TransformerのSelf-Attentionは、系列長が長くなるほど、計算量だけでなくメモリアクセスも急増します。
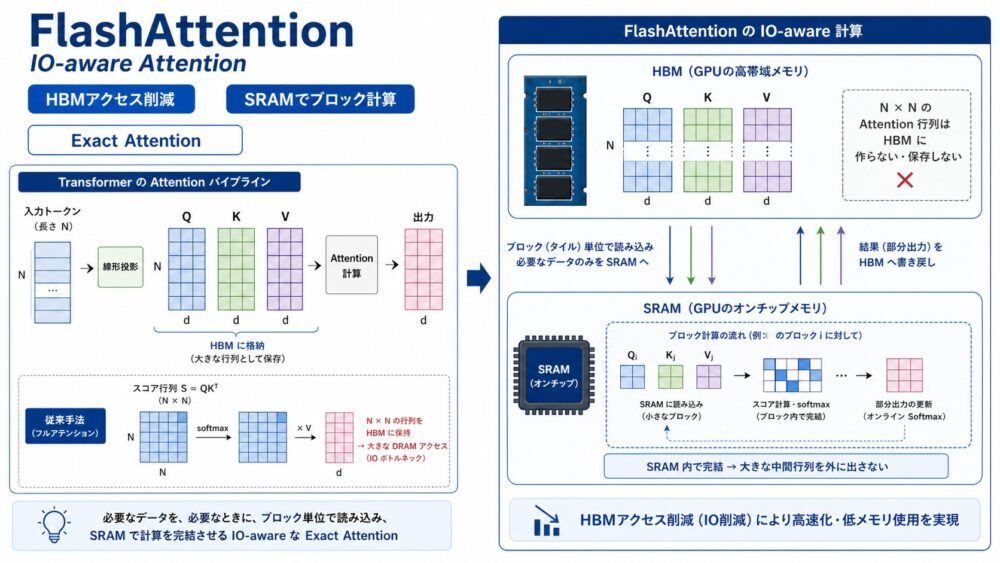
FlashAttentionは、Attentionの計算結果を近似せず、GPUのHBM(High Bandwidth Memory、高帯域メモリ)とSRAM(オンチップの高速小容量メモリ)の間の読み書きを減らすことで高速化する手法です。
論文では、標準Attentionで大きな \(N \times N\) 行列をHBMへ保存する設計を避け、tiling(行列を小さなブロックに分けて処理する手法)とrecomputation(逆伝播時に必要な値を再計算する手法)により、長いコンテキストのTransformer学習を高速・省メモリにできると示されています。
3文要約
FlashAttentionは、Self-Attentionを「数式上の計算量」だけでなく「GPUメモリ階層間のIO(データ読み書き)」から見直した論文です。
標準Attentionが \(N \times N\) のattention行列をHBMへ書き戻すのに対し、FlashAttentionはQ、K、Vをブロックに分けてSRAM上で計算し、softmaxの正規化統計だけを更新しながらexact attention(近似しないAttention)を得ます。
論文では、GPT-2のAttention計算で最大7.6倍、GPT-2学習で3倍、Long Range Arenaで2.4倍の高速化が報告され、長文脈Transformerを実用化する重要な基盤技術になりました。
論文情報

| 項目 | 内容 |
|---|---|
| 論文タイトル | FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness |
| 著者 | Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, Christopher Ré |
| 研究機関 | Stanford University, University at Buffalo, SUNY |
| 発表年 | 2022年 |
| arXiv提出 | 2022年5月27日、v2は2022年6月23日 |
| 論文リンク | FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness |
| arXiv PDF | |
| 公式実装 | Dao-AILab/flash-attention |
本記事では、論文の主張と筆者の解釈を分けて扱います。
論文で示されているのは、「Attentionの数式を変えずに、GPU上でのメモリアクセスを削減すると高速化できる」という点です。
そのため、FlashAttentionを単なる近似Attentionや、単なるCUDA実装テクニックとして理解すると、本質を見落としやすくなります。
本記事の目的
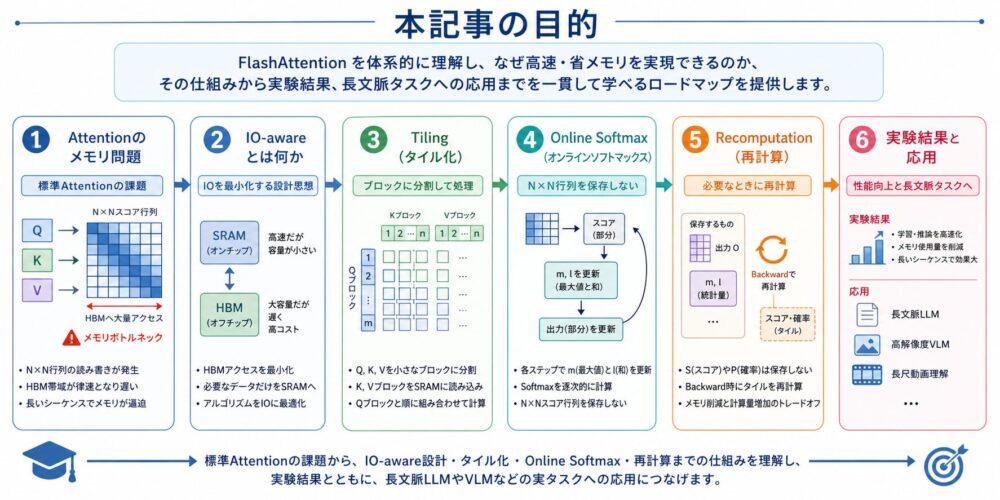
本記事では、FlashAttentionの新規性を次の順番で整理します。
- なぜ標準Self-Attentionは長い系列で遅く、メモリを使うのか
- FLOPs(浮動小数点演算回数)だけでは実行時間を説明できない理由
- FlashAttentionがHBMとSRAMのIOをどう減らすのか
- online softmax(分割した入力でもsoftmaxを正しく計算する方法)の数式
- recomputationにより、逆伝播時の \(N \times N\) 保存をどう避けるのか
- 実験結果、応用先、よくある誤解
対象読者は、TransformerのAttention式は見たことがあるが、GPUメモリ階層やCUDAカーネル最適化までは詳しくないAI初学者から中級者です。
背景:標準Self-Attentionはなぜ重いのか
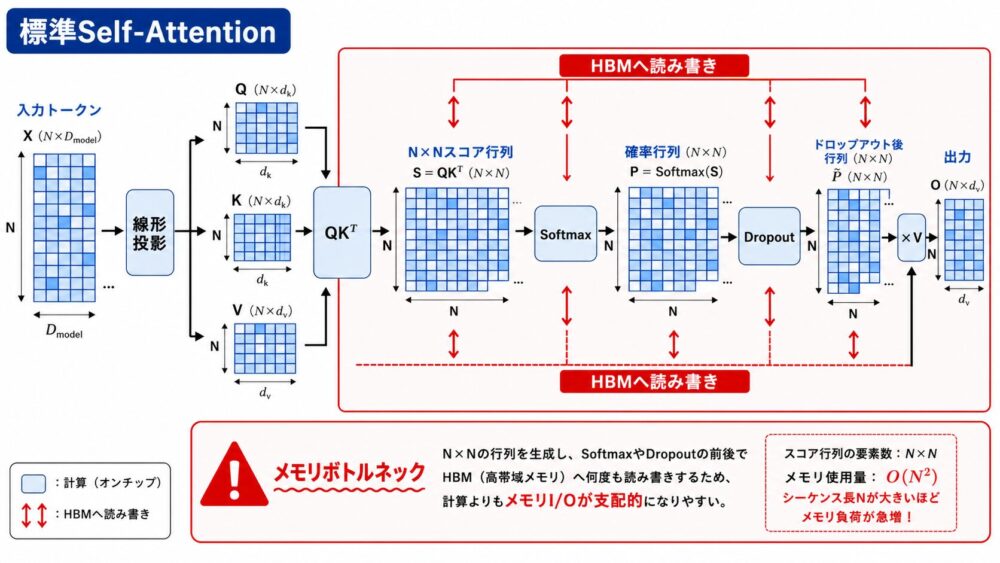
Self-Attentionでは、入力からQuery、Key、Valueを作り、次の式で出力を計算します。
\[
S = QK^{\mathrm{T}}
\]
\[
P = \mathrm{softmax}(S)
\]
\[
O = PV
\]
ここで、系列長を \(N\)、head dimension(1つのattention headが持つ特徴次元)を \(d\) とすると、\(Q,K,V \in \mathbb{R}^{N \times d}\) です。
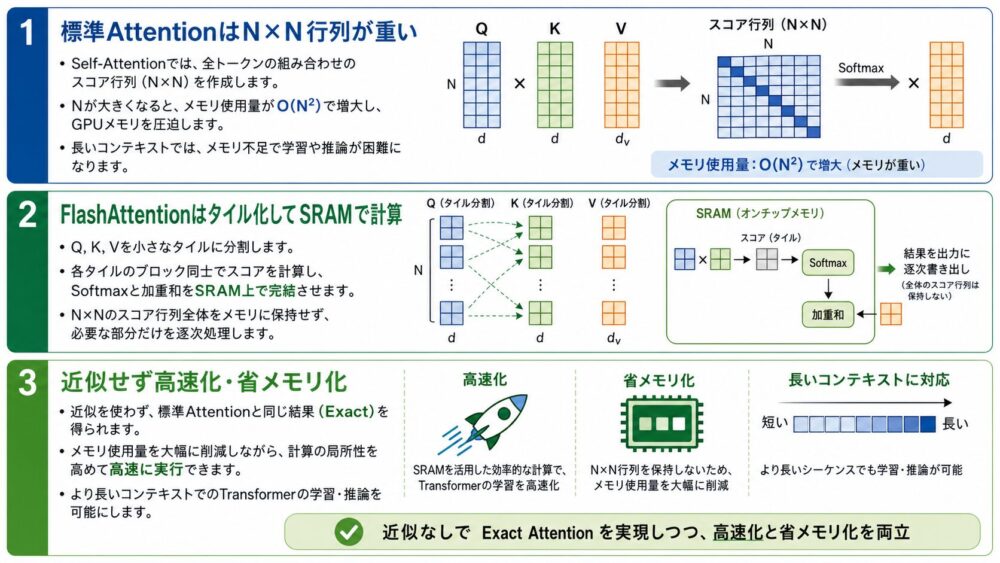
一方、\(S\) と \(P\) は \(N \times N\) の行列です。
系列長が2倍になると、\(S\) と \(P\) の要素数は4倍になります。
たとえば \(N=16,384\) の場合、\(N \times N\) は約2.68億要素です。
これは、単に計算が多いだけでなく、中間行列をHBMへ書き、次の演算でまた読むことが大きな負担になります。
| 段階 | 生成される主な値 | メモリ上の問題 |
|---|---|---|
| \(QK^{\mathrm{T}}\) | score行列 \(S \in \mathbb{R}^{N \times N}\) | 系列長の2乗で大きくなる |
| masking/dropout | mask済みscoreやdropout済み確率 | 中間値の読み書きが増える |
| softmax | attention確率 \(P \in \mathbb{R}^{N \times N}\) | 逆伝播のため保存されやすい |
| \(PV\) | 出力 \(O \in \mathbb{R}^{N \times d}\) | 出力自体は線形サイズだが、途中が重い |
従来の近似Attentionは、この \(N^2\) の負担を減らすために、疎構造、低ランク近似、局所Attentionなどを使います。
ただし、論文では、多くの近似AttentionはFLOPsを減らしても、実際のwall-clock time(実時間)では高速化しない場合があると指摘しています。
理由は、GPUでは演算器が速くなった一方で、HBMへの読み書きがボトルネックになりやすいからです。
論文解説:FlashAttentionの中核アイデア
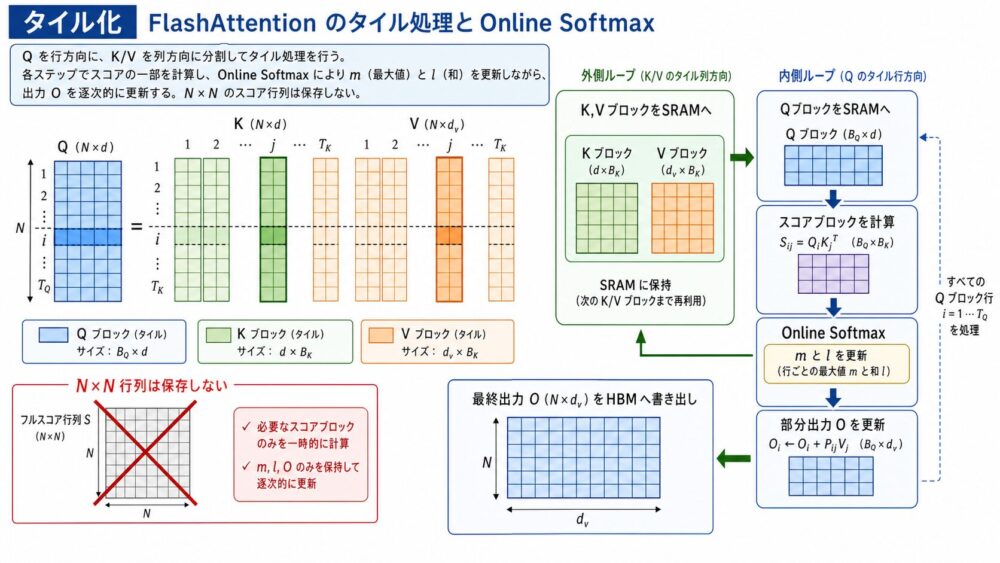
FlashAttentionの中核は、Attentionの数式を変えるのではなく、計算順序を変えることです。
標準Attentionでは、\(QK^{\mathrm{T}}\) 全体を作り、softmaxをかけ、\(V\) と掛けます。
FlashAttentionでは、\(Q,K,V\) をブロックに分割し、KとVのブロック、QのブロックをSRAMへ読み込み、ブロック単位でattention出力を足し合わせます。
このとき重要なのは、softmaxが行全体に依存することです。
単純に列方向を分割すると、各ブロックのsoftmaxを別々に計算して足すだけでは、全体のsoftmaxと一致しません。
FlashAttentionは、online softmaxにより、分割したブロックを処理しながら、行ごとの最大値と正規化項を更新します。
Online Softmax:分割してもsoftmaxを正しく計算する
softmaxを数値安定に計算するため、ベクトル \(x\) に対して最大値 \(m(x)\) を引きます。
\[
m(x) = \max_i x_i
\]
\[
f(x)_i = e^{x_i – m(x)}
\]
\[
\ell(x) = \sum_i f(x)_i
\]
\[
\mathrm{softmax}(x)_i = \frac{f(x)_i}{\ell(x)}
\]
ここで、\(x\) を2つのブロック \(x^{(1)}, x^{(2)}\) に分けたとします。
全体の最大値は次のように更新できます。
\[
m(x) =
\max
\left(
m(x^{(1)}),
m(x^{(2)})
\right)
\]
正規化項も、各ブロックの最大値との差を使って合わせられます。
\[
\ell(x)
=
e^{m(x^{(1)})-m(x)}\ell(x^{(1)})
+
e^{m(x^{(2)})-m(x)}\ell(x^{(2)})
\]
この式により、全列を一度に見なくても、各ブロックを処理しながらsoftmaxの分母を正しく更新できます。
FlashAttentionでは、各Qブロックについて、Kブロックを順に読み込み、scoreブロックを計算し、行ごとの \(m\) と \(\ell\)、出力 \(O\) を更新します。
結果として、\(N \times N\) のattention行列をHBMに保存しなくても、標準Attentionと同じ出力を得られます。
Tiling:HBMではなくSRAMでブロック計算する
tilingは、行列を小さなブロックに分割し、高速なSRAMへ載せて計算する手法です。
FlashAttentionでは、KとVのブロックを外側のループで読み込み、Qのブロックを内側のループで読み込みます。
各ブロックの計算はSRAM上で行い、最終的な出力だけをHBMへ書き戻します。
| 観点 | 標準Attention | FlashAttention |
|---|---|---|
| 中間attention行列 | \(N \times N\) をHBMに保存しやすい | 保存しない |
| softmax | 全score行列を作ってから処理 | ブロックごとに統計量を更新 |
| メモリアクセス | HBMへの読み書きが多い | SRAMで計算しHBM IOを削減 |
| Attentionの値 | exact | exact |
| 実装の要件 | 通常の高レベル演算で書きやすい | CUDAカーネルなど低レベル制御が重要 |
論文では、A100 GPUを例に、HBMは大容量だがSRAMより遅く、SRAMは非常に速いが小容量であると説明しています。
FlashAttentionは、この非対称なメモリ階層を前提に、読み書きの回数を減らす設計です。
Recomputation:逆伝播で何を保存し、何を再計算するか
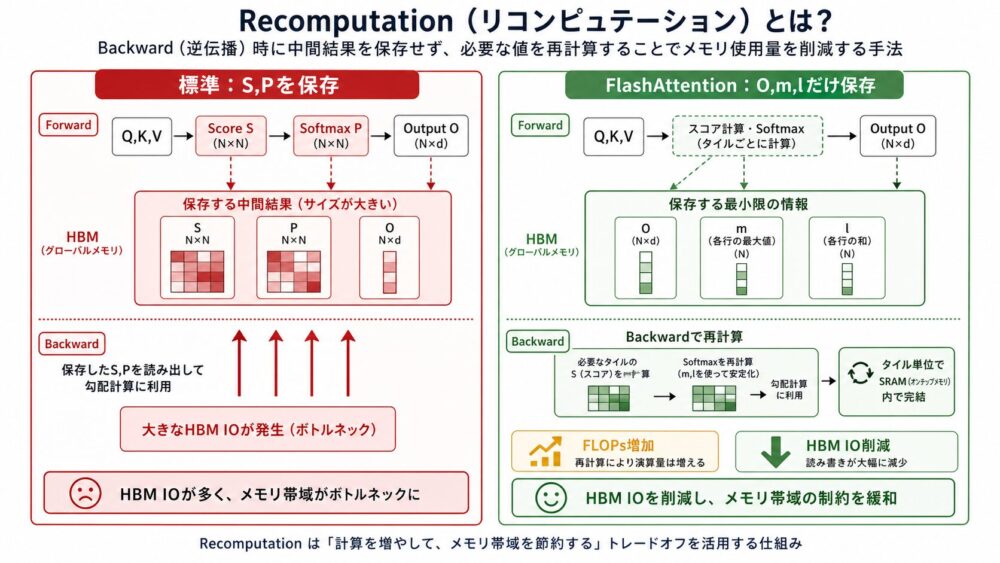
学習では、順伝播だけでなく逆伝播も必要です。
標準的な実装では、逆伝播のためにscore行列 \(S\) やattention確率 \(P\) を保存します。
しかし、これらは \(N \times N\) であり、長い系列ではメモリを大きく圧迫します。
FlashAttentionは、順伝播では出力 \(O\) とsoftmaxの正規化統計 \(m,\ell\) を保存します。
逆伝播では、Q、K、Vのブロックを再びSRAMへ読み込み、必要なscoreやsoftmax値をブロックごとに再計算します。
| 保存するもの | 標準Attention | FlashAttention |
|---|---|---|
| 出力 \(O\) | 保存 | 保存 |
| score \(S\) | 保存されやすい | 保存しない |
| attention確率 \(P\) | 保存されやすい | 保存しない |
| softmax統計 \(m,\ell\) | 通常は主役ではない | 保存して再計算に使う |
| 逆伝播時の方針 | 保存した大きな中間値を読む | 小さな統計からブロックを再計算 |
recomputationは、FLOPsを増やす可能性があります。
一見すると、再計算するなら遅くなりそうです。
しかし、論文では、HBM IOを減らせるため、総合的には逆伝播も高速化できると示しています。
ここがFlashAttentionの重要なポイントです。
FLOPsを少し増やしても、遅いメモリアクセスを大きく減らせるなら、実時間は短くなる場合があります。
IO複雑性:FLOPsではなくメモリアクセスを見る
FlashAttentionの論文は、IO complexity(メモリ階層間の読み書き回数の複雑性)を分析しています。
論文では、標準Attentionが少なくとも次のオーダーのHBMアクセスを必要とすると整理しています。
\[
\Omega(Nd + N^2)
\]
一方、FlashAttentionは、SRAMサイズを \(M\) とすると、次のオーダーでHBMアクセスを抑えられると分析しています。
\[
O(N^2 d^2 M^{-1})
\]
ここで、\(M\) が大きいほど、SRAMへ載せられるブロックが大きくなり、HBMへの往復を減らしやすくなります。
この式は、FlashAttentionが「Attentionの計算量 \(O(N^2d)\) を消す」手法ではないことを示しています。
むしろ、同じexact attentionを計算しながら、遅いメモリ階層へのアクセスを減らす手法です。
| 指標 | 見ているもの | FlashAttentionでの意味 |
|---|---|---|
| FLOPs | 演算回数 | recomputationにより増える場合がある |
| メモリ容量 | 保存すべきテンソル量 | \(N \times N\) attention行列を保存しないため削減 |
| HBM IO | HBMとの読み書き量 | 主な削減対象 |
| wall-clock time | 実際の実行時間 | GPUや実装、系列長に依存する |
FlashAttentionの意義は、理論上の演算量だけを見ると見えにくいボトルネックを、GPU実装の観点から正面に置いた点にあります。
Block-sparse FlashAttentionとの違い
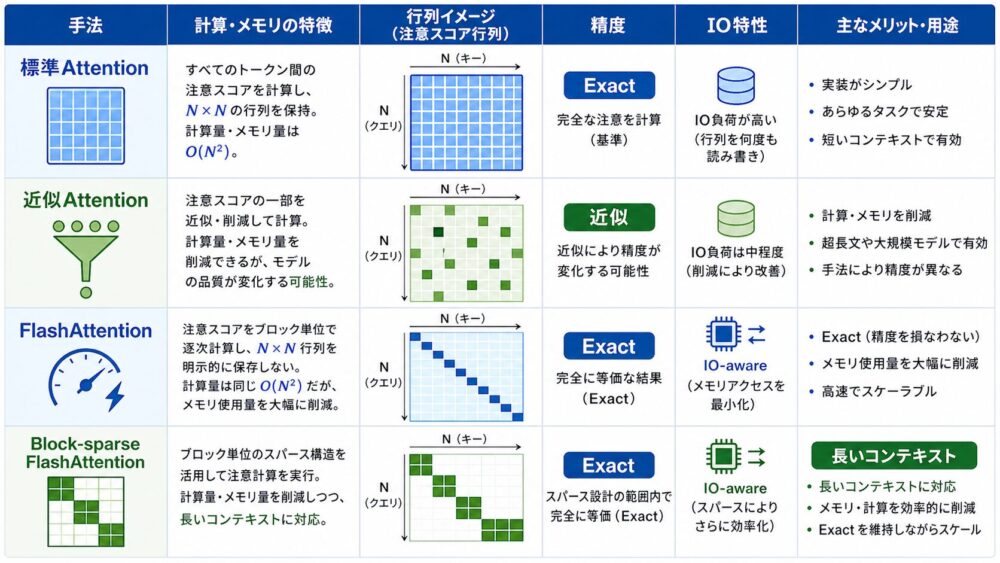
論文では、FlashAttentionをblock-sparse attention(ブロック単位で疎なAttentionを行う近似手法)へ拡張しています。
通常のFlashAttentionはexactです。
つまり、計算順序は変えますが、Attentionとして得られる値は標準Attentionと同じです。
一方、block-sparse FlashAttentionは、見るブロックを制限するため近似になります。
| 手法 | Attentionの値 | 主な狙い | 注意点 |
|---|---|---|---|
| 標準Attention | exact | 実装が単純で汎用的 | \(N \times N\) 中間行列が重い |
| 近似Attention | approximate | FLOPsやメモリを減らす | 品質低下や実時間高速化不足が起こり得る |
| FlashAttention | exact | HBM IOを減らす | GPUカーネル実装が重要 |
| Block-sparse FlashAttention | approximate | より長い系列へ拡張 | sparsity設計が品質に影響する |
この違いは重要です。
「FlashAttentionは近似Attentionだから速い」と説明すると誤りです。
通常のFlashAttentionは、標準Attentionと同じ結果を、よりIO効率のよい順序で計算する手法です。
実験結果:どの程度速くなったのか
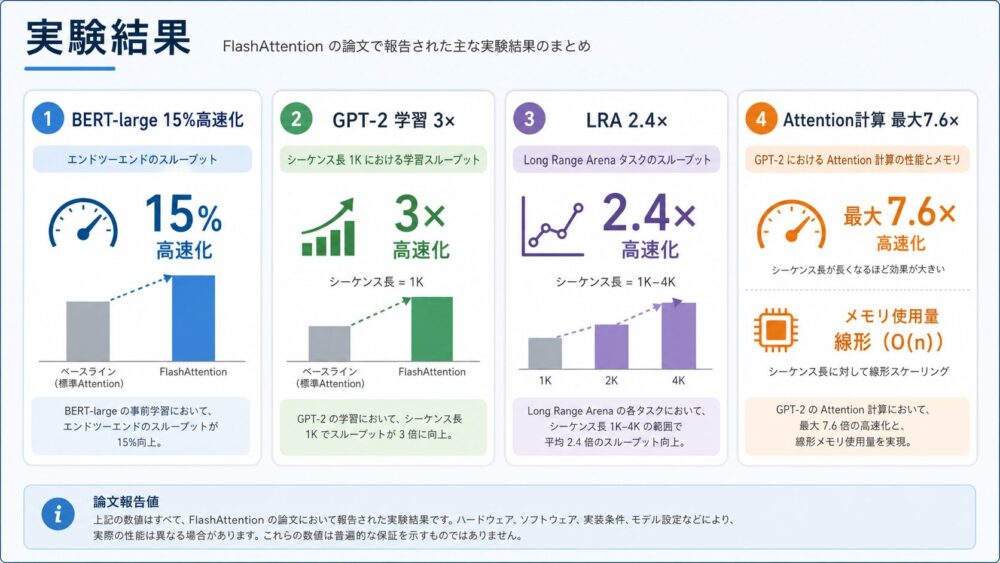
論文では、モデル学習、長文脈タスク、Attention単体のベンチマークでFlashAttentionを評価しています。
主な報告値を整理すると次の通りです。
| 評価 | 論文で報告された結果 | 読み方 |
|---|---|---|
| BERT-large, seq. length 512 | MLPerf 1.1の学習速度記録に対して15%のend-to-end高速化 | Attention単体ではなく学習全体の改善 |
| GPT-2, seq. length 1K | HuggingFace/Megatron-LM系ベースラインに対して3倍高速化 | 長い系列で効果が出やすい |
| Long Range Arena, seq. length 1K-4K | 2.4倍高速化 | 長文脈タスクでの学習時間改善 |
| GPT-2のAttention計算 | PyTorch実装に対して最大7.6倍高速化 | Attentionカーネル単体の改善 |
| GPT-2 perplexity | 長い文脈により0.7改善 | 高速化により長文脈を扱いやすくなる |
| Path-X | FlashAttentionで61.4% accuracy | 16K系列への拡張例 |
| Path-256 | Block-sparse FlashAttentionで63.1% accuracy | 64K系列への拡張例 |
これらは論文の実験条件での報告値です。
すべてのモデル、GPU、sequence lengthで同じ倍率が出るわけではありません。
ただし、長い系列でAttentionの中間行列が支配的になるほど、FlashAttentionのIO削減は効きやすくなります。
高画質タスクへの応用:画像、動画、VLMで何が嬉しいか
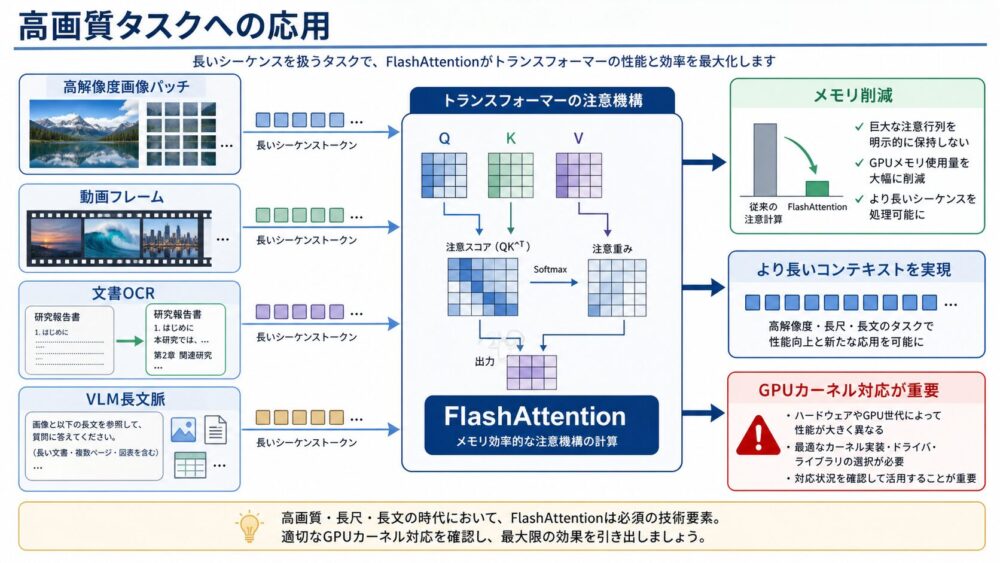
FlashAttentionは、LLMだけでなく、画像・動画・VLM(Vision-Language Model、画像と言語を同時に扱うモデル)でも重要です。
画像をパッチに分けてTransformerへ入力するVision Transformerでは、高解像度になるほどtoken数が増えます。
動画では、空間方向のパッチに加えて時間方向のフレームも増えるため、系列長はさらに大きくなります。
| 応用先 | Attentionが重くなる理由 | FlashAttentionで期待できること |
|---|---|---|
| 高解像度画像認識 | パッチ数が増える | より大きな入力解像度を扱いやすくなる |
| 画像生成 | latentやパッチ系列が長くなる | DiT系モデルのAttentionメモリを抑えやすい |
| 動画理解・動画生成 | フレーム数と空間パッチが同時に増える | 長い時間文脈を扱いやすくなる |
| 文書OCR・レイアウト理解 | 画像パッチと文字tokenが増える | 長文書の文脈統合に向く |
| VLM | 画像tokenと言語tokenを同時に扱う | 長いマルチモーダル文脈に向く |
カメラ向けの高画質化タスクで考えると、Denoise(ノイズ除去)、Demosaic(カラーフィルタ配列からRGB画像を復元する処理)、Super Resolution(超解像)などは、高解像度画像を扱うためメモリ負担が大きくなりやすいです。
Transformer型の画像復元モデルへFlashAttentionを組み込めれば、より大きな画像パッチ数や広い文脈を扱いやすくなる可能性があります。
一方で、組み込み機器やエッジデバイスでは、GPUの種類、SRAM容量、対応カーネル、電力制約が大きく効きます。
FlashAttentionは「考え方」としては有用ですが、実際に高速化できるかは、対象ハードウェアで同等のメモリ階層制御ができるかに依存します。
実装者視点で気をつけること
FlashAttentionを使うときは、単にライブラリ名を有効にするだけでなく、前提条件を確認する必要があります。
| 確認項目 | なぜ重要か |
|---|---|
| GPUアーキテクチャ | 対応カーネルや最適化度が変わる |
| head dimension | カーネルが対応する形状でないと速くならない場合がある |
| sequence length | 短い系列では通常実装との差が小さい場合がある |
| dropout/mask | causal maskやpadding mask対応で実装経路が変わる |
| dtype | fp16、bf16、fp8などで対応状況が異なる |
| training/inference | 逆伝播があるかでrecomputationの意味が変わる |
FlashAttentionは、Attention式を理解するだけではなく、GPUカーネル、メモリ階層、テンソル形状まで含めて効果が決まります。
LLMや画像生成モデルの高速化で使う場合も、ベンチマークは対象モデル・対象GPU・対象batch sizeで測る必要があります。
よくある誤解

| よくある誤解 | 正確な情報・解釈 |
|---|---|
| FlashAttentionは近似Attentionである | 通常のFlashAttentionはexact attentionです。計算順序を変えているだけです |
| FlashAttentionはFLOPsを減らす手法である | 主役はHBM IO削減です。recomputationによりFLOPsは増える場合もあります |
| \(N^2\) の問題が完全になくなる | attentionの計算構造自体は \(N^2\) の側面を残します。主に保存メモリとIOを減らします |
| どんなモデルでも必ず速い | sequence length、GPU、head dimension、実装経路に依存します |
| CUDAの小技にすぎない | online softmax、tiling、IO complexity解析を含むアルゴリズムと実装の共同設計です |
| Block-sparse FlashAttentionもexactである | block-sparse版は見るブロックを制限するため近似です |
特に重要なのは、FlashAttentionが「近似しないまま高速化する」点です。
多くのAttention高速化手法は、計算対象を減らすことで高速化します。
FlashAttentionは、計算対象そのものを削るのではなく、同じ計算をGPUにとって効率のよい順序で実行します。
まとめ
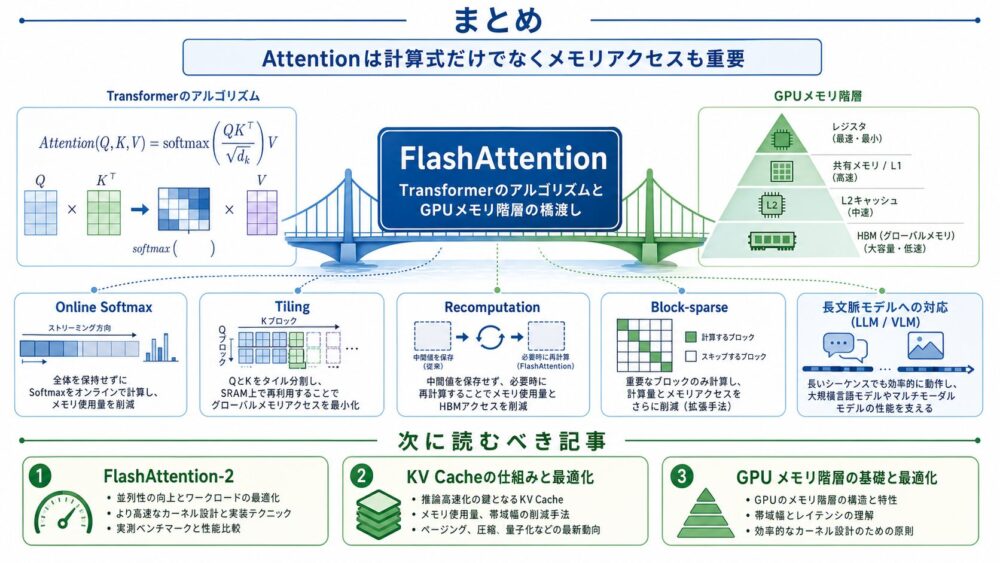
FlashAttentionは、TransformerのAttentionを、FLOPsだけでなくGPUメモリ階層のIOから見直した論文です。
標準Attentionでは \(N \times N\) のscore行列やattention確率をHBMへ保存しやすく、長い系列でメモリと読み書きが支配的になります。
FlashAttentionは、tiling、online softmax、recomputationを組み合わせ、\(N \times N\) attention行列を保存せずにexact attentionを計算します。
論文では、BERT-large、GPT-2、Long Range Arena、Path-X/Path-256などで、長文脈Transformerの高速化とメモリ削減が報告されています。
ただし、FlashAttentionは魔法の高速化ではありません。
効果はGPU、系列長、head dimension、dtype、mask、実装カーネルに依存します。
それでも、現在のLLM、画像生成、VLMで長いコンテキストを扱ううえで、「Attentionは数式だけでなくメモリアクセスが重要」という視点を広めた点で、非常に重要な論文です。
関連技術
| 関連技術 | FlashAttentionとの関係 |
|---|---|
| Transformer | Self-Attentionを中核に持つモデル構造 |
| Self-Attention | FlashAttentionが高速化する対象 |
| CUDA kernel fusion | 複数演算を1つのGPUカーネルにまとめ、メモリ読み書きを減らす実装技術 |
| Gradient checkpointing | 中間値を保存せず再計算する考え方。FlashAttentionのrecomputation理解に近い |
| Sparse Attention | attention対象を疎にする近似手法。block-sparse FlashAttentionと関係する |
| FlashAttention-2 | FlashAttentionの後続研究で、並列化とワーク分割を改善する |
| KV Cache | 推論時の過去Key/Value保存。FlashAttentionとは別軸だが長文脈LLMで併用される |
次に読むべき記事
| 記事案 | 狙い | 優先度 |
|---|---|---|
| Self-Attentionとは?Transformerを支える仕組みを数式で解説 | FlashAttentionの前提を理解する | 高 |
| GPUメモリ階層とは?HBM、SRAM、レジスタの違いを整理 | IO-awareの背景を理解する | 高 |
| FlashAttention-2とは?並列化とワーク分割の改善を解説 | FlashAttentionの発展を追う | 高 |
| KV Cacheとは?LLM推論のメモリ使用量を理解する | 長文脈推論の別ボトルネックを理解する | 高 |
| Sparse Attentionとは?長文脈Transformerの近似手法を比較 | block-sparse版との違いを理解する | 中 |
コメント