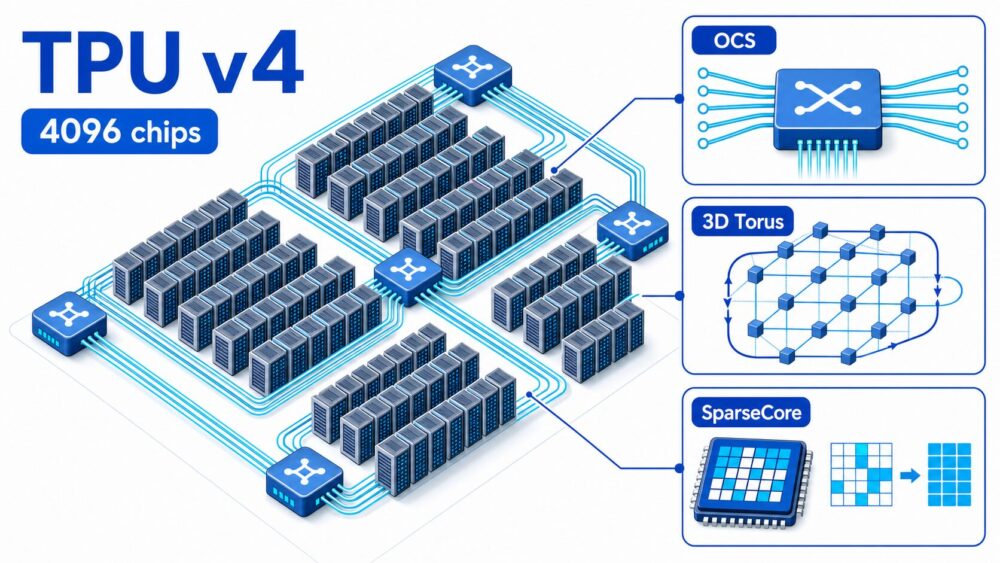
TPU v4は、Googleが大規模な機械学習モデル向けに設計した、第4世代TPU(Tensor Processing Unit、機械学習向け専用プロセッサ)です。
Jouppiらの論文では、TPU v4の重要な特徴として、OCS(Optical Circuit Switch、光回線を物理的に切り替えるスイッチ)、再構成可能なトポロジー(チップ間の接続構造)、SparseCore(embedding処理向けの疎計算アクセラレータ)が示されています。
本記事では、特にOCS、トポロジー、SparseCoreについて、なぜ必要だったのか、どのような技術なのか、どのような効果があるのかを中心に整理します。
本記事の目的
本記事の目的は、TPU v4を「チップ単体の性能向上」だけでなく、「4096チップ級の機械学習スーパーコンピュータをどう実用運用するか」という視点で理解することです。
大規模言語モデル(LLM、Large Language Model)や推薦モデルでは、単一チップの演算性能だけでは不十分です。
多数のチップを接続し、モデルやデータを分散し、途中で故障が出ても学習ジョブを継続し、embedding(IDをベクトルへ変換する表現学習の仕組み)のような疎な処理も高速に扱う必要があります。
TPU v4論文の面白い点は、これらを個別の小さな改善としてではなく、システム全体の設計として扱っていることです。
特に重要なのは次の3点です。
| 技術 | 目的 | 技術内容 | 効果 |
|---|---|---|---|
| OCS | 大規模Podの柔軟な再構成 | 光ファイバ接続を回線単位で切り替える | スケール、可用性、利用率、消費電力、性能を改善 |
| トポロジー | ワークロードに合う通信構造を選ぶ | 3D torusやtwisted 3D torusを構成できる | AllReduceや近傍通信の効率を上げる |
| SparseCore | embedding中心の疎な処理を高速化 | TensorCoreとは別に疎アクセス向けデータフロー処理を持つ | embedding依存モデルを5倍から7倍高速化 |
TPU v4は、単に「TPU v3より速いチップ」ではありません。
論文では、TPU v4がTPU v3に対して2.1倍の性能、2.7倍の性能/Wattを示し、4096チップ構成ではTPU v3 Podより約10倍高速なシステムになったと説明されています。
その背景にあるのが、OCS、トポロジー、SparseCoreです。
3文要約
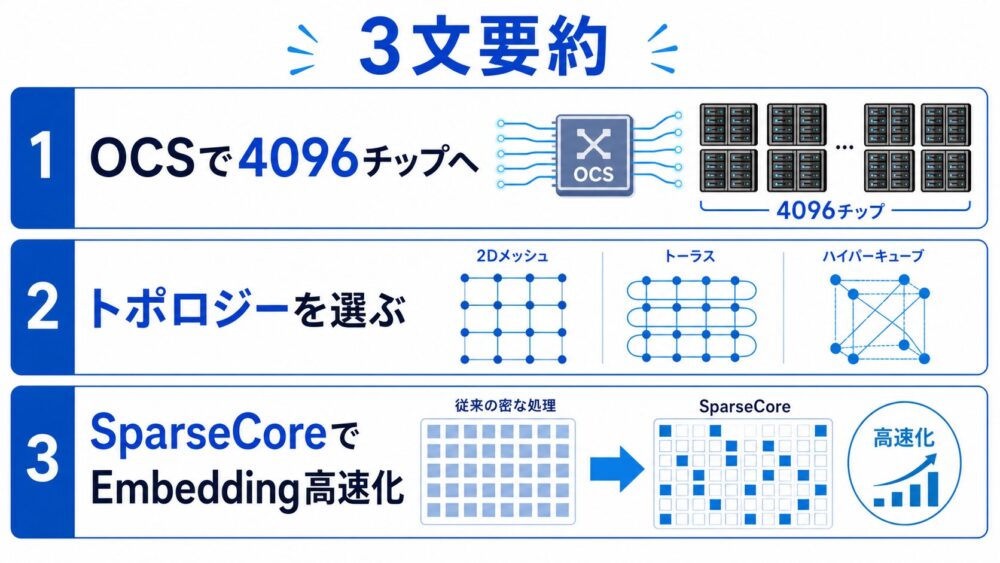
TPU v4は、4096チップ規模の機械学習スーパーコンピュータを実用運用するために、光回線を再構成できるOCSを導入したTPU世代です。
OCSにより、物理的な配線を固定せず、3D torusやtwisted 3D torusのような通信トポロジーを選びやすくなり、スケール、可用性、利用率、消費電力、性能の改善につながります。
さらに、SparseCoreによりembeddingを多用する推薦モデルの疎な処理を高速化し、論文ではembedding依存モデルで5倍から7倍の高速化が示されています。
論文情報
| 項目 | 内容 |
|---|---|
| 論文タイトル | TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings |
| 著者 | Norman P. Jouppi, George Kurian, Sheng Li, Peter Ma, Rahul Nagarajan, Lifeng Nai, Nishant Patil, Suvinay Subramanian, Andy Swing, Brian Towles, Cliff Young, Xiang Zhou, Zongwei Zhou, David Patterson |
| 発表年 | 2023年 |
| 分野 | Hardware Architecture、Artificial Intelligence、Machine Learning、Performance |
| リンク | TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings |
| arXiv PDF |
論文のタイトルにある「Optically Reconfigurable」は、光を使ったチップ間接続を再構成できる、という意味です。
ここがTPU v4論文の中心です。
従来のアクセラレータ説明では、行列積器、メモリ帯域、ピークFLOPS(Floating Point Operations Per Second、1秒あたりの浮動小数点演算回数)に注目しがちです。
しかし、TPU v4論文は、より大きな単位である「スーパーコンピュータとしてのTPU」を扱っています。
つまり、次のような問いに答える論文です。
| 問い | TPU v4での答え |
|---|---|
| 4096チップをどう接続するか | OCSを使って光回線を再構成する |
| ワークロードに応じた通信構造をどう選ぶか | 3D torusやtwisted 3D torusを使えるようにする |
| 故障や利用率の問題をどう扱うか | 固定配線ではなく、再構成可能なsliceを作る |
| embedding中心の推薦モデルをどう速くするか | SparseCoreをチップ内に追加する |
| 消費電力やコストをどう抑えるか | 光回線とOCSによりInfiniBand相当の外部ネットワーク依存を減らす |
背景目的:なぜTPU v4ではチップ単体だけでなく接続が重要になったのか

大規模な機械学習では、演算器を増やせば必ず速くなるわけではありません。
チップ数を増やすほど、チップ間通信がボトルネックになります。
たとえば、巨大なTransformer(AttentionとFeed Forward Networkを積み重ねる深層学習モデル)を学習する場合、モデル並列、データ並列、パイプライン並列などを組み合わせます。
データ並列では、各チップが別々のミニバッチを処理し、勾配をAllReduce(複数デバイスの値を集約して全員へ配る通信)で同期します。
モデル並列では、ひとつの層や行列を複数チップに分けるため、より細かい通信が発生します。
このとき、通信構造が悪いと、演算器が待ち時間で止まります。
演算性能が高くても、データが届かなければ行列積器は働けません。
TPU v4が対象にしているのは、まさにこの問題です。
論文では、TPU v4がTPU v3より単体性能を高めただけでなく、スーパーコンピュータ規模を4倍の4096チップへ拡大し、全体では約10倍高速になったと説明されています。
この「約10倍」は、チップ単体性能だけでは説明できません。
大規模システムとしての接続、トポロジー、利用率、故障時の再構成が重要になります。
チップ数が増えると何が難しくなるのか
チップ数が増えると、次の問題が強くなります。
| 課題 | 内容 | TPU v4で重要になる理由 |
|---|---|---|
| 通信帯域 | チップ間でどれだけ速くデータを送れるか | AllReduceやモデル並列の性能に直結する |
| 通信距離 | 何ホップで相手チップへ届くか | ホップ数が増えると遅延と混雑が増える |
| 故障耐性 | 一部のチップやリンクが壊れても使えるか | 4096チップでは故障確率が無視できない |
| 利用率 | 必要なサイズのsliceを切り出せるか | 固定Podだと空き資源が出やすい |
| セキュリティ | ユーザー間の通信分離ができるか | Cloud環境では物理的分離に近い性質が重要 |
| 消費電力 | ネットワークがどれだけ電力を使うか | 大規模Podでは通信電力も大きくなる |
GPUクラスタでは、InfiniBand(高性能計算で使われる低遅延ネットワーク)などの外部ネットワークを使う構成が一般的です。
一方、TPU v4論文では、OCSと光部品がシステムコストの5%未満、システム電力の3%未満であると説明されています。
これは、単なる機能追加ではなく、巨大なMLシステムのTCO(Total Cost of Ownership、総保有コスト)と運用性に効く設計です。
従来技術の課題:固定トポロジーでは大規模運用が硬くなる
TPU v2/v3のようなPod構成では、チップを高速な専用インターコネクトでつなぎ、分散学習を実行します。
これは非常に強力ですが、物理的な接続が固定に近いほど、運用上の柔軟性が下がります。
たとえば、次のような状況を考えます。
| 状況 | 固定トポロジーで起きやすい問題 |
|---|---|
| 128チップだけ使いたい | 連続した良い形の領域を切り出せないことがある |
| 一部リンクが故障した | トポロジー全体の性能が落ちる、またはsliceを避ける必要がある |
| ワークロードの通信パターンが違う | あるモデルには合うが別のモデルには合わない |
| 複数ユーザーへsliceを割り当てる | ユーザー間の分離と資源利用率の両立が難しい |
| Podを段階的に増設したい | 配線設計とデプロイが硬くなる |
固定トポロジーは、ハードウェア設計としては分かりやすいです。
しかし、クラウドで多数のユーザー、複数サイズの学習ジョブ、長時間ジョブ、故障、保守、増設を扱うと、固定であることが制約になります。
TPU v4のOCSは、この制約を緩めるための技術です。
提案手法の概要:TPU v4は何を変えたのか
TPU v4論文の提案を大きく分けると、次のようになります。
| 提案要素 | 解決したい課題 | 代表的な効果 |
|---|---|---|
| OCS | 4096チップ規模の接続を固定配線だけで運用しにくい | 接続を再構成し、可用性、利用率、性能を改善する |
| 再構成可能トポロジー | ワークロードごとに望ましい通信構造が違う | 3D torusやtwisted 3D torusを選べる |
| SparseCore | embeddingの疎なアクセスがTensorCoreだけでは効率化しにくい | embedding依存モデルを5倍から7倍高速化する |
| TPU v4チップ | TPU v3より高性能、高効率な演算基盤 | TPU v3比で2.1倍性能、2.7倍性能/Watt |
| 4096チップPod | LLMなど巨大モデルの学習需要に対応する | TPU v3 Podより約10倍高速なシステム |
以降では、ユーザー指定の重点であるOCS、トポロジー、SparseCoreを詳しく見ます。
OCSとは何か:光回線を再構成してPodを柔らかくする
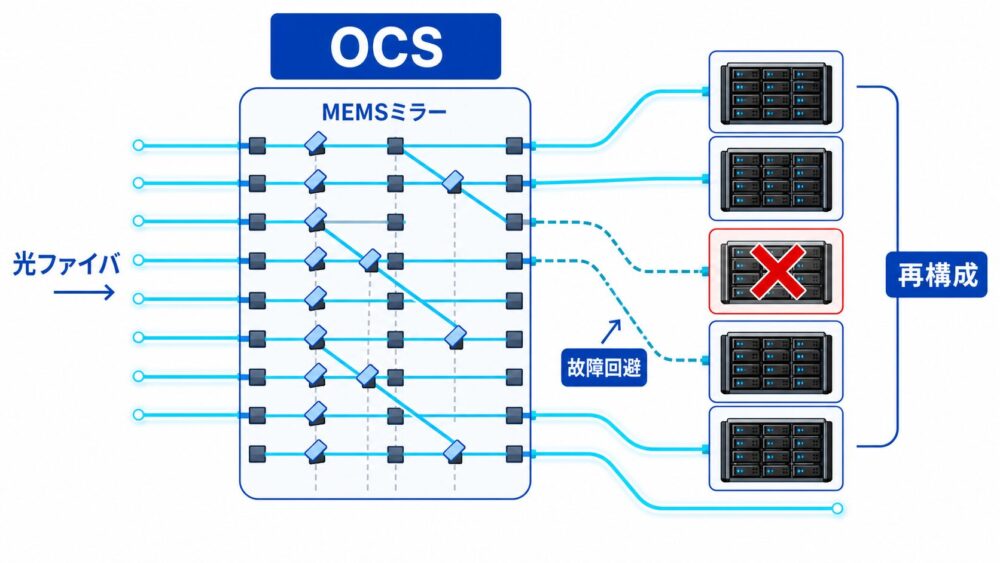
OCSは、Optical Circuit Switchの略です。
日本語では「光回線スイッチ」と考えると分かりやすいです。
通常のネットワークスイッチは、パケット(小さな通信単位)を受け取り、宛先に応じて転送します。
一方、OCSはパケットを細かく処理するのではなく、光ファイバ間の接続を回線単位で切り替えます。
イメージとしては、巨大な配線盤をソフトウェアから切り替えるようなものです。
OCSの目的
TPU v4でOCSが必要になった目的は、単に「光だから速い」ではありません。
論文では、OCSが次のような面を改善すると説明されています。
| 目的 | 意味 |
|---|---|
| Scale | 4096チップ規模へ拡張する |
| Availability | 故障チップや故障リンクを避けてsliceを作る |
| Utilization | 空いている資源を使いやすくする |
| Modularity | Podをモジュール単位で構成しやすくする |
| Deployment | 配備や増設を柔軟にする |
| Security | ユーザー間の通信分離を強める |
| Power | 外部ネットワークより低電力にする |
| Performance | ワークロードに合う接続で通信効率を上げる |
ここで重要なのは、OCSが性能だけの機能ではないことです。
大規模なクラウド基盤では、可用性、利用率、保守性、セキュリティも性能と同じくらい重要です。
4096チップのうち一部に問題があったとき、固定配線だけでは「そこを含むsliceを使えない」という制約が出やすくなります。
OCSで接続を切り替えられれば、正常なチップ群をまとめて、実行可能なsliceを再構成しやすくなります。
OCSの技術内容
OCSは、光ファイバの入力と出力を物理的に接続し直す仕組みです。
論文の抽象では、TPU v4のOCSと光部品は、InfiniBandより安価、低電力、高速であり、システムコストの5%未満、システム電力の3%未満と説明されています。
ここでのポイントは、OCSが汎用のパケットネットワークを置き換えるものではなく、TPU Pod内部の接続を効率よく作るための部品だということです。
| 比較軸 | パケットスイッチ | OCS |
|---|---|---|
| 切り替え単位 | パケットごと | 回線ごと |
| 柔軟性 | 通信ごとに宛先を変えやすい | 再構成後の回線は固定的 |
| オーバーヘッド | パケット処理が必要 | データ転送中の処理が少ない |
| 向く用途 | 汎用ネットワーク | 大規模アクセラレータの安定した高帯域接続 |
| TPU v4での役割 | 主役ではない | Pod内部の再構成可能な光接続 |
機械学習の分散学習では、通信パターンが比較的構造化されています。
たとえば、AllReduce、近傍通信、モデル分割に伴う同期などは、完全にランダムな通信ではありません。
そのため、ワークロードに合う回線を作っておき、その回線上で大量のデータを流すOCSの考え方と相性が良いです。
OCSの効果
OCSの効果は、次のように整理できます。
| 効果 | 具体的な意味 |
|---|---|
| 大規模化 | 4096チップのPodを構成しやすくなる |
| 故障回避 | 問題のあるリンクやチップを避けたsliceを作りやすい |
| 利用率改善 | 空きチップをより有効に組み合わせられる |
| トポロジー選択 | 3D torusやtwisted 3D torusを構成できる |
| 消費電力削減 | 論文では光部品とOCSの電力比率が小さいと説明されている |
| セキュリティ | ユーザーごとの物理的に近い通信分離を作りやすい |
注意点として、OCSは万能ではありません。
回線を切り替える仕組みなので、GPUのSM(Streaming Multiprocessor、GPU内の実行ユニット)のようにサイクル単位で細かく変化するものではありません。
OCSの価値は、ジョブやsliceの単位で、接続構造を柔軟に作れることです。
トポロジーとは何か:チップ間通信の「道の形」を決める
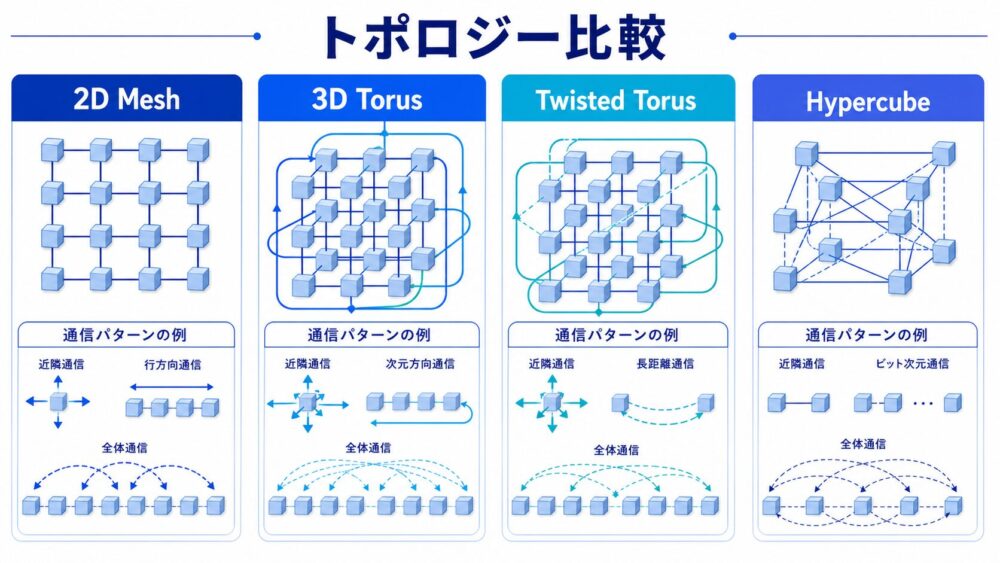
トポロジーとは、ノードとリンクの接続構造です。
TPU v4の文脈では、ノードがTPUチップ、リンクがチップ間接続に相当します。
同じ4096チップでも、どのチップがどのチップと直接つながるかによって、通信性能は大きく変わります。
代表的なトポロジーの比較
| トポロジー | 構造 | 長所 | 短所 | 向きやすい通信 |
|---|---|---|---|---|
| 2D mesh | 縦横の格子状接続 | 実装が分かりやすい | 遠いノードへのホップ数が増えやすい | 画像処理の近傍通信など |
| 3D torus | 3次元格子の端を巻き戻す | 平均距離を短くしやすい | 配線と割当が複雑になる | 大規模な近傍通信、AllReduce |
| twisted 3D torus | 3D torusにねじれを加える | 通信混雑を分散しやすい | 理解とマッピングが難しい | 大規模分散学習 |
| hypercube | 次元ごとに接続する | 対数的な経路が作りやすい | 大規模実装の配線が複雑 | 集約通信、探索的な通信 |
TPU v4論文では、ユーザーが必要に応じてtwisted 3D torus topologyを選べると説明されています。
これは重要です。
なぜなら、機械学習の通信はワークロードによって異なるからです。
Transformerの学習、CNN(Convolutional Neural Network、畳み込みニューラルネットワーク)、推薦モデル、Mixture of Experts(複数の専門家モデルの一部を選択して使うモデル)では、通信の粒度や偏りが違います。
固定の2D meshだけでは、すべての通信に最適とは限りません。
3D torusの目的
3D torusの目的は、チップ間の平均距離を短くし、通信負荷を分散することです。
2D meshでは、左上のチップから右下のチップへ行くには、多くのホップが必要になります。
3D torusでは、3次元方向に経路が増え、さらに端と端がつながるため、遠回りを避けやすくなります。
概念的には、次のような違いです。
| 観点 | 2D mesh | 3D torus |
|---|---|---|
| 次元 | 2次元 | 3次元 |
| 端の扱い | 端で止まる | 端が反対側につながる |
| 経路の選択肢 | 少なめ | 多め |
| 平均ホップ数 | 増えやすい | 抑えやすい |
| 大規模Podとの相性 | 規模が大きいほど厳しい | 大規模化に向く |
AllReduceを考えると、通信は全体に広がります。
あるチップだけが通信の通り道になると、そこが混雑します。
3D torusでは、経路を複数方向へ分散しやすくなるため、大規模な同期通信で有利になります。
twisted 3D torusの目的
twisted 3D torusは、3D torusに「ねじれ」を入れた構造です。
直感的には、端同士を単純につなぐのではなく、接続先をずらすことで、通信経路の偏りを減らす設計です。
ここでの目的は、単に見た目を複雑にすることではありません。
大規模システムでは、規則的すぎるトポロジーが特定方向の混雑を生むことがあります。
ねじれを入れると、論理的な距離や通信負荷の分布を改善できる場合があります。
| 項目 | 通常の3D torus | twisted 3D torus |
|---|---|---|
| 端の接続 | 同じ位置同士をつなぐ | ずらしてつなぐ |
| 目的 | 端の不利を減らす | 経路の偏りをさらに減らす |
| 設計難度 | 中 | 高 |
| TPU v4での意味 | 基本的な大規模接続 | ワークロードに合わせた選択肢 |
TPU v4で重要なのは、OCSにより、このような論理トポロジーを固定配線だけに縛られず作れることです。
トポロジーは、OCSとセットで価値を持ちます。
OCSがなければ、トポロジーは基本的に設計時点で決まります。
OCSがあれば、実行するワークロードやsliceの大きさに応じて、より適した接続構造を作りやすくなります。
トポロジーの効果
トポロジー設計の効果は、ピークFLOPSには直接現れにくいです。
しかし、実アプリケーションでは非常に重要です。
| 効果 | なぜ効くか |
|---|---|
| 通信待ちの削減 | 演算器がデータ待ちで止まる時間を減らす |
| AllReduceの高速化 | 勾配同期の通信経路を分散できる |
| 大規模モデル並列の効率化 | 層やテンソルを分割したときの隣接通信を改善する |
| slice割当の柔軟化 | ジョブサイズに合う形でチップ群を切り出せる |
| 障害時の性能維持 | 故障箇所を避けても有効な接続を作りやすい |
この意味で、TPU v4のトポロジーは「ネットワークの話」ではありますが、実際には「学習性能の話」です。
大規模学習では、通信が遅ければ演算器のピーク性能を使い切れません。
TPU v4は、演算性能だけでなく、通信構造を含めてML性能を引き出す設計になっています。
SparseCoreとは何か:embeddingの疎な処理を専用に速くする
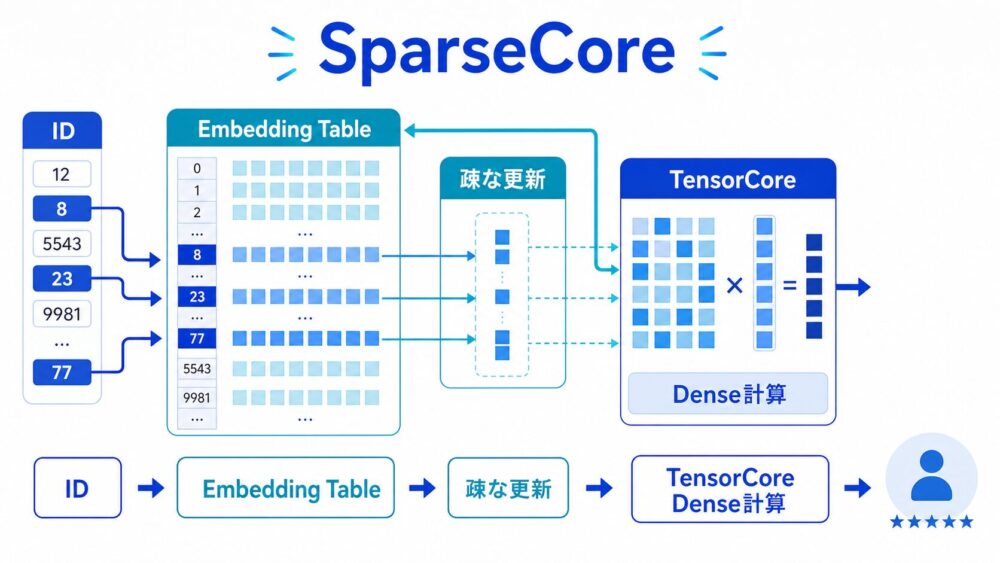
SparseCoreは、TPU v4チップに追加された、embedding向けのデータフロー処理器です。
論文では、SparseCoreはembeddingに依存するモデルを5倍から7倍高速化し、チップ面積と電力の約5%だけを使うと説明されています。
これはかなり大きな効果です。
なぜなら、embedding処理は、通常の行列積とは性質が違うからです。
embedding処理はなぜ普通の行列積と違うのか
LLMや推薦モデルでは、入力IDをベクトルに変換します。
たとえば、単語ID、商品ID、ユーザーID、広告IDなどをembedding tableから取り出します。
概念的には、次のような処理です。
\[ e_i = E[id_i] \]
ここで、\(E\) はembedding table、\(id_i\) は入力ID、\(e_i\) は取り出されたembeddingベクトルです。
この処理は、密な行列積とは違います。
行列積では、連続したメモリから大きなブロックを読み、積和演算を高密度に実行できます。
一方、embedding lookup(IDに対応するベクトルを表から取り出す処理)は、巨大な表から一部の行だけを読む疎なアクセスになります。
| 処理 | Denseな行列積 | Embedding lookup |
|---|---|---|
| データアクセス | 連続的、大きなブロック | ランダムに近い疎な行アクセス |
| 演算密度 | 高い | 低い |
| ボトルネック | 演算器、メモリ帯域 | メモリアクセス、集約、更新 |
| 向くハードウェア | TensorCore、MXU、Systolic Array | SparseCoreのような疎アクセス処理器 |
TPUのTensorCoreやMXU(Matrix Multiply Unit、行列積ユニット)は、密な行列演算に強いです。
しかし、推薦モデルのように巨大なembedding tableへ疎にアクセスする処理では、演算器よりメモリアクセスや集約が支配的になります。
この差を埋めるのがSparseCoreです。
SparseCoreの目的
SparseCoreの目的は、embedding中心のモデルを、TPUの主計算器だけに任せず、疎な処理に合った専用パスで高速化することです。
特に推薦モデルでは、ユーザー、商品、広告、カテゴリ、履歴など、多数の離散IDを扱います。
それぞれのIDをembeddingに変換し、複数のembeddingを集約し、その後にDenseなニューラルネットワークへ渡します。
この流れでは、前半が疎な処理、後半が密な処理になりやすいです。
| 段階 | 主な処理 | 向くハードウェア |
|---|---|---|
| ID入力 | ユーザーID、商品ID、単語IDなど | 汎用制御、SparseCore |
| Embedding lookup | 巨大表から該当行を読む | SparseCore |
| 集約 | 複数embeddingをsumやmeanでまとめる | SparseCore |
| Dense MLP | 行列積、activation | TensorCore、MXU |
| 出力 | スコア、分類、予測 | TensorCore、汎用処理 |
SparseCoreは、この前半の疎な部分を高速化します。
SparseCoreの技術内容
論文では、SparseCoreをdataflow processors(データの流れに沿って処理するプロセッサ)として説明しています。
ここでのdataflowとは、命令を逐次実行するCPU的な処理ではなく、入力データが流れてくる経路に沿って、必要な変換、集約、更新を効率よく行う考え方です。
SparseCoreは、次のような処理に向いていると整理できます。
| 処理 | なぜSparseCoreに向くか |
|---|---|
| embedding lookup | 疎なIDアクセスを前提にできる |
| embedding集約 | 複数IDのベクトルをまとめる処理が多い |
| sparse update | 学習時に使われた行だけを更新する |
| feature processing | 推薦モデルの多数の離散特徴を処理する |
| Dense計算への橋渡し | TensorCoreへ渡す前の表現を整える |
重要なのは、SparseCoreがTensorCoreの代替ではないことです。
SparseCoreは、行列積を置き換えるためのものではありません。
SparseCoreは、TensorCoreが苦手な疎なembedding処理を受け持ち、TensorCoreはDenseな行列演算を受け持ちます。
この役割分担により、推薦モデルのような「疎な前処理 + 密なニューラルネットワーク」のワークロードを効率よく動かせます。
SparseCoreの効果
論文では、SparseCoreがembeddingに依存するモデルを5倍から7倍高速化すると説明されています。
また、そのために使うチップ面積と電力は約5%とされています。
この効果は、次のように読むと分かりやすいです。
| 観点 | 意味 |
|---|---|
| 5倍から7倍高速化 | embedding部分がボトルネックだったモデルで大きく効く |
| 約5%の面積 | チップ全体を大きく増やさずに専用処理を追加できる |
| 約5%の電力 | 消費電力の増加に対して性能効果が大きい |
| 推薦モデルへの効果 | Googleの広告、検索、推薦のようなID特徴量中心のMLで重要 |
ここで注意すべきなのは、SparseCoreの効果はすべてのモデルに同じように出るわけではないことです。
DenseなTransformerだけを見ると、SparseCoreの寄与は限定的かもしれません。
一方、巨大なembedding tableを持つ推薦モデルでは、Denseな行列積器だけを強化してもボトルネックが残ります。
TPU v4がSparseCoreを入れた理由は、MLワークロードがDense演算だけではなくなっていたからです。
実験結果:TPU v4は何を達成したのか
論文の抽象で示されている主な結果を整理します。
| 評価観点 | 論文で示されている結果 |
|---|---|
| TPU v3比の性能 | 2.1倍 |
| TPU v3比の性能/Watt | 2.7倍 |
| Pod規模 | TPU v4は4096チップで、TPU v3 Podの4倍 |
| システム全体性能 | TPU v3 Podより約10倍高速 |
| SparseCore | embedding依存モデルを5倍から7倍高速化 |
| OCSと光部品のコスト | システムコストの5%未満 |
| OCSと光部品の電力 | システム電力の3%未満 |
| Graphcore IPU Bow比較 | 同程度規模のシステムで4.3倍から4.5倍高速 |
| NVIDIA A100比較 | 1.2倍から1.7倍高速、1.3倍から1.9倍低電力 |
| Cloud環境のエネルギー | 一般的なオンプレミスデータセンターの同時期DSAより約3分の1のエネルギー |
| CO2e | 一般的なオンプレミスデータセンターの同時期DSAより約20分の1 |
これらの結果は、TPU v4の価値が単体チップ性能だけではないことを示しています。
特に重要なのは、次の読み方です。
| 結果 | 読み方 |
|---|---|
| 2.1倍性能、2.7倍性能/Watt | チップ世代として効率が上がった |
| 4096チップ、約10倍高速 | 大規模システムとしての設計が効いた |
| OCSが低コスト、低電力 | 再構成可能性を大きなコストなしに入れた |
| SparseCoreが5倍から7倍 | Dense演算以外のMLワークロードに対応した |
ただし、比較結果は評価条件に依存します。
論文で示されている性能は、論文が扱うベンチマークやシステム構成に基づくものです。
すべてのモデル、すべてのデータセンター、すべての実装で同じ倍率が出ると読むべきではありません。
TPU v4の設計をLLM学習と推薦モデルから見る
TPU v4の設計は、大きく2種類のワークロードを意識して読むと理解しやすいです。
ひとつはLLMのような巨大なDenseモデルです。
もうひとつは、推薦モデルのようなembedding中心のモデルです。
| ワークロード | 主な課題 | TPU v4で効く技術 |
|---|---|---|
| LLM学習 | 大規模Dense演算、AllReduce、モデル並列通信 | TPU v4チップ、OCS、3D torus、twisted 3D torus |
| 推薦モデル | 巨大embedding table、疎アクセス、疎更新 | SparseCore、HBM、TensorCoreとの分担 |
| Cloud学習基盤 | 複数ユーザー、故障、資源割当 | OCS、slice再構成、トポロジー選択 |
LLMでは、通信トポロジーが重要です。
モデルが大きいほど、複数チップに分割して学習する必要があり、通信待ちが増えます。
このとき、OCSとトポロジー選択が効きます。
推薦モデルでは、SparseCoreが重要です。
embedding lookupと疎更新が多いモデルでは、Dense演算器だけを増やしても性能が出にくいからです。
TPU v4は、この2つの方向を同時に見ています。
高画質タスクやカメラAIへの応用を考える
TPU v4はデータセンター向けの大規模MLアクセラレータです。
スマートフォンやカメラ内のNPU(Neural Processing Unit、ニューラルネットワーク専用処理器)へそのまま載る技術ではありません。
しかし、設計思想として学べる点はあります。
高画質タスクで参考になる点
Denoise(ノイズ除去)、Demosaic(ベイヤー配列からRGB画像を復元する処理)、Super Resolution(超解像)のような画像処理AIでは、Denseな畳み込みや行列演算が多くなります。
そのため、SparseCoreそのものより、トポロジーと専用処理の考え方が参考になります。
| TPU v4の考え方 | カメラAIでの対応する考え方 |
|---|---|
| Dense演算とSparseCoreを分ける | ISP処理、CNN処理、メモリ転送を分けて最適化する |
| OCSで接続を再構成する | SoC内でNPU、ISP、DRAM、キャッシュ間の帯域設計を重視する |
| トポロジーをワークロードに合わせる | 画像パイプラインのデータフローに合わせて処理順を設計する |
| embedding専用処理を入れる | 画像処理なら畳み込み、attention、upsamplingに専用化する |
カメラAIでは、TPU v4のような4096チップ接続は必要ありません。
一方で、「どの処理を汎用演算器に任せ、どの処理を専用ハードウェア化するか」という考え方は共通しています。
SparseCoreはembedding用ですが、同じ発想で、画像処理ではresize、filter、tile transfer、畳み込み前処理などを専用化する余地があります。
そのまま適用しにくい点
TPU v4のOCSはデータセンター規模の技術です。
カメラやスマートフォンでは、チップ間を光ファイバで大規模に再構成する必要はありません。
むしろ、電力、発熱、DRAM帯域、リアルタイム性が支配的です。
| TPU v4 | カメラAI |
|---|---|
| 4096チップ規模 | 1つのSoC内、または少数チップ |
| 光回線の再構成 | オンチップバス、NoC、メモリ階層 |
| LLMや推薦モデルの大規模学習 | 推論中心、低遅延、低電力 |
| Cloud Slice | アプリや撮影モードごとのリソース割当 |
したがって、TPU v4の技術をカメラAIへ直接移植するのではなく、設計思想を読むのが現実的です。
関連技術との違い
TPU v4を理解するには、GPUクラスタ、TPU v3、NPU、InfiniBandとの違いを整理すると分かりやすいです。
| 技術 | 主な用途 | TPU v4との違い |
|---|---|---|
| TPU v3 | 大規模学習向けTPU Pod | TPU v4はチップ性能、性能/Watt、Pod規模、OCS再構成性を強化 |
| GPUクラスタ | 汎用的なAI/HPC学習 | GPUは柔軟性が高いが、TPU v4は専用PodとOCSでML特化の効率を狙う |
| InfiniBand | 高性能クラスタネットワーク | TPU v4論文ではOCSと光部品がより安価、低電力、高速と説明される |
| NPU | エッジ推論、低電力推論 | TPU v4はデータセンター学習・推論基盤で、規模と通信設計が別物 |
| Sparse accelerator | 疎行列やembedding向け処理 | TPU v4ではSparseCoreとしてチップ内に統合される |
ここで避けたい誤解は、「TPU v4がGPUより常に優れている」という読み方です。
論文の比較は、対象システム、ベンチマーク、電力条件に依存します。
GPUはソフトウェアエコシステムや汎用性が強く、TPU v4はGoogleのML基盤として、専用化と大規模運用に強く寄せた設計です。
よくある誤解
| よくある誤解 | 正確な情報・解釈 |
|---|---|
| TPU v4は単にTPU v3より速いチップ | チップ性能に加え、OCS、トポロジー、SparseCoreを含むシステム設計が重要 |
| OCSは普通のネットワークスイッチと同じ | パケット単位ではなく、光回線単位で接続を再構成する |
| 3D torusは必ずすべてのモデルで最速 | 通信パターンに依存するため、ワークロードに合うかが重要 |
| SparseCoreはTensorCoreの代替 | Dense演算ではなく、embeddingなどの疎な処理を補完する |
| SparseCoreの5倍から7倍高速化は全モデルに当てはまる | embedding依存モデルでの効果として読むべき |
| OCSがあるので故障の影響は完全になくなる | 故障回避やslice再構成に有利だが、故障そのものを消すわけではない |
| TPU v4の技術はそのままスマホNPUへ使える | データセンター規模の技術なので、設計思想として読むのが現実的 |
まとめ
TPU v4論文の中心は、4096チップ規模のMLスーパーコンピュータを、どう高性能かつ実用的に運用するかです。
その鍵が、OCS、トポロジー、SparseCoreです。
OCSは、光回線を再構成することで、スケール、可用性、利用率、セキュリティ、電力、性能を改善します。
トポロジーは、3D torusやtwisted 3D torusのような接続構造を選ぶことで、AllReduceやモデル並列通信の効率に影響します。
SparseCoreは、embedding中心の疎な処理を専用に扱い、論文ではembedding依存モデルで5倍から7倍の高速化を示しています。
TPU v4は、チップ単体の進化だけではありません。
大規模ML基盤では、演算器、メモリ、通信、故障耐性、利用率、専用アクセラレータが一体で性能を決めます。
この論文は、そのことを非常に分かりやすく示している資料です。
関連技術
| 技術 | 関係 |
|---|---|
| TPU v1/v2/v3 | TPU v4以前の世代比較。推論特化から学習対応への流れを理解する前提になる |
| AllReduce | 分散学習で勾配を同期する通信。トポロジー設計の重要性に直結する |
| bfloat16 | TPUの学習で重要な低精度浮動小数点形式 |
| Sparse embedding | 推薦モデルや検索モデルで重要なID特徴量の表現 |
| GPUクラスタ | TPU v4と比較される大規模学習基盤 |
| NPU | エッジAI向けの専用推論アクセラレータ |
次に読むべき記事
| 記事案 | 理由 |
|---|---|
| TPUv1はなぜ推論特化だったのか?TPUv2/v3で学習対応が進んだ理由 | TPU v4の前提となるTPU世代差を理解できる |
| AllReduceとは何か | TPU v4のトポロジー設計がなぜ重要かを理解しやすくなる |
| GPUとNPUの違い | データセンター学習とエッジ推論の設計思想を比較できる |
| FlashAttentionとは何か | LLM学習で演算とメモリI/Oの関係を理解できる |
| Embeddingとは何か | SparseCoreがなぜ重要なのかを基礎から理解できる |

コメント