Tokenizationとは?SentencePiece論文からLLMのトークン化を解説
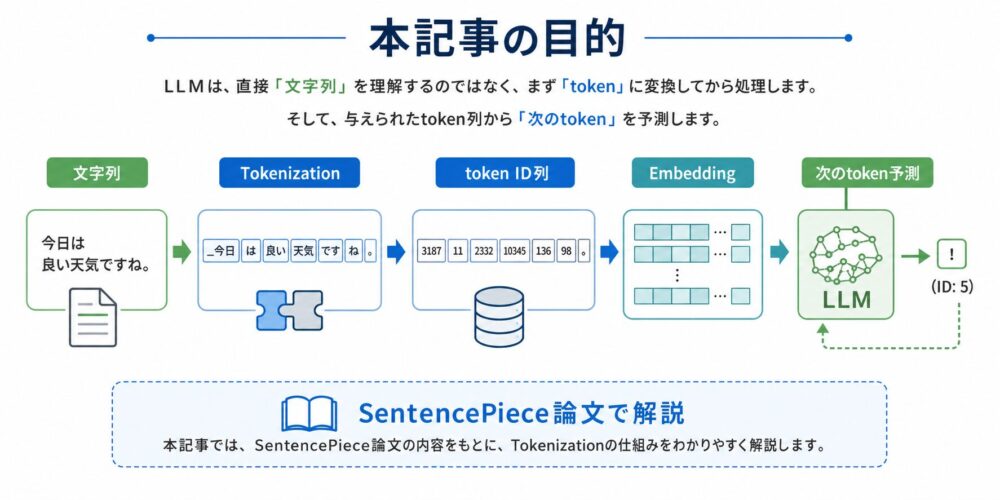
LLM(大規模言語モデル)は、次のtokenを予測することで文章を生成します。
そのためには、人間が読む文字列を、LLMが扱えるtoken ID列へ変換する必要があります。
この記事では、この変換処理で重要になるTokenization(文章をモデルが扱える単位へ分割する処理)を、SentencePiece論文に基づいて解説します。
3行要約
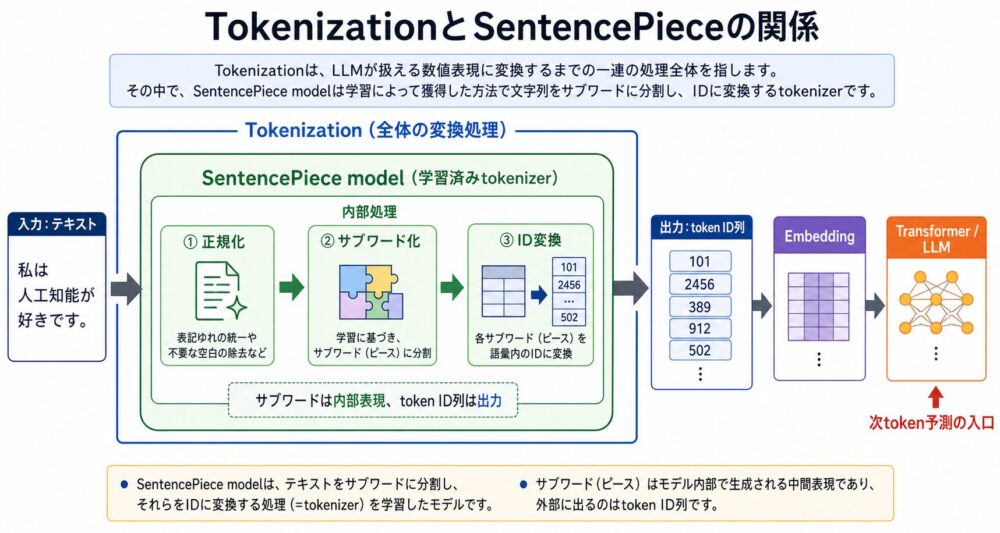
- Tokenizationは、文章をtokenへ分割し、LLMが扱えるtoken ID列へ変換する入口の処理です。
- SentencePiece論文は、事前の単語分割に依存せず、raw text(言語別の単語分割をかける前の文字列)からサブワードtokenizerを学習する方法を提案しました。
- 特に、日本語や中国語のように空白で単語境界が示されない言語では、言語依存の前処理を減らせる点が重要です。
Tokenizationとは何か
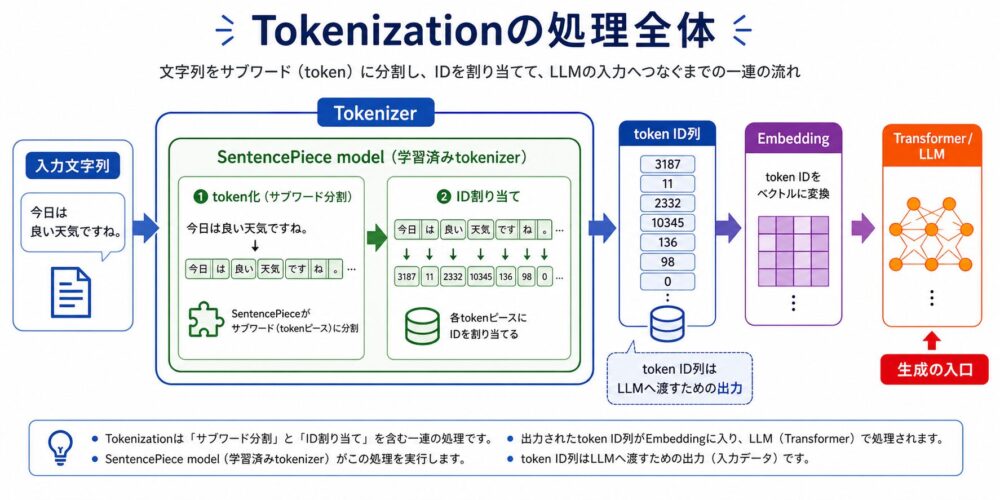
Tokenizationは、文章をモデルが扱えるtokenへ分割し、必要に応じてtoken IDへ変換する処理です。
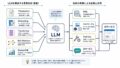
LLMは、入力文をそのまま文字列として計算しているわけではありません。
まず文章をtoken列へ分け、それぞれのtokenを語彙表上の整数IDへ変換します。
その後、Embedding(token IDをベクトルへ変換する層)で連続値のベクトルに変換され、Transformer(Attentionを中心に系列を処理するニューラルネットワーク)へ渡されます。
この処理の流れは上の画像で示しているため、ここでは文章として要点だけ押さえます。SentencePiece modelを使う場合、文字列はmodel内部でサブワードpieceへ分割され、語彙表に基づいてIDへ変換されます。最終的な出力がtoken ID列であり、それがLLMへ入る最初の形式になります。
この流れの中で、TokenizationはLLMが「世界をどの粒度の記号列として見るか」を決めます。
単語に近い単位で見るのか、単語の一部で見るのか、記号や空白をどう扱うのかによって、入力長、コスト、未知語への強さ、生成結果の安定性が変わります。
| 観点 | TokenizationがLLMにもたらす効果 |
|---|---|
| 入力長 | 同じ文章でもtoken数が変わり、文脈長の消費量が変わる |
| 計算コスト | token数が増えると推論レイテンシやメモリ使用量に影響する |
| 未知語対応 | サブワードに分けることで未知語や固有名詞を扱いやすくする |
| 多言語対応 | 日本語、中国語、英語などを同じ枠組みで扱いやすくする |
| 再現性 | tokenizer、語彙、正規化ルールを固定することで入出力を安定させる |
補足:Tokenizationまわりの用語を階層で整理する
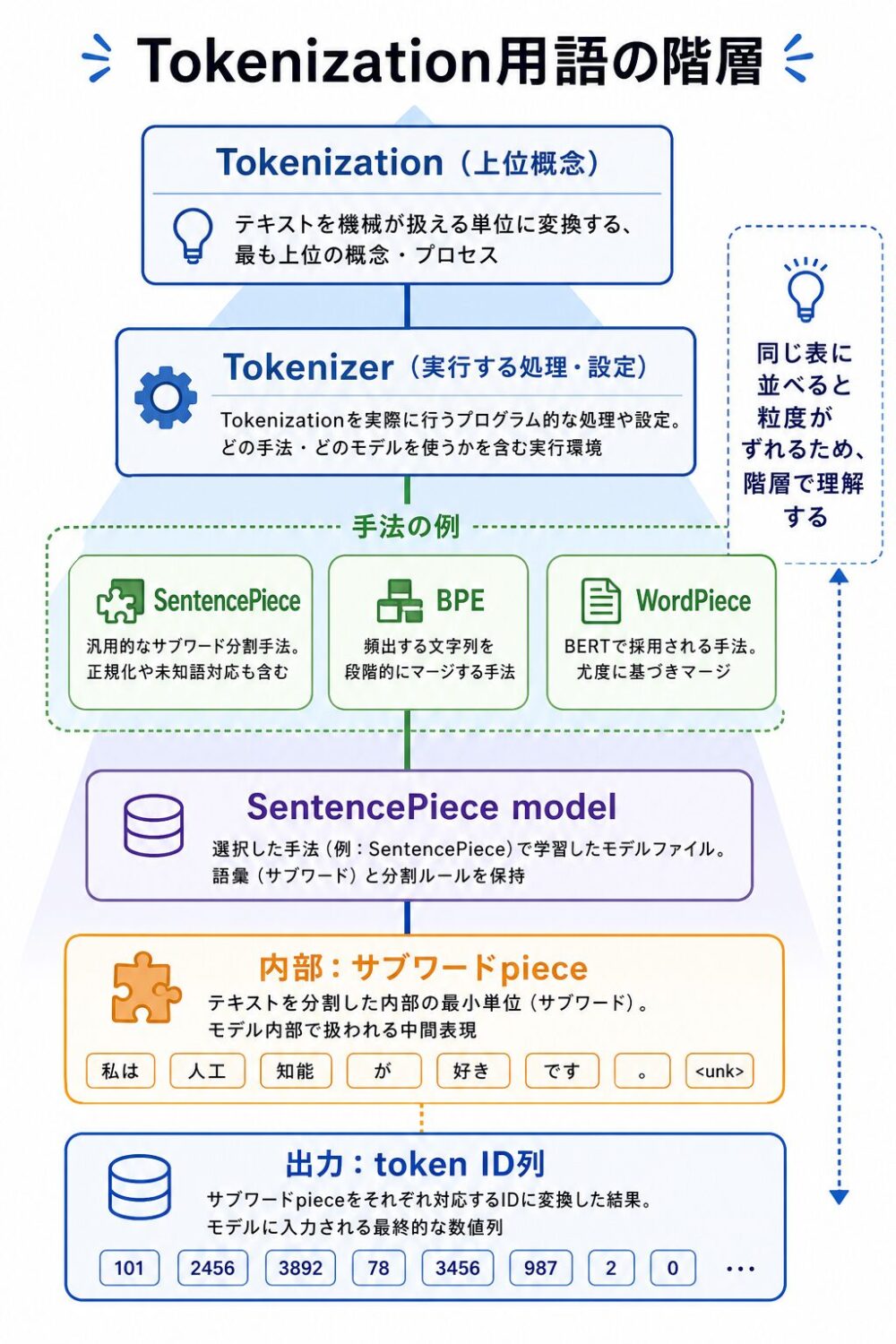
ここで混乱しやすいのが、「Tokenization」「Tokenizer」「SentencePiece」「SentencePiece model」の粒度です。
これらは同じ階層の言葉ではありません。Tokenizationが上位概念で、その処理を実行するものがTokenizerです。SentencePieceはTokenizerを作るための具体的な手法・実装の一つで、SentencePiece modelはその手法で学習された語彙、ID、正規化ルール、モデルタイプを含むファイルです。
| 階層 | 用語 | 役割 |
|---|---|---|
| 上位概念 | Tokenization | 文字列をtokenへ分割し、token ID列へ変換する処理全体 |
| 実行する仕組み | Tokenizer | Tokenizationを実行する処理・設定・プログラムの総称 |
| 手法・実装の例 | SentencePiece | raw textからサブワードtokenizerを学習・実行する手法と実装 |
| 学習済みモデル | SentencePiece model | 語彙、ID、正規化ルール、BPE/Unigram設定を含む学習済みtokenizerファイル |
| 内部表現 | サブワードpiece | SentencePiece model内部で文字列から作られる中間的なtoken単位 |
| 出力 | token ID列 | サブワードpieceに語彙表上のIDを割り当てた、LLMへ渡す整数列 |
たとえば、語彙表に ▁New -> 482, ▁York -> 901 と登録されているとします。
この場合、New York はSentencePiece model内部で ["▁New", "▁York"] というサブワードpiece列になり、そこにIDが割り当てられて [482, 901] というtoken ID列として出力されます。
つまり、サブワードはSentencePiece modelの内部処理で扱われる中間表現で、token ID列はmodelからLLM側へ渡される出力です。
SentencePiece論文から読み解く
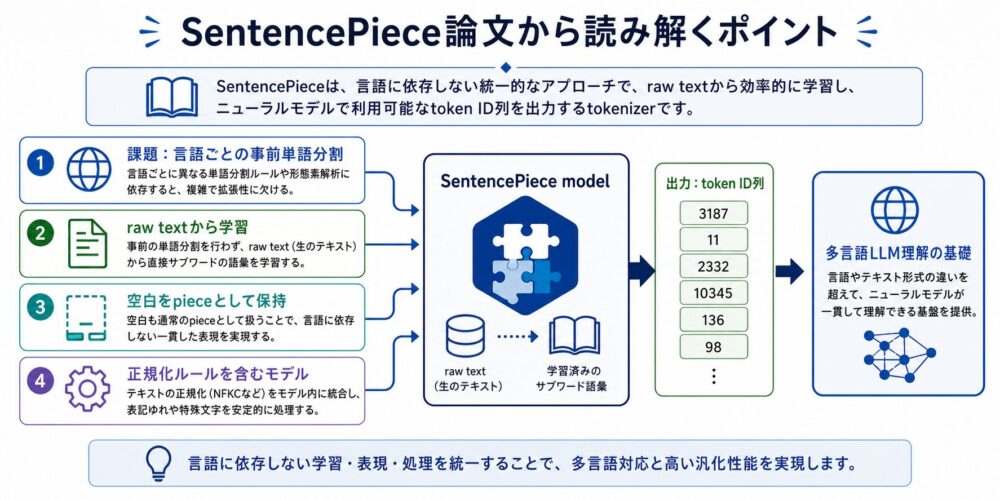
ここからは、SentencePiece論文を使って、Tokenizationの設計を読み解きます。
SentencePieceは、現代のLLMで使われるtokenizerを理解するうえで重要な論文です。
理由は、単に「サブワード分割をした」からではありません。
raw textから直接tokenizerを学習し、空白や正規化まで含めて、言語非依存に扱う設計を示した点が重要です。
論文情報
| 項目 | 内容 |
|---|---|
| 論文タイトル | SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing |
| 著者 | Taku Kudo, John Richardson |
| 公開日 | 2018年8月19日 |
| 採択 | EMNLP 2018 Demo Paper |
| 分野 | Computation and Language |
| arXiv | SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing |
| DOI | 10.48550/arXiv.1808.06226 |
| 実装 | google/sentencepiece |
論文概要
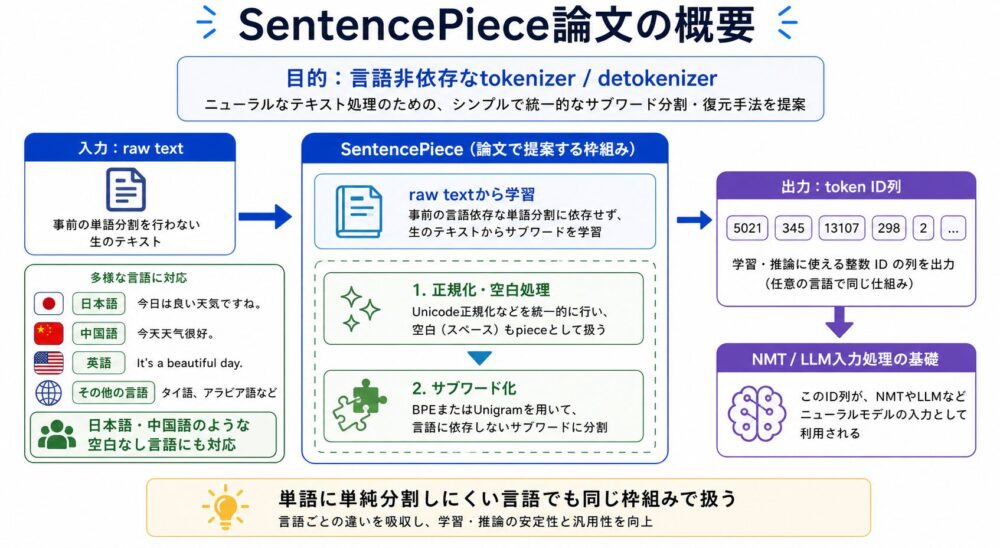
SentencePiece論文は、NMT(ニューラルネットワークを用いた機械翻訳)向けに、言語非依存なサブワードtokenizerとdetokenizer(token列を文字列へ戻す処理)を提案した論文です。
この論文をTokenization解説で扱う理由は、LLMの入力処理にも通じる基礎的な問題を扱っているからです。
単語に単純に区切るだけなら、英語ではある程度うまくいきます。
英語は空白で単語境界が見えるため、I like machine learning. を I / like / machine / learning / . のように分ける発想が自然です。
しかし、日本語や中国語のようなnon-segmented languages(空白で単語境界が明示されない言語)では、先にどこで単語を切るか自体が難しい問題になります。
私は機械学習が好きです
この文を、
[私] [は] [機械学習] [が] [好き] [です]
と切るのか、
[私は] [機械] [学習] [が] [好きです]
と切るのかは、言語知識や辞書、学習データに依存します。
SentencePieceは、この問題に対して、言語ごとの単語分割器を前提にせず、raw textから直接サブワードモデルを学習する設計を採ります。
従来技術の課題
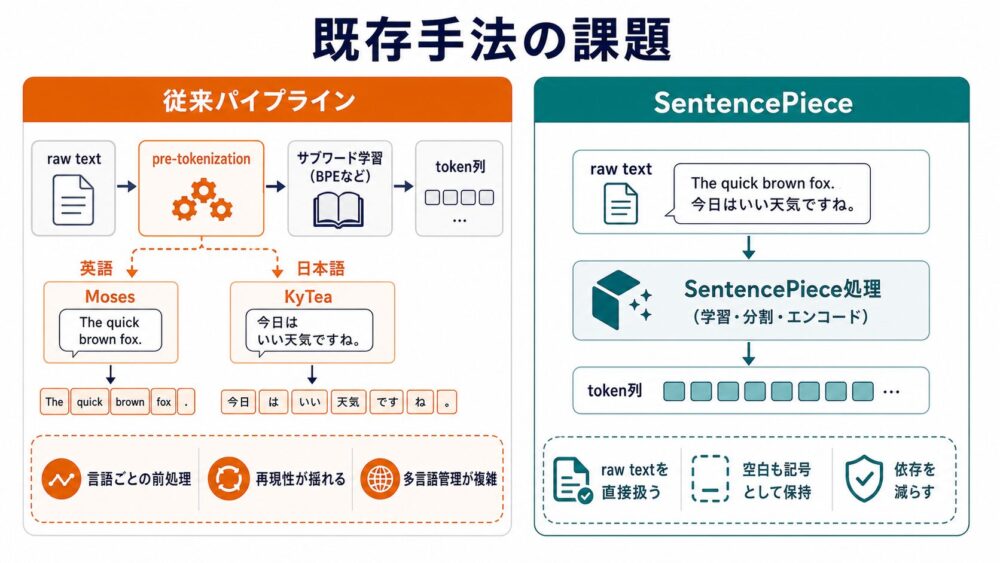
SentencePiece以前にも、BPE(Byte Pair Encoding、頻出する隣接記号を順に結合する圧縮由来の分割手法)や、subword-nmtのようなサブワード分割ツールは使われていました。
ただし、多くのツールは入力がすでに単語列へ分かれていることを前提にしていました。
| 課題 | 内容 | LLMでの影響 |
|---|---|---|
| 言語依存 | 英語はMoses、日本語はKyTeaのように言語ごとの前処理が必要になる | 多言語モデルで前処理パイプラインが複雑になる |
| 再現性 | 前処理ツールのバージョンや設定差で結果が変わりうる | 学習時と推論時でtoken ID列がずれるリスクがある |
| 多言語化の難しさ | 言語ごとに前処理を管理する必要がある | 対応言語を増やすたびに運用負荷が増える |
| 可逆性の問題 | token列から元の空白や記号配置を戻せない場合がある | 生成結果の表示や後処理が不安定になる |
この課題は、LLMでも無視できません。
LLMでは、学習データ、Fine-tuning(追加学習)、RAG(検索で外部文書を補う生成方式)、評価データで同じtokenizerを使う必要があります。
前処理が言語や環境に依存すると、同じ文字列でもtoken ID列が変わり、モデルの入力が別物になってしまいます。
Raw textから学習する言語非依存サブワード化
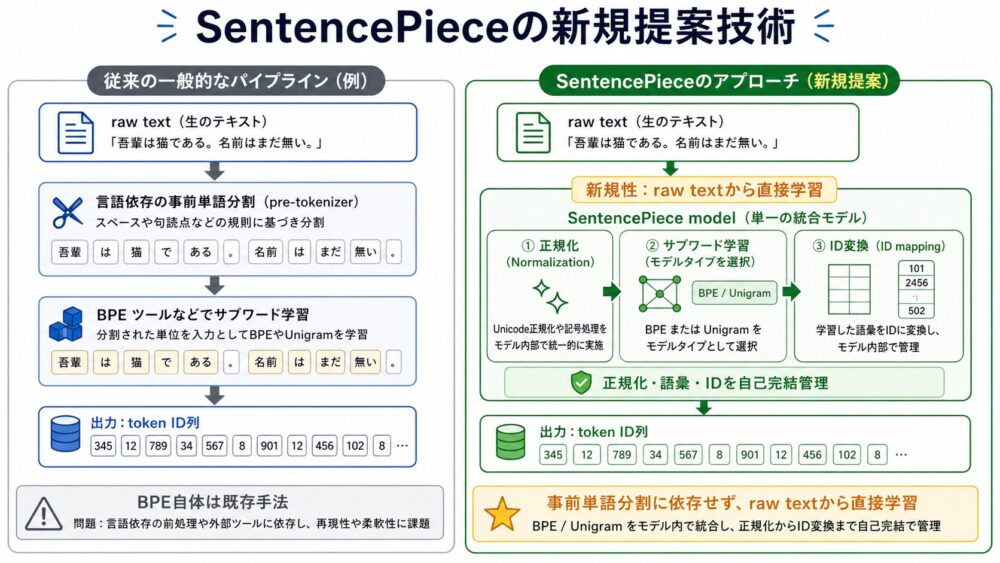
SentencePiece論文の新規技術は、BPEそのものを新しく発明したことではありません。BPEはSentencePiece以前から使われていたサブワード分割手法です。
重要なのは、raw textを直接入力として、言語依存のpre-tokenizationに頼らず、BPEやUnigram Language Model(候補サブワード集合から文を生成する確率モデル)を選択できるtokenizer modelとして学習・実行できるようにした点です。
従来のように、外部の単語分割器で文を単語列へ変換してからサブワード化するのではありません。SentencePiece modelの内部で、正規化、空白の保持、サブワード化、ID変換までを一貫して扱います。
| 新規性 | なぜ重要か |
|---|---|
| raw textから直接サブワードモデルを学習 | non-segmented languagesでも同じ枠組みで扱える |
| lossless tokenization | detokenizationの曖昧さを減らし、生成結果を扱いやすくする |
| 正規化ルール込みの自己完結モデル | 実験・本番環境での再現性を高める |
| C++/Python/TensorFlow API | オフライン前処理だけでなくオンザフライ処理に組み込みやすい |
| BPEとUnigramの両対応 | 用途に応じて分割アルゴリズムを選べる |
BPEの基本も押さえておくと、SentencePieceが何を内部で選択できるようにしたのかが分かりやすくなります。BPEは、最初に文字単位で文を表します。
そのうえで、corpus(学習用テキスト集合)内で頻出する隣接ペアを順に結合して語彙を作ります。
corpus: low, lower, lowest
初期状態:
l o w
l o w e r
l o w e s t
頻出ペア l + o を結合:
lo w
lo w e r
lo w e s t
次に lo + w を結合:
low
low e r
low e s t
この結果、low のような頻出文字列が1tokenになりやすくなります。
未知語が来ても、文字や短いサブワードへ分解できるため、単語単位より扱いやすくなります。
空白をpieceとして扱うlossless tokenization
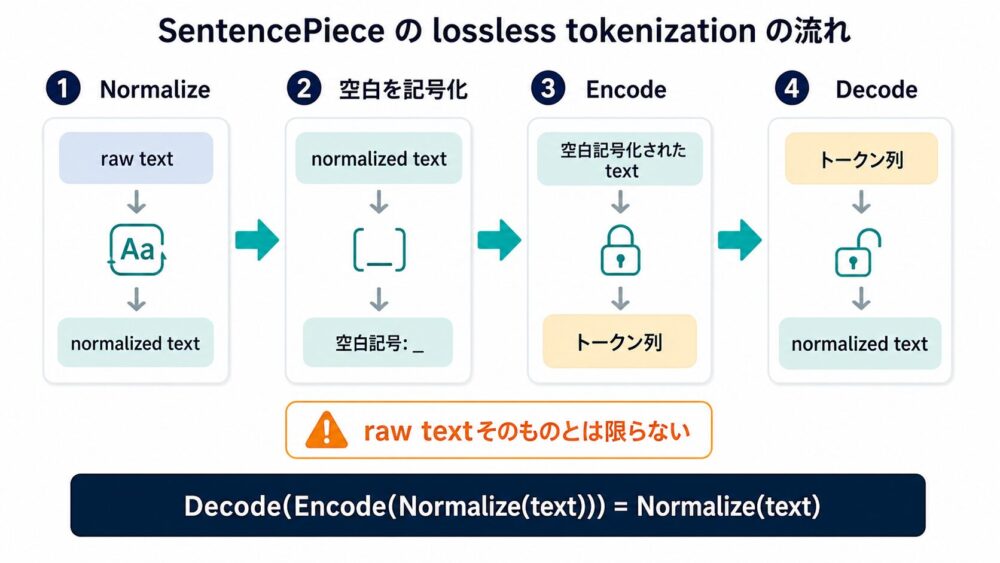
SentencePiece論文で特に重要なのが、空白を通常の記号として扱う設計です。
英語では、空白は単語境界を示すために便利です。
しかし、tokenizer内部で空白を単なる区切りとして消してしまうと、Decode(token列から文字列へ戻す処理)したときに、元の空白配置を戻しにくくなります。
SentencePieceでは、空白を ▁ のような記号として表現します。
これにより、空白を含む形でpiece列を扱えます。
論文で狙う関係は次です。
\[
Decode(Encode(Normalize(text))) = Normalize(text)
\]
ここで復元されるのは、raw textそのものではなくNormalize後の文字列です。
たとえば、全角英数字を半角へ正規化する設定があるとします。
text:
Hello world.
Normalize(text):
Hello world.
Encode(Normalize(text)):
[▁Hello] [▁world] [.]
Decode(...):
Hello world.
この場合、Decode(...) は Hello world. へ戻ります。
元の Hello world. には戻りません。
つまり、lossless tokenizationは「どんなraw textでも完全に元へ戻る」という意味ではありません。
正規化後の文字列を、token列から一貫して復元できるという意味です。
BPEとUnigram Language Modelを選べる設計
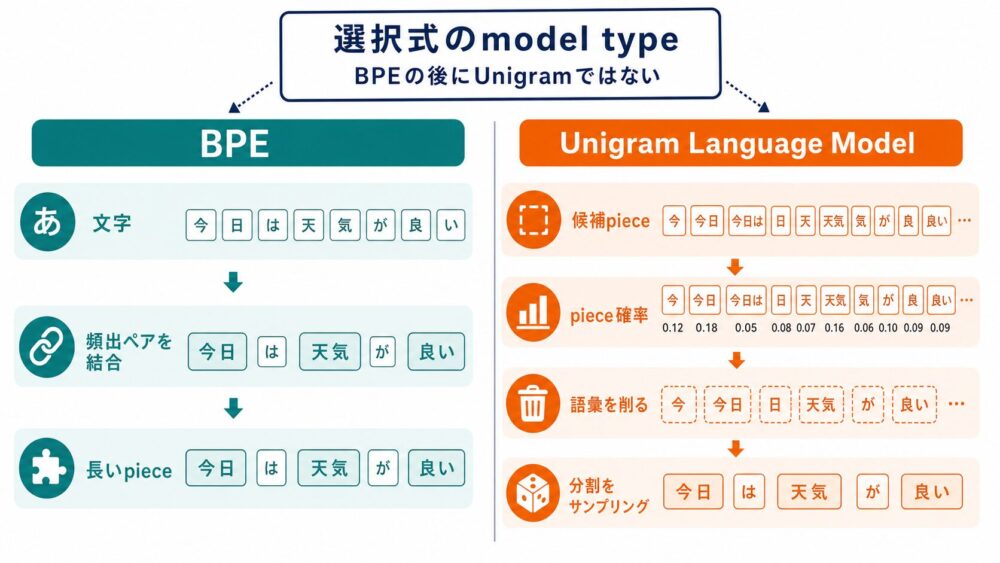
SentencePieceは、BPEとUnigram Language Modelの両方を実装しています。
ただし、BPEを行ってからUnigramへ入力するわけではありません。
tokenizerモデルを学習するときに、どちらのモデルタイプを使うかを選びます。
| 観点 | BPE | Unigram Language Model |
|---|---|---|
| 基本発想 | 頻出する隣接ペアを順に結合する | 候補サブワードの確率モデルとして扱う |
| 学習の見方 | ボトムアップに語彙を作る | 大きめの候補から不要な語彙を削る |
| 分割の性質 | 決定的になりやすい | 複数分割を確率的に扱いやすい |
| subword regularization | 直接は扱いにくい | サンプリングと相性がよい |
| 直感 | 圧縮に近い | 生成モデルに近い |
Unigram Language Modelでは、文がサブワード列から生成される確率を考えます。
文 \( X \) に対して、ある分割 \( x = (x_1, x_2, …, x_M) \) の確率は、簡略化すると次のように書けます。
\[
P(x) = \prod_{i=1}^{M} p(x_i)
\]
補足:Unigramの分割候補の例
たとえば "New York" なら、次のような複数の分割候補がありえます。
候補A: [▁New] [▁York]
候補B: [▁Ne] [w] [▁York]
候補C: [▁New] [▁Yo] [rk]
推論時はもっとも確率が高い分割を選ぶことが多いです。
一方、学習時には複数候補から確率的にサンプリングし、同じ文字列でも少し異なる分割を見せることがあります。
これがsubword regularization(分割の揺らぎを使った正則化)です。
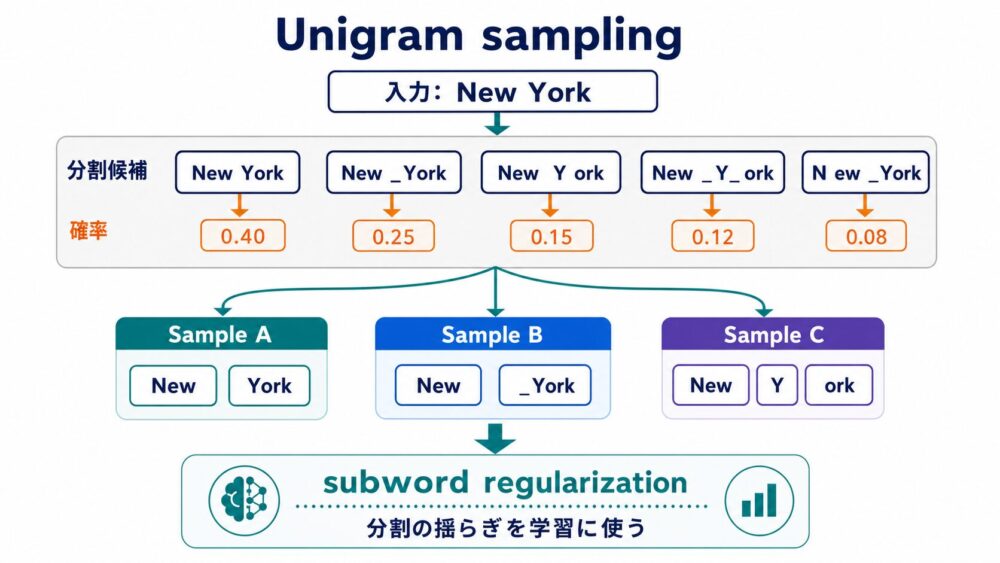
上の画像は、この説明を視覚化したものです。同じ入力文に対して複数のサブワード分割候補を作り、それぞれの確率を評価したうえで、学習時には確率的に分割を選ぶ流れを示しています。
実験結果
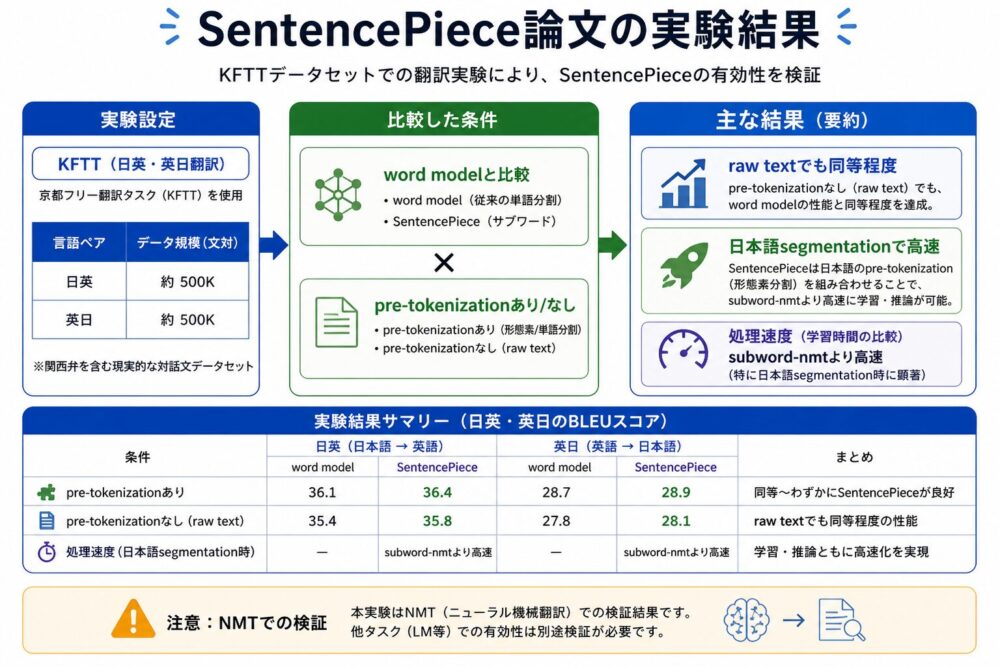
論文では、KFTT(Kyoto Free Translation Task、京都関連テキストを用いた英日・日英翻訳データセット)を使います。
このデータセットで、word modelとSentencePieceを比較しています。
主な結果は次の通りです。
| 比較 | 論文で示された傾向 |
|---|---|
| Word model vs SentencePiece | SentencePieceのサブワード分割はword modelよりBLEUが高い傾向 |
| pre-tokenizationあり vs なし | raw textから直接学習しても同等程度、条件によってはpre-tokenizationなしが有利 |
| 日本語処理 | non-segmented languagesでは、raw textからの教師なし分割が有効に働く可能性 |
| 処理速度 | raw Japanese textに対するsegmentationでsubword-nmtより大幅に高速な設定が報告されている |
注意点として、この実験はNMTでの検証です。
現在のLLM全般の性能をそのまま保証するものではありません。
ただし、言語依存の前処理を減らすという設計思想は、現在でも重要です。
tokenizerをモデルファイルとして再現可能に管理する点も、実務で効いてきます。
実装例:BPEとUnigramを比較する
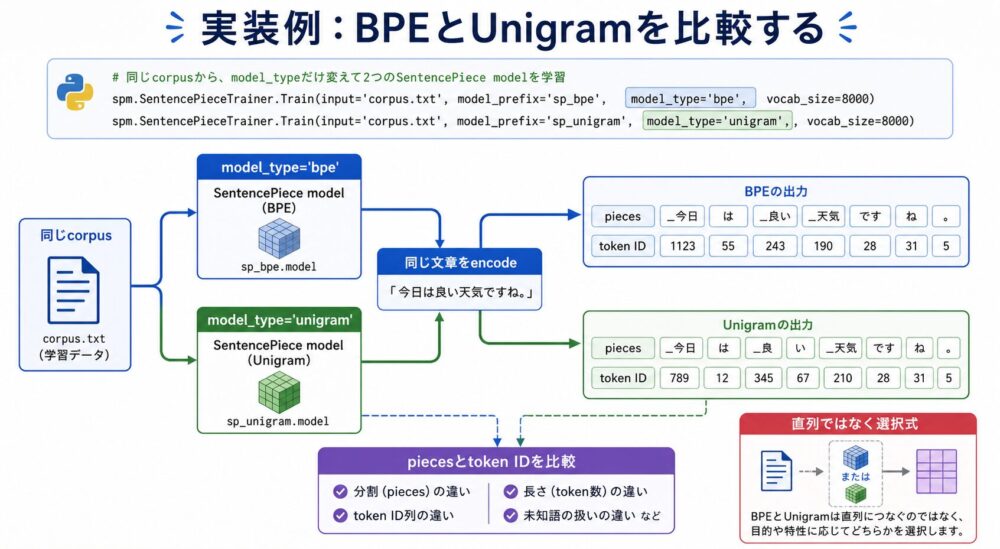
以下は、SentencePieceのAPIを使った最小例です。
同じcorpusからBPEモデルとUnigramモデルを学習し、同じ文章を分割します。
実行には sentencepiece パッケージが必要です。
import logging
import tempfile
from pathlib import Path
from typing import Literal
import sentencepiece as spm
logger = logging.getLogger(__name__)
ModelType = Literal["bpe", "unigram"]
def train_sentencepiece_model(corpus: list[str], model_type: ModelType, vocab_size: int) -> Path:
"""Train a tiny SentencePiece model for comparing BPE and Unigram.
Args:
corpus: Training sentences used as the raw text corpus.
model_type: SentencePiece model type. Use "bpe" or "unigram".
vocab_size: Target vocabulary size for the tokenizer model.
Returns:
Path to the trained `.model` file.
Raises:
ValueError: If corpus is empty or vocab_size is too small.
RuntimeError: If SentencePiece training fails.
Examples:
>>> path = train_sentencepiece_model(["I like New York"], "bpe", 32)
>>> path.suffix
".model"
"""
if not corpus:
raise ValueError("corpus must not be empty")
if vocab_size < 16:
raise ValueError("vocab_size must be at least 16 for this demo")
work_dir = Path(tempfile.mkdtemp(prefix=f"spm_{model_type}_"))
corpus_path = work_dir / "corpus.txt"
corpus_path.write_text("\n".join(corpus), encoding="utf-8")
prefix = work_dir / model_type
logger.info("train SentencePiece model: type=%s vocab_size=%d", model_type, vocab_size)
# BPEとUnigramの差を見たいので、同じcorpusと語彙サイズでmodel_typeだけを変える。
spm.SentencePieceTrainer.train(
input=str(corpus_path),
model_prefix=str(prefix),
model_type=model_type,
vocab_size=vocab_size,
character_coverage=1.0,
bos_id=-1,
eos_id=-1,
pad_id=-1,
)
return prefix.with_suffix(".model")
def encode_with_sentencepiece(model_path: Path, text: str) -> tuple[list[str], list[int]]:
"""Encode text into subword pieces and token IDs with a SentencePiece model.
Args:
model_path: Path to a trained SentencePiece `.model` file.
text: Input text to tokenize.
Returns:
A tuple of `(pieces, token_ids)`.
Raises:
FileNotFoundError: If model_path does not exist.
RuntimeError: If the model cannot be loaded.
Examples:
>>> pieces, ids = encode_with_sentencepiece(Path("bpe.model"), "I like New York")
>>> isinstance(pieces, list) and isinstance(ids, list)
True
"""
if not model_path.exists():
raise FileNotFoundError(model_path)
processor = spm.SentencePieceProcessor(model_file=str(model_path))
pieces = processor.encode(text, out_type=str)
token_ids = processor.encode(text, out_type=int)
logger.info("encoded text: chars=%d pieces=%d", len(text), len(pieces))
logger.debug("pieces=%s token_ids=%s", pieces, token_ids)
return pieces, token_ids
def sample_unigram_segmentations(model_path: Path, text: str, samples: int = 3) -> list[list[str]]:
"""Sample multiple Unigram segmentations for the same text.
Args:
model_path: Path to a Unigram SentencePiece model.
text: Input text to tokenize.
samples: Number of sampled segmentations.
Returns:
A list of sampled piece sequences.
Raises:
ValueError: If samples is not positive.
FileNotFoundError: If model_path does not exist.
Examples:
>>> sample_unigram_segmentations(Path("unigram.model"), "New York", 2)
[["▁New", "▁York"], ["▁Ne", "w", "▁York"]]
"""
if samples <= 0:
raise ValueError("samples must be positive")
if not model_path.exists():
raise FileNotFoundError(model_path)
processor = spm.SentencePieceProcessor(model_file=str(model_path))
# Unigramは複数の分割候補を持てるため、学習時の揺らぎを再現しやすい。
return [
processor.sample_encode_as_pieces(text, nbest_size=-1, alpha=0.5)
for _ in range(samples)
]
このコードでは、BPEとUnigramを直列に組み合わせていません。
同じcorpusに対して、model_type だけを変えた2つのtokenizerモデルを作ります。
これにより、分割の違いを比較できます。
LLMでTokenizationを使うときの注意点
語彙サイズと推論コストのトレードオフ
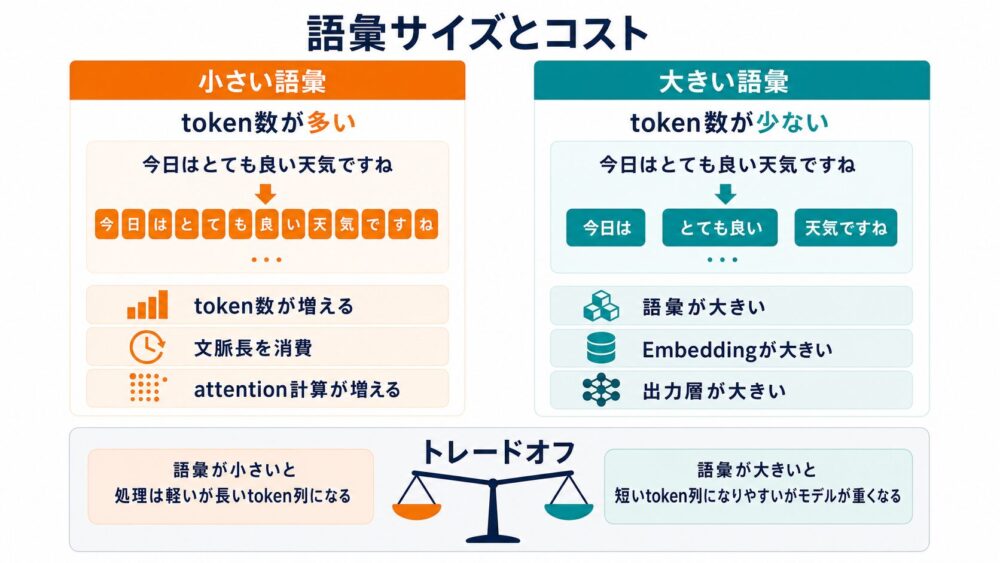
ここからは、SentencePiece論文そのものの新規提案ではなく、LLMでtokenizerを使うときの設計上の注意点を整理します。
Tokenizationでよく出てくる設定が語彙サイズです。
語彙サイズは、tokenizerが扱うtokenの種類数です。
語彙サイズが大きいと、頻出する長い表現を1tokenとして登録しやすくなります。
そのため、同じ文章でもtoken列は短くなりやすいです。
一方で、語彙サイズが大きいほど、Embedding行列や出力層のサイズは大きくなります。
| 語彙サイズ | メリット | デメリット |
|---|---|---|
| 小さい | 未知語に強く、語彙表が軽い | 1文あたりのtoken数が増えやすい |
| 大きい | 短いtoken列になりやすい | 語彙表、Embedding、出力層が重くなる |
| 中程度 | 実用上のバランスを取りやすい | 言語・ドメインごとの調整が必要 |
token数が増えると、LLMが処理する系列長が伸びます。
系列長が伸びると、文脈長を多く消費します。
また、Attention(文中のtoken同士の関係を計算する仕組み)の計算対象も増えます。
そのため、推論レイテンシ、メモリ、API課金などに影響します。
よくある誤解
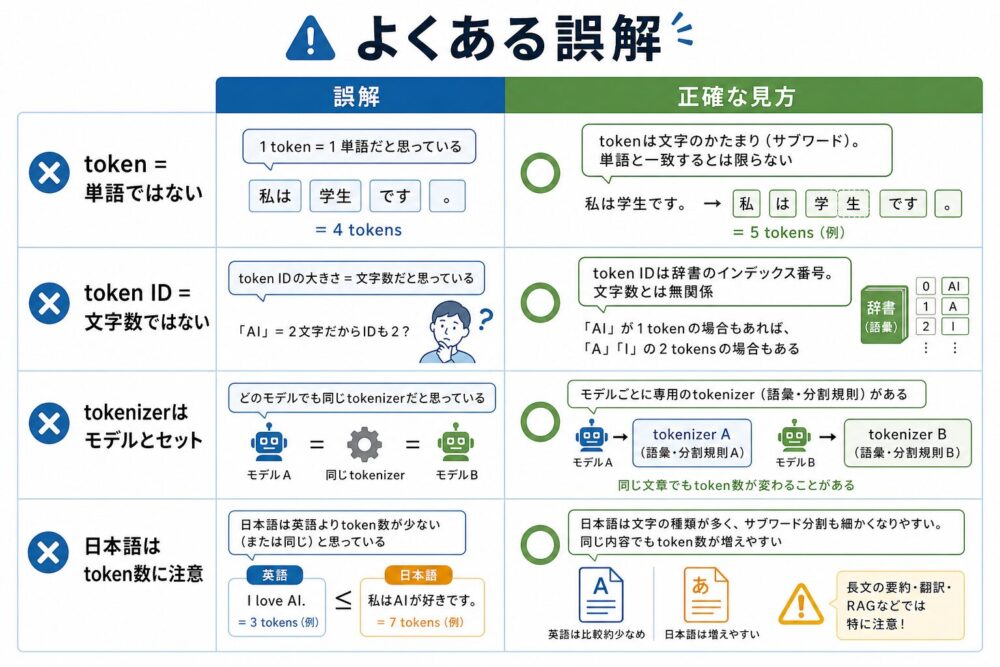
| 誤解 | 正確な情報・解釈 |
|---|---|
| tokenは単語と同じ | tokenは単語、単語の一部、記号、空白を含む単位になりうる |
| token IDは文字数である | token IDは語彙表上の整数インデックス |
| 日本語は文字数が短いので安い | tokenizerによっては日本語のtoken数が増え、コストや文脈長を消費しやすい |
| tokenizerは後から差し替えられる | 語彙IDとEmbeddingが対応しているため、通常はモデルとセットで扱う |
| 正規化は細かい前処理にすぎない | 表記ゆれ、再現性、復元結果に影響する重要な処理 |
| BPEとUnigramを直列に使う | SentencePieceでは基本的にモデルタイプとしてどちらかを選ぶ |
特に重要なのは、tokenizerをモデル本体から独立した軽い前処理だと見なさないことです。
語彙IDとEmbedding行列は対応しているため、tokenizerを変えると、同じ文字列でもモデルに入るID列が変わります。
そのため、Fine-tuningや評価では、学習時と同じtokenizerを使うことが基本です。
限界点
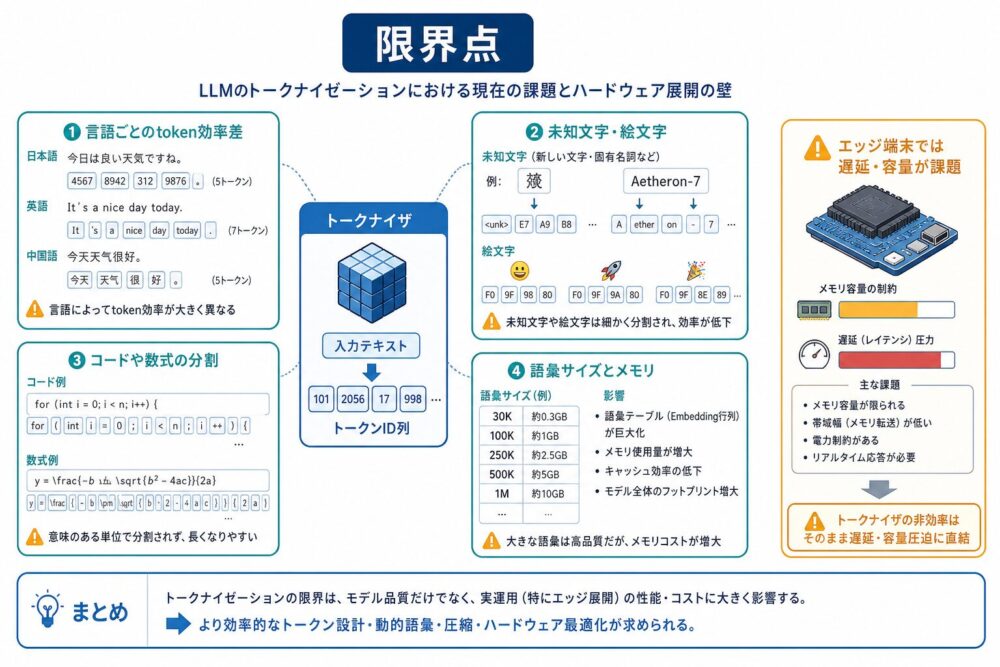
TokenizationはLLMの入口として重要ですが、万能ではありません。
現在のLLMでも、tokenizerの設計は性能、コスト、使いやすさに影響します。
| 限界点 | 内容 | 影響 |
|---|---|---|
| 言語ごとのtoken効率差 | 日本語や一部の言語で、同じ意味を表すのに多くのtokenが必要になる場合がある | API課金、文脈長、推論時間に影響する |
| コードや数式の分割 | snake_case、記号、LaTeX、インデントが不自然に分割されることがある |
コード生成や数式推論の安定性に影響する |
| 正規化の副作用 | 表記ゆれを吸収する一方で、元の表記情報が失われる場合がある | 固有名詞、型番、全角半角が重要な業務で注意が必要 |
| tokenizer変更の難しさ | 語彙IDとEmbeddingが結びついている | 既存モデルに後から差し替えにくい |
| 特殊tokenの複雑化 | chat template、tool call、画像tokenなどが増える | 実装ミスや評価条件のずれが起きやすい |
ハードウェア搭載を考えると、課題はさらに具体的になります。
スマートフォン、車載機器、カメラ、組み込みNPU(ニューラルネットワーク処理専用プロセッサ)でLLMを動かす場合、tokenizerも推論パイプラインの一部になります。
語彙サイズが大きいと、Embedding行列や出力層が大きくなり、モデル全体のメモリ使用量が増えます。
また、token数が多くなると、Attentionの計算対象が増え、レイテンシと消費電力に影響します。
エッジデバイスでは、CPU側でtokenizationを行い、NPU側でモデル本体を実行する構成もありえます。
この場合、tokenizationの前処理が遅いと、NPUが速くても全体の処理時間が縮まりません。
つまり、LLMをハードウェアに載せるには、モデル本体の量子化や高速化だけでなく、tokenizer、正規化、特殊token処理まで含めた全体最適化が必要です。
今後の展望
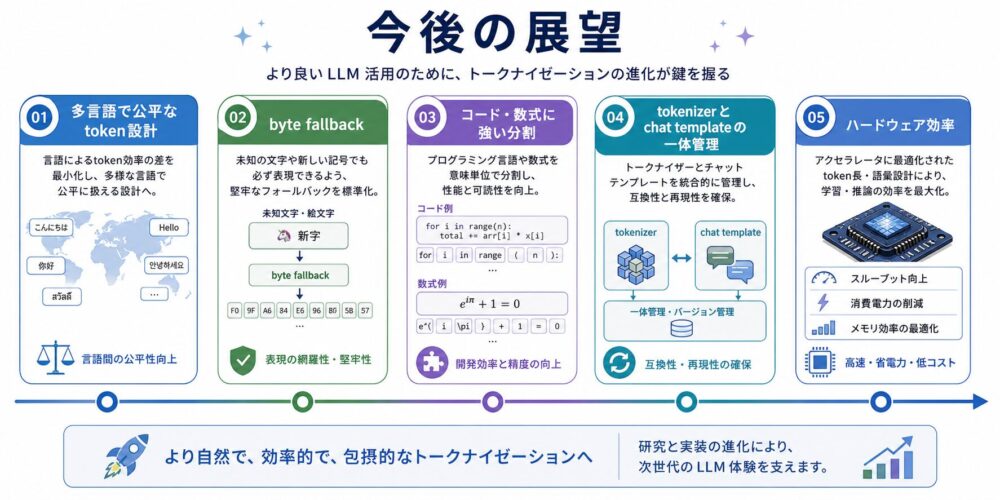
今後のTokenizationでは、単にtoken数を減らすだけでなく、言語、ドメイン、ハードウェアをまたいだ安定性が重要になります。
限界点で見た課題を踏まえると、次のような発展が考えられます。
| 方向性 | 期待される改善 | 注意点 |
|---|---|---|
| 多言語で公平なtoken設計 | 特定言語だけtoken数が極端に増える問題を抑える | 高頻度言語と低頻度言語のバランス設計が難しい |
| byte fallback | 未知文字、絵文字、特殊記号を安定して扱える | byte単位が増えると系列長が伸びる場合がある |
| コード・数式に強い分割 | プログラムやLaTeXを壊しにくくする | 自然言語との語彙配分が課題になる |
| tokenizerとchat templateの一体管理 | 会話形式、tool call、特殊tokenの事故を減らす | モデルごとの差分管理が必要になる |
| ハードウェア効率を意識した語彙設計 | Embeddingや出力層のメモリ、token数、遅延をまとめて最適化する | 精度と軽量化のトレードオフがある |
特に、エッジLLMでは、tokenizerの速度、語彙サイズ、Embedding行列、出力層の計算量がまとめて効いてきます。
今後は、モデル本体だけでなく、入力処理から出力後処理までを含めて、LLMシステム全体を設計する方向へ進むと考えられます。
まとめ
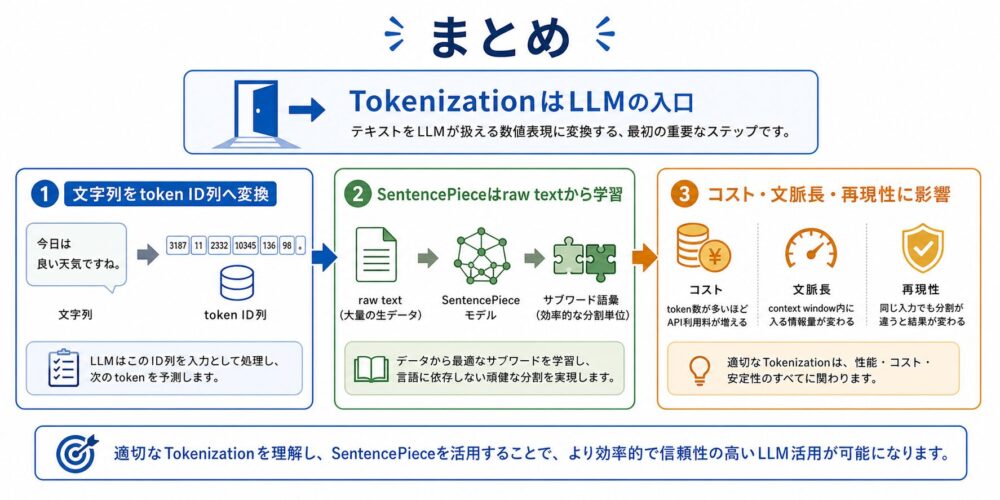
Tokenizationは、LLMの一番入口にある処理です。
しかし、単なる文字列分割ではありません。
モデルが世界をどの粒度の記号列として見るかを決める、重要な設計要素です。
SentencePiece論文は、raw textから言語非依存にサブワードモデルを学習する設計を示しました。
また、空白を含めて可逆に扱い、正規化ルールまでモデルファイルへ含めます。
これにより、NMTや多言語処理で問題になりがちな言語依存のpre-tokenizationを減らせます。
LLMを使う側にとっても、tokenizerはコスト、文脈長、Fine-tuning、RAG、評価に関わる基礎部品です。
「文字数」ではなく「token数」で考えることが、LLMアプリケーション設計の第一歩になります。
関連技術
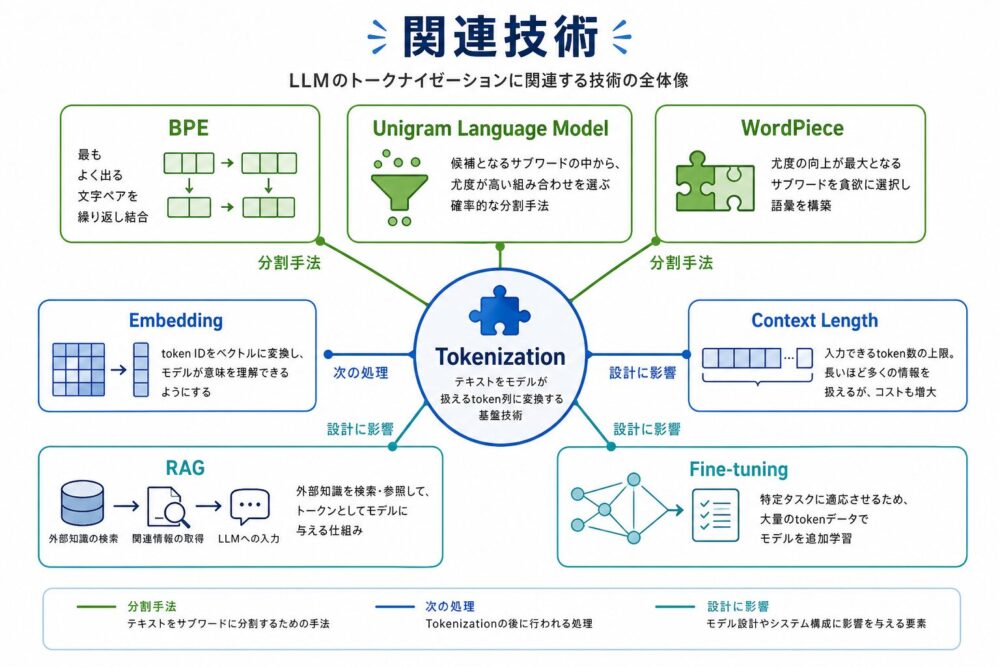
| 技術 | 関係 |
|---|---|
| BPE | 頻出ペアを結合してサブワード語彙を作る |
| subword-nmt | NMTでBPEを使う代表的なサブワード分割ツール |
| Unigram Language Model | サブワード分割を確率モデルとして扱う |
| WordPiece | BERT系でよく知られるサブワード分割 |
| Embedding | token IDをベクトルへ変換する次の処理 |
| Context Length | token数で測られる文脈長 |
| RAG | 文書をchunkへ分けるときにtoken数の見積もりが重要になる |
| Fine-tuning | 学習時と推論時で同じtokenizerを使う必要がある |
次に読むべき記事
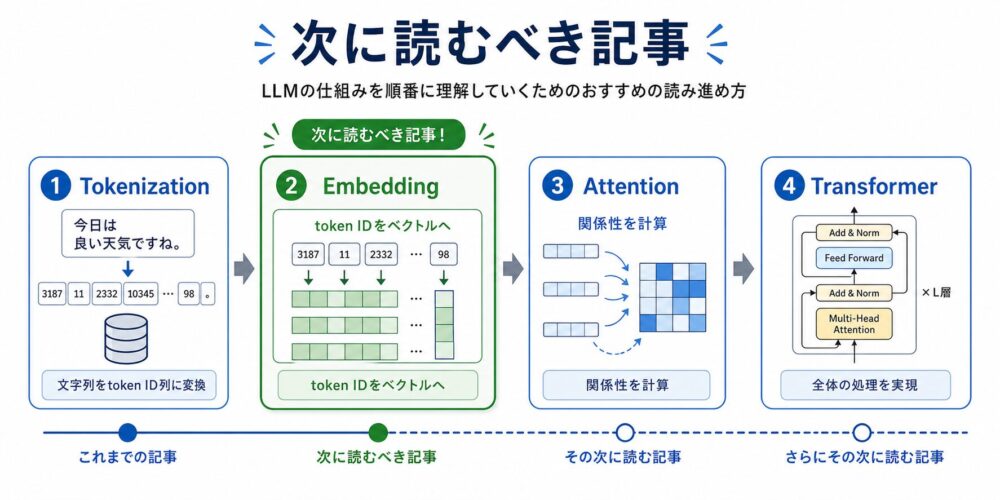
次はEmbeddingです。
Tokenizationで得られたtoken IDは、そのまま意味を持つ数値ではありません。
Embedding層を通すことで、token IDはモデルが計算できるベクトルへ変換されます。

コメント