ニューラルネットワークの多くの計算は、行列積として実行されます。
GPUはこの行列積を、巨大な行列のまま一度に処理するのではなく、小さなtile(部分行列)へ分割して処理します。
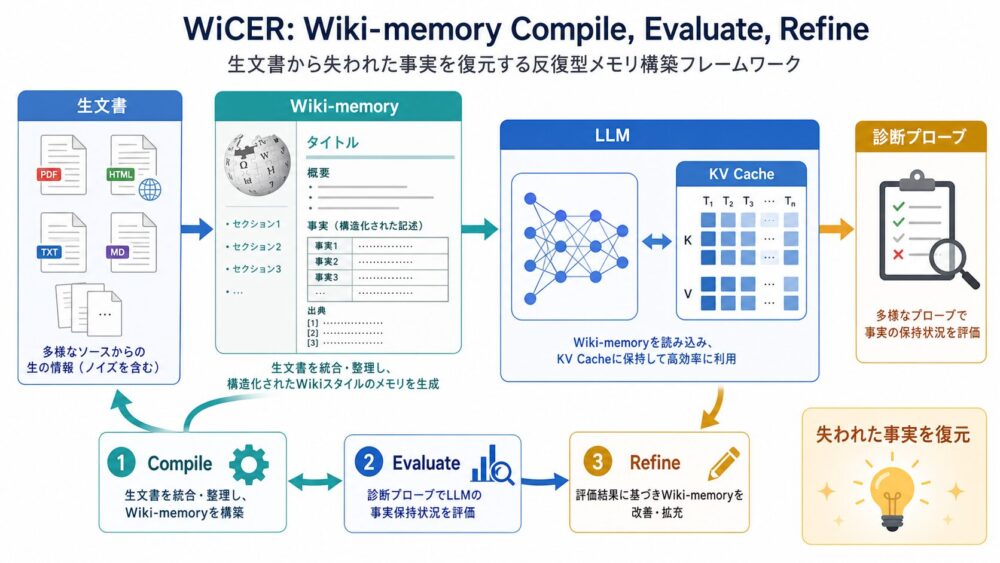
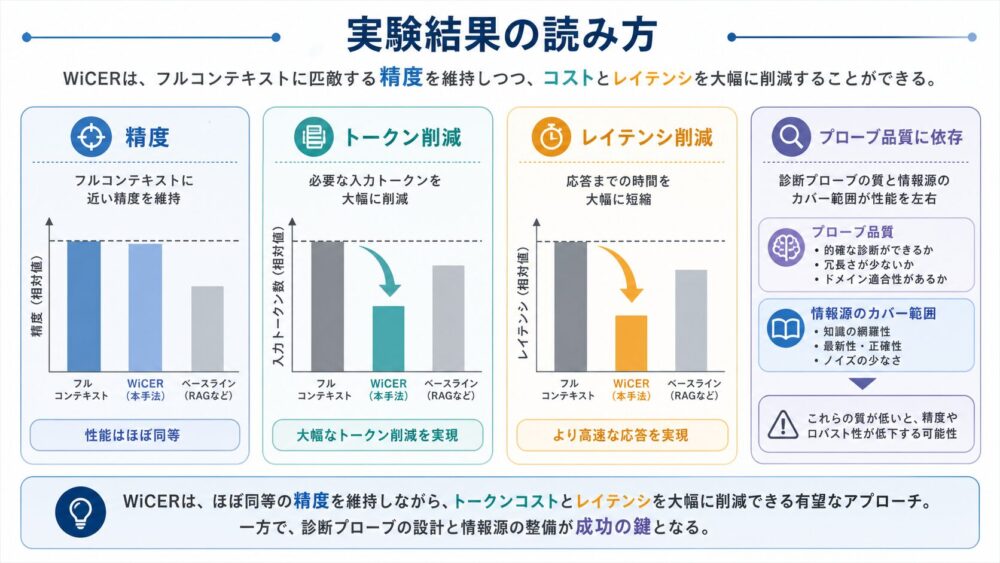
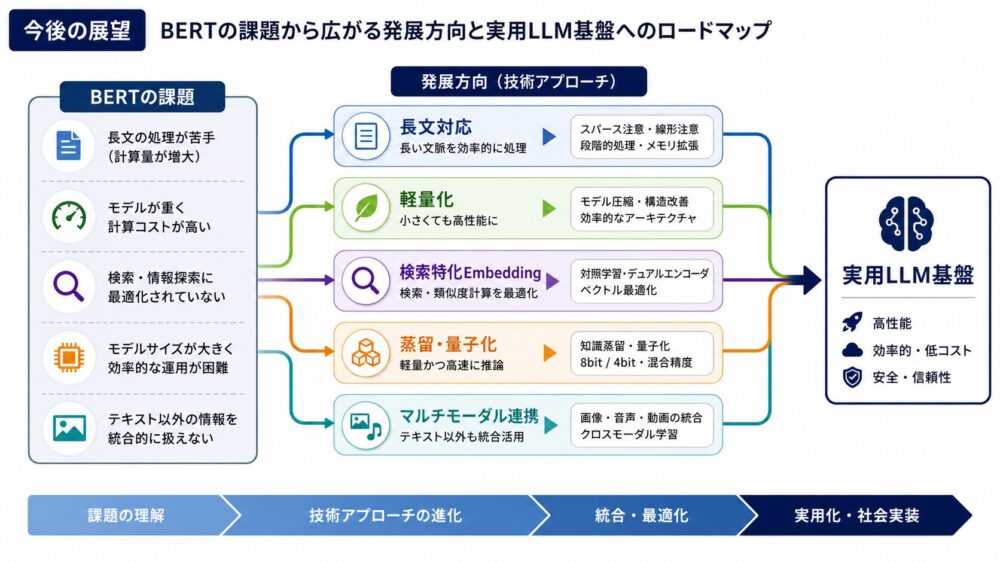
本記事では、thread、warp、SM、Shared Memory、Registers、Tensor Coreの関係から、GPUがなぜtile化でデータ再利用を制御するのかを整理します。
本記事の目的
本記事の目的は、GPUの行列積を「演算器がたくさんあるから速い」という説明だけで終わらせず、データ移動と再利用の観点から理解することです。
深層学習では、畳み込み、MLP、attention(入力間の関係を重み付けして集約する処理)など、多くの処理がGEMM(General Matrix Multiplication、汎用行列積)として実行されます。
しかし、演算器が多くても、A行列とB行列を遠いHBM/GDDRから毎回読み続けると、演算器へデータを供給できません。
GPUとNPUの違いも、演算器の数だけでは説明できません。
GPUは、SM(Streaming Multiprocessor、GPU内の実行資源)ごとにShared Memory(同じthread blockが共有するオンチップメモリ)とRegisters(threadごとの近接保存領域)を使い、tile化したA/Bを近い場所へ置いて再利用します。
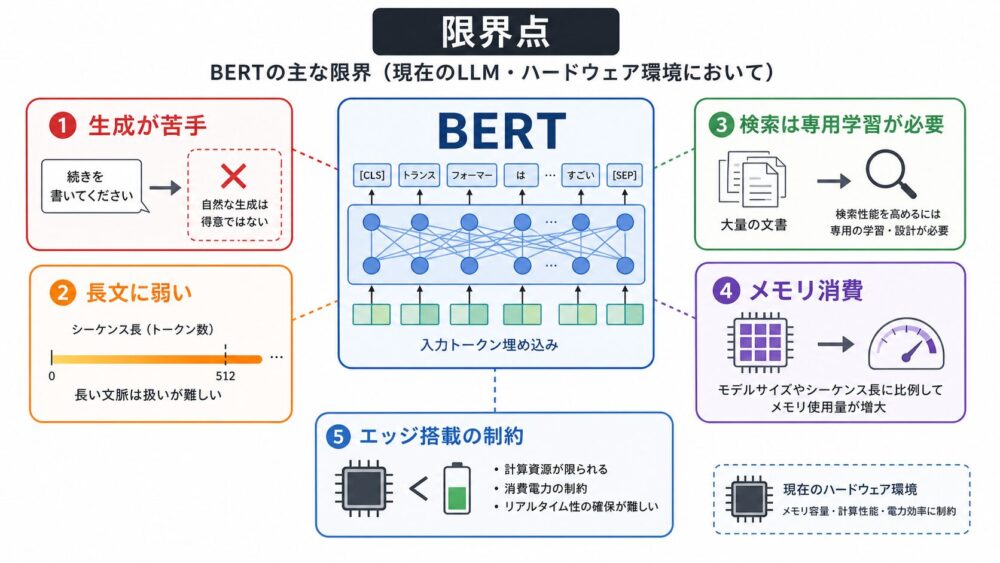
後編では、NPU(Neural Processing Unit、ニューラルネットワーク向け演算器)のPE Array(Processing Elementの配列)、Systolic Array(データを隣接演算器へ流す配列構造)、On-chip SRAM(チップ上の高速メモリ)、データフローを扱います。
3文要約
GPUは、巨大な行列積を小さなtileへ分割し、A tileとB tileをShared MemoryやRegistersへ置いて複数の積和へ再利用します。
Registerは演算器ではなく、Tensor CoreやCUDA Coreへ渡す値、またはC tileの部分和を保持する近接保存領域です。
Tensor Coreへ継続的にデータを供給するには、HBM/GDDR、L2 Cache、Shared Memory、Registersをまたぐtile化とデータ移動の設計が重要になります。
論文・一次資料情報
この記事は単一論文の要約ではなく、CUDAの実行モデル、Tensor Core、GPUメモリ階層を複数の一次資料から統合して説明します。
NVIDIA公式資料は公式アーキテクチャ資料・公式プログラミングガイドとして扱い、査読論文とは区別します。
| 種別 | タイトル | 著者・組織 | 年 | この記事で参照する内容 | リンク |
|---|---|---|---|---|---|
| 技術論文 | Scalable Parallel Programming with CUDA | John Nickolls, Ian Buck, Michael Garland, Kevin Skadron | 2008 | CUDAのthread block、shared memory、warp、SIMTの基本概念 | Scalable Parallel Programming with CUDA |
| 論文 | NVIDIA Tensor Core Programmability, Performance & Precision | Stefano Markidis, Steven Wei Der Chien, Erwin Laure, Ivy Bo Peng, Jeffrey S. Vetter | 2018 | Volta世代Tensor Core、WMMA、CUTLASS、cuBLAS、MMAの位置づけ | NVIDIA Tensor Core Programmability, Performance & Precision |
| 公式ガイド | CUDA Programming Guide | NVIDIA | 2026年版 | CUDAプログラミングモデル、thread hierarchy、warp、memory model | CUDA Programming Guide |
| 公式ガイド | CUDA C++ Best Practices Guide | NVIDIA | 2026年版 | Shared Memoryを使った行列積、L2 Cache、Registers、occupancy | CUDA C++ Best Practices Guide |
| 公式チューニング資料 | Hopper Tuning Guide | NVIDIA | 2026年版 | Hopper世代のSM、occupancy、Tensor Core、TMAのチューニング観点 | Hopper Tuning Guide |
| 公式アーキテクチャ解説 | NVIDIA Hopper Architecture In-Depth | NVIDIA | 2022 | H100のSM数、L2容量、HBM、Tensor Core、Shared Memory/L1の容量例 | NVIDIA Hopper Architecture In-Depth |
本記事で容量例を出す場合は、主にH100 SXM5またはHopper世代の例として書きます。
たとえばNVIDIAのHopper解説では、H100 SXM5は132 SM、80GB HBM3、50MB L2 Cache、SMあたり256KBのcombined shared memory and L1 data cacheを持つ例として説明されています。
これはH100/Hopper世代の具体例であり、すべてのGPUに共通する固定値ではありません。
GPUの行列積とは:積和から理解する
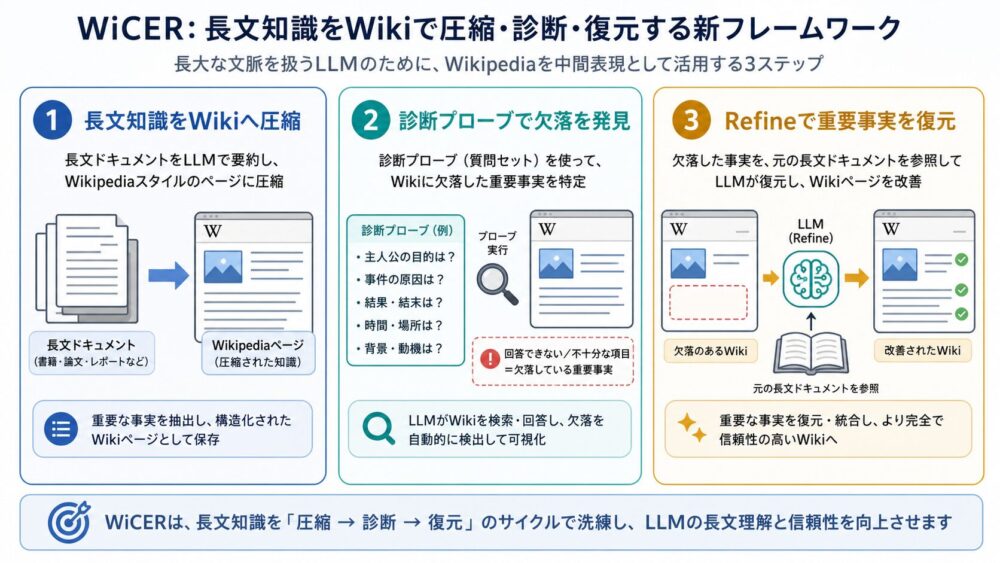
ニューラルネットワークでよく出てくる行列積は、次の形で表されます。
\[ C = A \times B \]
ここで、Aは入力またはactivation(ニューラルネットワークの中間特徴)、Bはweight(学習済み重み)、Cは出力または部分和です。
各出力要素は、Aの行とBの列の積和で作られます。
\[ C_{i,j} = \sum_k A_{i,k}B_{k,j} \]
3×3の例で、\( C_{1,1} \) だけを見ると次のようになります。
\[ C_{1,1} = A_{1,1}B_{1,1} + A_{1,2}B_{2,1} + A_{1,3}B_{3,1} \]
MACはMultiply-Accumulate(乗算加算)の略で、\( A_{i,k}B_{k,j} \) を計算し、その結果をCの部分和へ足し込む処理です。
行列積で重要なのは、同じA/B要素が複数のC要素に関係することです。
たとえばAの同じ行要素は、Bの複数列と組み合わされ、複数のC要素に使われます。
Bの同じ列要素も、Aの複数行と組み合わされます。
そのため、行列積の性能は演算器のピーク性能だけでは決まりません。
A/Bをどこから読み、どれだけ近い場所に置き、何回再利用できるかが重要になります。
GPUの実行単位:thread、warp、thread block、SM

GPUの行列積を理解するには、まず実行単位の階層を分けて見る必要があります。
| 用語 | 初学者向けの比喩 | 技術的な説明 |
|---|---|---|
| thread | 小さな作業員 | データの一部を担当する論理実行単位 |
| warp | 32人の作業班 | NVIDIA GPUで基本的に同じ命令をまとめて実行するthread群 |
| thread block | 複数warpのチーム | Shared Memoryを共有する実行単位 |
| SM | 作業場 | warp、Register file、Shared Memory、演算器を持つ実行資源 |
| Warp Scheduler | 班を切り替える司令塔 | 実行可能なwarpを選び、レイテンシを隠蔽する回路 |
| Tensor Core | 行列積専用加工機 | 行列積和を高速に実行する演算器 |
| CUDA Core | 汎用加工機 | スカラー演算やFMA(Fused Multiply-Add、乗算加算命令)などを実行する演算器 |
| Register | 作業員の手元 | threadごとに割り当てられる近接保存領域 |
NVIDIA GPUにおいて、warpは通常32 threadsです。
ただし、threadやwarpはCPUのOSスレッドと同一ではありません。
CUDAのthreadは、カーネル内で同じプログラムを多数のデータに適用するための論理的な実行単位です。
thread blockは複数のthreadをまとめた単位で、同じblock内のthreadはShared Memoryを使って協調できます。
SMは、そのthread blockやwarpを実際に実行するGPU内の資源です。
SMの中には、Warp Scheduler、Register file、Shared Memory、CUDA Core、Tensor Coreなどがあります。
ここで特に誤解しやすいのがRegisterです。
Registerは演算器ではありません。
Registerは、Tensor CoreまたはCUDA Coreへ渡す値、A/Bの断片、Cの部分和などを保持する保存領域です。
実際のMACやMMA(Matrix Multiply-Accumulate、行列積和)は、Tensor CoreまたはCUDA Coreなどの演算器が実行します。
Tensor CoreとCUDA Coreも同じものではありません。
Tensor Coreは行列積和に特化した演算器で、CUDA Coreはより汎用的なスカラー演算や通常のFMAなどを担当します。
GPUのメモリ階層:HBM/GDDR、L2、Shared Memory、Registers
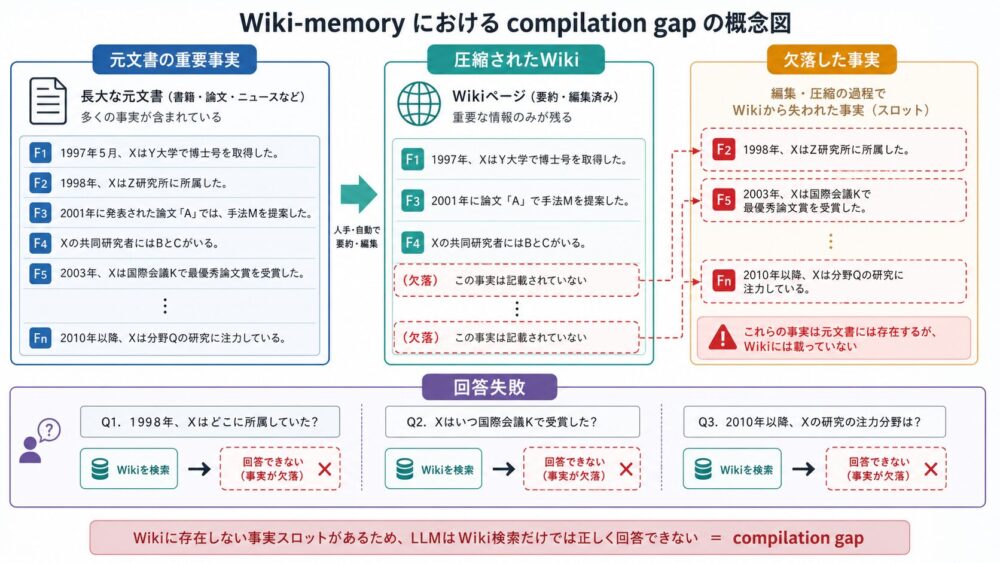
GPUの行列積では、演算器そのものだけでなく、メモリ階層が重要です。
概念的には、次のような距離関係で考えると理解しやすくなります。
\[ \mathrm{HBM/GDDR} \rightarrow \mathrm{L2\ Cache} \rightarrow \mathrm{Shared\ Memory} \rightarrow \mathrm{Registers} \rightarrow \mathrm{Tensor\ Core / CUDA\ Core} \]
| 階層 | 役割 | 共有範囲 | 容量感 | 注意点 |
|---|---|---|---|---|
| HBM/GDDR | GPU外部またはパッケージ近傍の大容量メモリ | GPU全体 | 大きい | SMから見ると遠く、アクセスコストが高い |
| L2 Cache | global memoryアクセスを緩和するキャッシュ | GPU全体 | HBM/GDDRより小さい | 世代ごとに容量と挙動が異なる |
| Shared Memory | block内の協調的なデータ再利用 | SM内のthread block | L2より小さい | 明示的に使うscratchpadとして設計できる |
| Registers | threadごとの値と部分和の保持 | threadごと | 小さい | 使用量が多いとoccupancyに影響し得る |
| Tensor Core / CUDA Core | 実際の演算 | SM内 | 保存領域ではない | 入力が継続供給されないと性能を出しにくい |
一般に、容量は HBM/GDDR > L2 Cache > Shared Memory > Registers の順に小さくなり、演算器に近づくほど容量は小さく、アクセスは速くなります。
ただし、容量、帯域、レイテンシはGPU世代により異なります。
H100 SXM5の例では、HBM3が80GB、L2 Cacheが50MB、SMあたりcombined shared memory and L1 data cacheが256KBです。
これはHopper世代のH100 SXM5に関する例であり、他世代やコンシューマGPUへそのまま一般化してはいけません。
Register使用量、Shared Memory使用量、thread blockサイズは、occupancy(SM上に同時滞在できるwarpやblockの多さ)に影響し得ます。
CUDA Best Practices Guideでも、register fileはSM内の有限資源であり、register使用量が多いkernelではoccupancyが下がる場合があると説明されています。
重要なのは、GPUにもL2 Cacheが存在することです。
GPUは「キャッシュがないからtile化する」のではありません。
L2 Cacheが存在しても、行列積ではA/Bの再利用パターンが明確なため、Shared MemoryとRegistersを使って再利用を明示的に制御する価値があります。
GPUはなぜ行列積をtileへ分割するのか
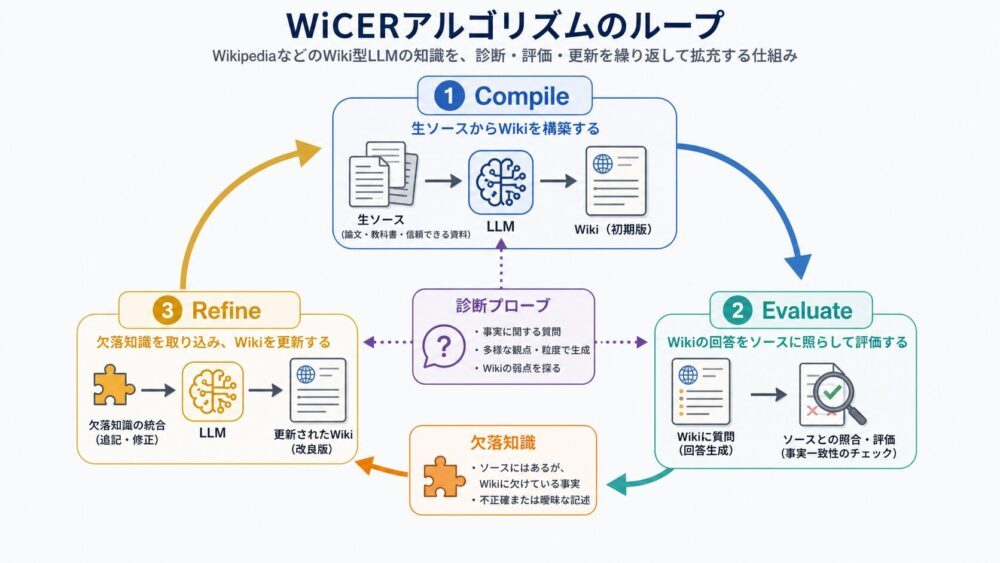
GPUが行列積をtileへ分割する理由は、行列全体がRegistersやShared Memoryに入らないからです。
たとえば巨大なactivation行列Aとweight行列Bを、そのままSM内へ置くことはできません。
そのため、GPUはCの一部であるC tileを決め、そのC tileを作るために必要なA tileとB tileを順に持ち込みます。
流れは次のように整理できます。
- 行列全体はRegistersやShared Memoryに入らない
- A/Bを小さなtileへ分割する
- A tileとB tileをShared Memoryへ置く
- warp内のthreadが必要な断片をRegistersへ持つ
- Tensor CoreまたはCUDA Coreが積和を実行する
- C tileの部分和をRegister近傍に保持する
- K方向に次のA/B tileをロードし、同じC tileへ積和を続ける
- C tileが完成した後、HBM/GDDRへ書き戻す
ここでいうK方向とは、次の式の総和を取る軸です。
\[ C_{i,j} = \sum_k A_{i,k}B_{k,j} \]
C tileを完成させるには、K方向に並ぶ複数のA/B tileを順番に掛け合わせ、同じC tileの部分和へ足し込む必要があります。
このとき、A tileとB tileは一度Shared MemoryやRegistersへ置かれると、複数のC要素の計算に使われます。
遠いHBM/GDDRから読み込んだデータを、近いメモリ階層で複数回使うことで、遠いメモリアクセスのコストを償却します。
| よくある誤解 | 正確な情報・解釈 |
|---|---|
| GPUはキャッシュが無いからtile処理する | GPUにもL2などのキャッシュはある。tile処理は、行列積に必要な再利用をより明示的に制御するために行う |
| Registerが積和を実行する | Registerは保存領域であり、積和はTensor CoreまたはCUDA Coreが実行する |
| GPUは毎回DRAMから無駄にデータを読む | 実際にはcache、Shared Memory、Registersで再利用する。ただし巨大行列ではtile入れ替えが必要になる |
| GPUは再利用しない | GPUもtileを近いメモリに置いて再利用する |
| Tensor Coreだけ見れば性能が分かる | Tensor Coreへデータを供給するShared Memory、Registers、レイアウト、同期、occupancyも性能に影響する |
NickollsらのCUDA論文でも、shared memoryは低レイテンシのオンチップメモリとして、thread block内のデータ共有と再利用に使えることが説明されています。
CUDA Best Practices Guideでも、行列積におけるShared Memoryの利用は、global memoryから読んだデータをblock内で再利用する代表例として扱われています。
つまり、tile化は単なる分割ではありません。
演算器の近くにA/Bを置き、複数のMAC/MMAへ使い回すためのデータ移動設計です。
Tensor CoreとMMA:積和をどこで実行するのか
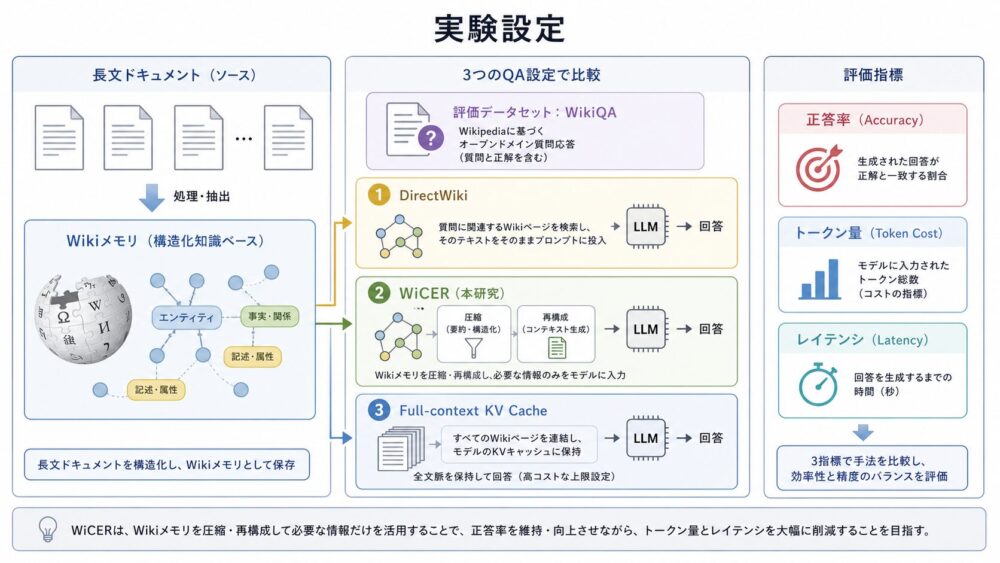
Tensor Coreは、行列積和を高速に実行する演算器です。
MMAはMatrix Multiply-Accumulateの略で、概念的には次の計算を表します。
\[ D = A \times B + C \]
ここでA/Bは入力断片、Cは累積済みの部分和、Dは更新後の出力断片です。
warp内のthreadは、A/B/Cの断片を分担して保持します。
Registersには、Tensor Coreへ渡す断片や部分和が置かれます。
しかし、Registerが積和を実行するわけではありません。
Tensor CoreがMMAを実行し、その結果が再びRegister近傍の累積値として扱われます。
Markidisらの2018年論文は、Volta世代のTensor Coreを対象に、WMMA(Warp Matrix Multiply-Accumulate、warp単位でMMAを扱うCUDA API)、CUTLASS、cuBLAS GEMMからTensor Coreを利用する方法を比較しています。
この論文ではVolta世代のTensor Coreについて、4×4行列に対するMMAを単位として説明しています。
ただし、これはVolta世代の説明です。
Tensor Coreの入力精度、累積精度、tile形状、命令形式は、GPU世代、データ型、命令セットに依存します。
Hopper世代では、FP8、FP16、BF16、TF32、FP64、INT8などのMMAデータ型が公式解説で紹介されています。
そのため、「Tensor Coreは常に4×4を計算する」のように一般化してはいけません。
Tensor Coreは、データが継続的に供給されなければ性能を発揮しにくい演算器です。
そのため、Shared Memory、Registers、tile化、メモリレイアウト、warp単位のデータ分担が重要になります。
大きい行列では、なぜtileの入れ替えを繰り返すのか
大きい行列では、C tileを一度決めても、それだけで計算は終わりません。
C tileを完成させるには、K方向の複数A/B tileを順に積和する必要があります。
概念的には次の更新を繰り返します。
\[ C_{\mathrm{tile}} \mathrel{+}= A_{\mathrm{tile},k} \times B_{\mathrm{tile},k} \]
行列全体をSM内に保持できないため、A/B tileはDRAM/HBMから順次ロードされます。
ただし、ロードしたtileをすぐに1回だけ使って捨てるわけではありません。
Shared MemoryとRegistersへ置いたtileは、複数の積和に使ってから入れ替えます。
重要なのは、DRAM/HBMから読み込んだデータを複数の演算に使い、遠いメモリアクセスを償却することです。
GPUは、HBM/GDDR、L2 Cache、Shared Memory、Registersというメモリ階層を通じて、Tensor CoreやCUDA Coreへデータを供給する方式です。
この見方をすると、GPUのtile化は「行列を小さく切るテクニック」ではなく、「近い場所で再利用して演算器を止めないためのデータ供給戦略」と言えます。
カメラAI・画像処理への応用
カメラAIや画像処理でも、GPUのtile化とデータ再利用は重要です。
DLNR(Deep Learning Noise Reduction、深層学習ノイズ除去)、Demosaic(ベイヤー配列などからRGB画像を復元する処理)、Super Resolution(超解像)、Transformer系画像処理では、畳み込みやattentionが内部的に行列積へ変換されることがあります。
畳み込みは、im2colのような変換やライブラリ内部の実装によりGEMMとして扱われる場合があります。
attentionでは、Query、Key、Valueの線形変換や \( QK^{\mathrm{T}} \)、attention重みとValueの積が大きな行列演算になります。
高ISOノイズ除去や高解像度化では、feature map(特徴マップ)やactivationが大きくなり、メモリ帯域が課題になりやすくなります。
GPU上で高速化するには、演算器のピーク性能だけでなく、A/Bに相当するactivationやweightをどう近い場所へ持ち込み、どう再利用するかが効いてきます。
実機搭載では、GPUだけでなく、ISP(Image Signal Processor、画像信号処理専用回路)、DSP(Digital Signal Processor、信号処理向けプロセッサ)、NPU、CPUとの役割分担が必要になる場合があります。
実際の性能は、モデル形状、精度、batch、入力サイズ、メモリ帯域、ライブラリ実装、データレイアウトに依存します。
そのため「Tensor Coreがあるから必ず速い」「NPUだから必ず省電力」といった単純な断定は避けるべきです。
まとめ
GPUは、SMの中でwarpがShared MemoryとRegistersを使い、A/BのtileをTensor Core近傍へ運んで再利用します。
行列全体が近いメモリに入らないため、K方向のtile入れ替えは必要です。
ただし、遠いHBM/GDDRから読み込んだA/B tileを複数の積和へ使うことで、データ移動のコストを償却しています。
Registerは積和を実行する場所ではなく、Tensor CoreやCUDA Coreへ渡す値と部分和を保持する場所です。
実際のMAC/MMAは、Tensor CoreまたはCUDA Coreが実行します。
GPUにもL2 Cacheはあります。
それでも行列積では、Shared MemoryやRegistersを使い、行列積に合った再利用を明示的に制御する価値があります。
GPUもNPUもデータ再利用を行いますが、再利用する場所とデータの流し方が異なります。
この違いが、後編で扱うPE Array、Systolic Array、On-chip SRAM、データフローの理解につながります。
関連技術
| 技術 | 概要 | 本記事との関係 |
|---|---|---|
| GEMM | General Matrix Multiplication、汎用行列積 | ニューラルネットワーク計算の中心 |
| CUDA | NVIDIA GPU向けの並列プログラミングモデル | thread、block、Shared Memoryを扱う前提 |
| Tensor Core | 行列積和に特化した演算器 | MMAを高速に実行する |
| WMMA | Warp Matrix Multiply-Accumulate API | warp単位でTensor Coreを使う抽象化 |
| CUTLASS | CUDA Templates for Linear Algebra Subroutines | tile化GEMMやTensor Core利用の設計例 |
| GPU memory hierarchy | HBM/GDDR、L2、Shared Memory、Registersなど | tile化と再利用を理解する軸 |
| NPU | ニューラルネットワーク向け演算器 | 後編でGPUとの違いを扱う |
| Systolic Array | PE間でデータを流しながら再利用する配列 | NPUの代表的なデータフロー |
| Dataflow accelerator | データの流れを固定または制御して効率化するアクセラレータ | GPUとの再利用方式の比較対象 |
次に読むべき記事
後編では、NPUがどのようにデータを再利用するのかを、GPUとの違いから整理します。
後編の仮タイトルは次の通りです。
NPUはなぜDRAMアクセスを減らせるのか──PE ArrayとSystolic ArrayをGPUとの違いから理解する
後編の想定slugは、npu-systolic-array-dataflow です。
後編記事の想定URLは次の通りです。
後編レビュー時に、必要があれば最終URLまたは相対リンクへ調整します。

コメント