
(\widehat{\mathbf{W}}_l-\mathbf{W}_l)\mathbf{S}_l
\right\|_{\mathrm{F}}^2
}_{\mathcal{L}_{\mathrm{sar}}}
\]
saliencyが大きいチャネルでは、同じ重みドリフトでもペナルティが大きくなります。
これにより、出力へ強く影響するチャネルを優先して元の重みに近く保ちます。
\(\mathbf{S}_l=\mathbf{I}\)、つまり単位行列にすると、一様な正則化であるRQCへ戻ります。
ここで重要なのは、SARQCが重要な重みだけを高精度形式で保存する混合精度法ではないことです。
同じ低bitの量子化候補から、重要チャネルの情報を失いにくい候補をキャリブレーション時に選びます。
SARQCを既存のAWQ型・GPTQ型手法へ組み込む
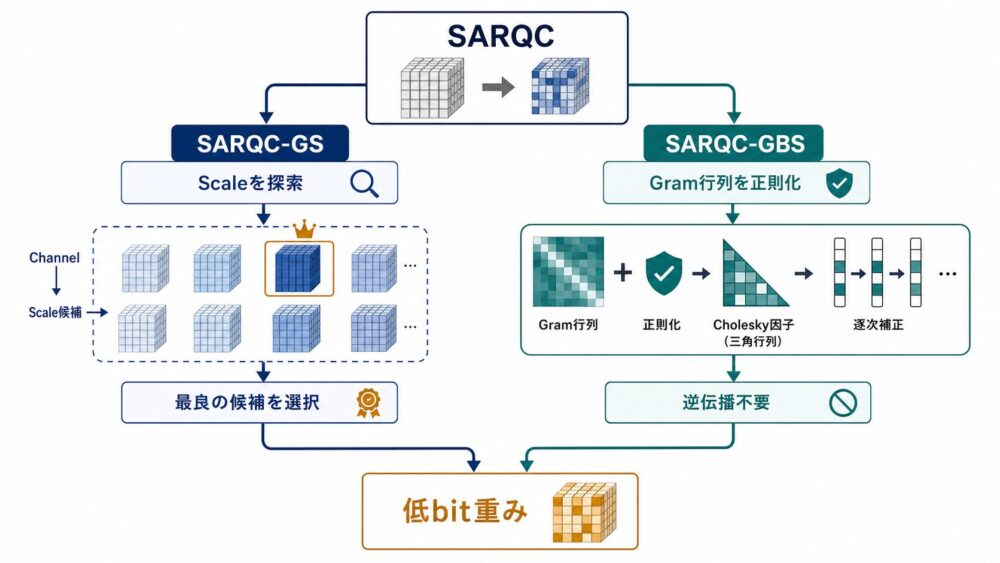
論文は、SARQCの目的関数を2つの代表的なPTQパラダイムへ組み込んでいます。
SARQC-GS:scale候補をグリッド探索する
AWQに近いscale探索では、チャネルごとのscaleを決める \(\alpha\) の候補を作り、各候補の量子化重みを評価します。
\[
\min_{\alpha \in \{\alpha_k\}}
\mathcal{L}_{\mathrm{recon}}(\alpha)
+
\lambda \mathcal{L}_{\mathrm{sar}}(\alpha)
\]
論文の実装では、\(\alpha\) を0から1まで0.05刻みの21候補で探索します。
saliencyは、チャネル \(j\) の活性化値と重みの平均絶対値から次のように作ります。
\[
s_l^{(j)}
=
\frac{
\mathrm{mean}(|\mathbf{X}_l^{(j)}|)
}{
\mathrm{mean}(|\mathbf{W}_l^{(j)}|)
}
\]
再構成損失と正則化損失は値のスケールが異なるため、候補間でmin-max正規化してから合算します。
量子化演算やscaleをend-to-endで逆伝播する必要がない点が実装上の利点です。
SARQC-GBS:Gram行列へ正則化を加える
GPTQに近いGram-based solver(入力相関の二次情報を使う量子化法)では、目的関数を次の二次形式へ変形します。
\[
\min_{\widehat{\mathbf{W}}_l\in\mathcal{Q}}
\mathrm{Tr}
\left(
\Delta\mathbf{W}_l
\mathbf{G}_l
\Delta\mathbf{W}_l^{\mathrm{T}}
\right)
\]
SARQC-GBSで使う正則化済みの曲率行列は次のとおりです。
\[
\mathbf{G}_l
=
\mathbf{X}_l\mathbf{X}_l^{\mathrm{T}}
+
\lambda
\mathbf{S}_l\mathbf{S}_l^{\mathrm{T}}
\]
GPTQが使う \(\mathbf{X}_l\mathbf{X}_l^{\mathrm{T}}\) を \(\mathbf{G}_l\) に置き換え、逆行列やCholesky分解(正定値行列を三角行列へ分解する方法)を既存の逐次補正へ渡します。
| 観点 | SARQC-GS | SARQC-GBS |
|---|---|---|
| 対応する既存系統 | AWQなどのscale探索 | GPTQなどの二次情報ベース |
| 主な変更 | 候補選択の損失へ正則化を追加 | Gram行列へsaliency正則化を追加 |
| 探索対象 | scaleパラメータ \(\alpha\) と \(\lambda\) | \(\lambda\) とsaliency係数 \(\gamma\) |
| 逆伝播 | 不要 | 不要 |
| 推論時の追加処理 | なし | なし |
| キャリブレーションコスト | 候補評価と検証が増える | 複数の曲率候補評価が増える |
どちらも推論グラフへ新しい演算を足すのではなく、オフラインで量子化重みを決める段階だけを変更します。
そのため論文では、推論時の追加オーバーヘッドはないとしています。
実験結果:低bitと少量データでの頑健性

論文は、dense LLMとMoE(Mixture-of-Experts、入力ごとに一部の専門ネットワークを選ぶモデル)の両方で評価しています。
| 項目 | 実験条件 |
|---|---|
| denseモデル | LLaMA2-7B/13B、付録でLLaMA-7B/13B/30B |
| MoEモデル | DeepSeek-MoE-16B-Base、Qwen3-MoE-30B、Mixtral-8x7B |
| bit幅 | W4A16、W3A16、W2A16 |
| group size | denseは128、MoEは64 |
| キャリブレーション | WikiText2学習splitの128サンプル |
| 評価 | WikiText2 perplexity、8種類のzero-shotタスク |
| ハードウェア | NVIDIA A100 80GB |
W2A16で報告された代表的なperplexityは次のとおりです。
perplexityは低いほど良い指標です。
| モデル | FP16/BF16 | GPTQ | GPTAQ | SARQC-GBS(Saliency) |
|---|---|---|---|---|
| LLaMA2-13B | 4.88 | 792.32 | 176.53 | 117.67 |
| Qwen3-MoE-30B | 6.09 | 38.03 | 未評価 | 16.69 |
| Mixtral-8x7B | 3.84 | 1079.31 | 未評価 | 31.48 |
2bit量子化は依然として元モデルとの差が大きく、SARQCを使えばFP16/BF16と同等になるわけではありません。
それでも、再構成誤差だけに基づくGPTQが不安定になる条件で、悪化を大幅に抑えている点が重要です。
W4A16の平均zero-shot精度でも、LLaMA2-7BではAWQの56.37%、GPTQの55.82%に対し、SARQC-GS(Saliency)は57.39%でした。
Qwen3-MoE-30Bでは、BF16の69.79%、GPTQの67.95%に対し、SARQC-GBS(Saliency)は70.79%と報告されています。
ただし、個別タスクでは常にSARQCが最高とは限りません。
平均値の改善と、すべての条件での一律な優位性は区別する必要があります。
キャリブレーションデータが少ない場合
論文のablation(構成要素を変えて影響を見る実験)では、キャリブレーションサンプル数を変えてもSARQC-GBSは比較的安定し、特に少量データでGPTQとの差が広がりました。
これは、経験再構成誤差だけに合わせすぎず、元の重みを参照点として残す設計と整合します。
推論速度
論文はsequence length 2048、A100 80GBで、FP16/BF16に対する速度比を測定しています。
| モデル | 手法 | Prefill | Decoding |
|---|---|---|---|
| LLaMA2-7B | AWQ | 2.11倍 | 1.92倍 |
| LLaMA2-7B | SARQC-GS(Saliency) | 2.12倍 | 1.95倍 |
| LLaMA2-7B | GPTQ | 1.98倍 | 1.81倍 |
| LLaMA2-7B | SARQC-GBS(Saliency) | 2.00倍 | 1.84倍 |
比較対象と同等の速度であることは、SARQCの正則化がキャリブレーション時だけに働くという設計を裏付けます。
一方、実際の速度はGPU、量子化kernel、batch size、sequence length、serving engineに依存します。
この表を異なる環境へそのまま一般化することはできません。
実サービス・エッジAI・高画質タスクへの応用
SARQCが直接対象とするのは、LLMのweight-only PTQです。
実用上は、GPUサーバーのLLM推論、オンプレミス環境、メモリ制約のあるエッジ端末へ応用できる可能性があります。
| 応用先 | 期待できる点 | 導入時の課題 |
|---|---|---|
| LLM推論サーバー | INT4重みでVRAMとメモリ帯域を削減 | 対応kernelとserving engineの確認が必要 |
| オンプレミスLLM | 限られたGPUへ大きなモデルを配置しやすい | 業務データに合うキャリブレーション集合が必要 |
| エッジAI | モデル保存量と転送量を削減 | NPU/GPUが対象bit幅と演算形式を支える必要 |
| VLM | 言語部分の量子化精度を保ちやすくする可能性 | vision encoderを含むモデル全体は未検証 |
| 画像生成・高画質化 | text encoderやLLMベース制御部の圧縮候補 | diffusion本体や画質指標への効果は論文の対象外 |
カメラ向けのDenoise、Demosaic、super resolutionへ応用する場合、SARQCをそのまま使えるとは限りません。
これらは画素単位の誤差や知覚品質に敏感で、weight-activation quantizationが必要になる場合もあります。
また、前処理として各層の活性化統計を収集し、複数の \(\lambda\) やscale候補を評価するため、量子化作成時の処理フローは増えます。
したがって、推論時の追加オーバーヘッドがなくても、モデル変換時間まで無料になるわけではありません。
実運用では、実際の入力分布を代表する検証データを用意し、perplexityだけでなく、指示追従、構造化出力、コード生成、安全性などのタスク別品質を確認する必要があります。
よくある誤解
| よくある誤解 | 正確な情報・解釈 |
|---|---|
| SARQCは新しい量子化データ形式である | 量子化形式ではなく、量子化重みを選ぶキャリブレーション目的の改善である |
| 再構成誤差が最小なら下流性能も必ず最高になる | 少量データでは重みドリフトが大きい候補を選び、未知入力で悪化する可能性がある |
| saliencyの高い重みだけFP16で残す | 同じ低bit候補の中で、重要チャネルのずれを強く罰する |
| SARQCはGPTQ専用である | grid-search系とGram-based系の両方へ統合され、OmniQuantへの拡張実験もある |
| 2bitでも元モデルと同等精度になる | 2bitで悪化を抑えるが、FP16/BF16との差は大きく残る |
| 推論コストが完全にゼロである | 追加の推論演算はないが、低bit kernel自体の対応とオフラインの探索コストは必要 |
| 一般化リスクの定理がLLM全体のタスク精度を保証する | 定理は層単位の再構成リスクを扱い、下流タスク精度は実験で検証されている |
論文の限界と今後の課題
論文自身も、次の限界を挙げています。
| 限界 | 今後必要な検証 |
|---|---|
| 計算資源の制約から超大規模LLMを未評価 | さらに大きいdense/MoEモデルでの再現性 |
| saliency設計は既存研究に着想を得たもの | タスクや層に応じたsaliency推定の最適化 |
| 理論と手法が層単位 | 層をまたぐ量子化誤差伝播の考慮 |
| 主対象がweight-only PTQ | weight-activation quantizationへの拡張 |
| \(\lambda\) などの探索が必要 | 少ない評価回数で安定して決める方法 |
加えて、論文の評価モデルはLLaMA系と代表的なMoEに集中しています。
日本語LLM、instruction-tunedモデル、長文脈モデル、VLMで同じ傾向になるかは確認が必要です。
まとめ
SARQCは、LLM量子化のキャリブレーションを「少量データ上の出力再構成」だけで完結させず、「元の重みからどれだけ離れたか」も同時に管理する手法です。
RQCは一様な重みドリフトを抑え、SARQCはsaliencyを使って重要チャネルをより強く保護します。
既存のAWQ型グリッド探索とGPTQ型Gram-based solverへ組み込め、推論時には追加処理を持ち込みません。
論文の結果では、特に2〜3bitや少量キャリブレーションの難しい条件で、perplexityとzero-shot精度の悪化を抑えました。
一方、2bitでも元モデルとの差は残り、層単位の理論がLLM全体を保証するわけではありません。
実サービスへ導入する場合は、対象ハードウェアのkernel対応、量子化作成時間、実データに近い検証集合、タスク別の品質評価を合わせて確認する必要があります。
関連技術
| 技術 | SARQCとの関係 | 違い |
|---|---|---|
| AWQ | SARQC-GSのベースラインとなるscale探索系PTQ | AWQの候補選択へ重みドリフト正則化を追加できる |
| GPTQ | SARQC-GBSのベースラインとなる二次情報ベースPTQ | Gram行列へsaliency正則化を加える |
| SmoothQuant | activationとweightの量子化難度をscaleで移す | SARQCはweight-onlyキャリブレーションの一般化を重視 |
| OmniQuant | learnableなweight clippingとscaleを使うPTQ | 論文ではSARQCを追加する拡張実験を実施 |
| QAT | 学習中に量子化誤差を考慮する | SARQCは再学習を避けるPTQ |
参考:
- AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
- GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
- SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models
- OmniQuant: Omnidirectionally Calibrated Quantization for Large Language Models
次に読むべき記事
- LLMの量子化とは?PTQとQAT、weight-onlyとweight-activationの違い
- AWQとは?重要チャネルを守るINT4量子化の仕組み
- GPTQとは?Hessian近似と誤差補正を数式で理解する
- SmoothQuantとは?Activation Outlierをweightへ移す仕組み
- MoEの量子化はなぜ難しいのか?Expertごとの分布差を整理

コメント