Attentionとは?Bahdanau Attention論文からLLMの「どこを見るか」を理解する
Attentionは、入力中の重要な情報を重み付きで参照し、今の出力に必要な文脈を動的に取り出す技術です。
3文要約
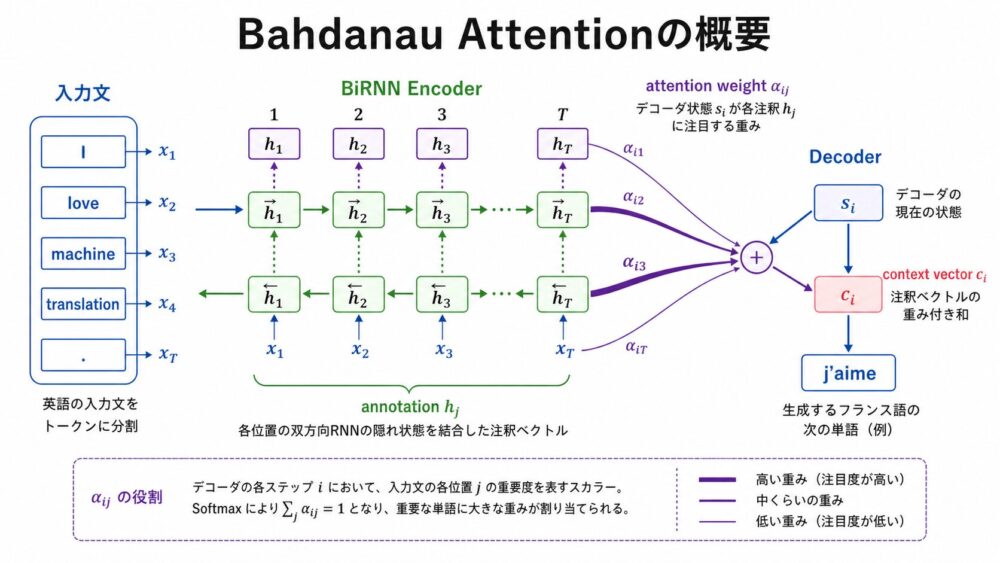
Attentionは、入力文のすべてを1つの固定長ベクトルへ押し込めるのではなく、出力する単語ごとに関連する入力位置を重み付きで参照する仕組みです。
Bahdanauらの論文では、翻訳の各ステップで入力文中の位置にsoft alignment(連続値の重みによる対応付け)を計算し、その重み付き和をcontext vectorとしてDecoderへ渡します。
この考え方は、その後のTransformerやLLMに直接つながる「必要な情報を動的に取り出す」発想の出発点として重要です。
論文情報
| 項目 | 内容 |
|---|---|
| 論文タイトル | Neural Machine Translation by Jointly Learning to Align and Translate |
| 著者 | Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio |
| 初版公開日 | 2014年9月1日 |
| 最終改訂 | 2016年5月19日 v7 |
| 採択 | ICLR 2015 oral presentation |
| 分野 | Computation and Language, Machine Learning |
| arXiv | Neural Machine Translation by Jointly Learning to Align and Translate |
| DOI | 10.48550/arXiv.1409.0473 |
Attentionとは何か
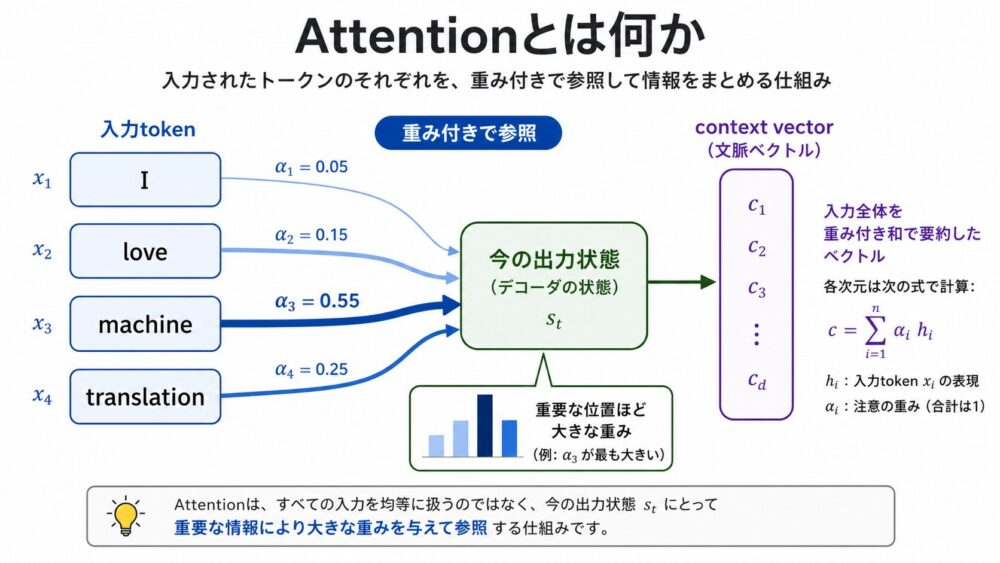
Attentionは、モデルが入力のどの部分を重視するかを重みとして計算し、その重みに応じて情報を取り出す仕組みです。
日本語では「注意機構」と訳されることがあります。
ただし、人間の注意をそのまま再現しているというより、ニューラルネットワーク内で「今の出力に必要な入力表現を重み付きで混ぜる」計算だと考えると分かりやすいです。
翻訳の例で考えます。
英語からフランス語へ翻訳するとき、次に出力する単語が zone なら、入力文中の Area や European Economic 周辺が重要になります。
次に出力する単語が signé なら、入力文中の signed 周辺が重要になります。
Attentionは、この「出力位置ごとに見るべき入力位置が変わる」という性質を、学習可能な重みとして扱います。
背景・課題:固定長ベクトルのボトルネック
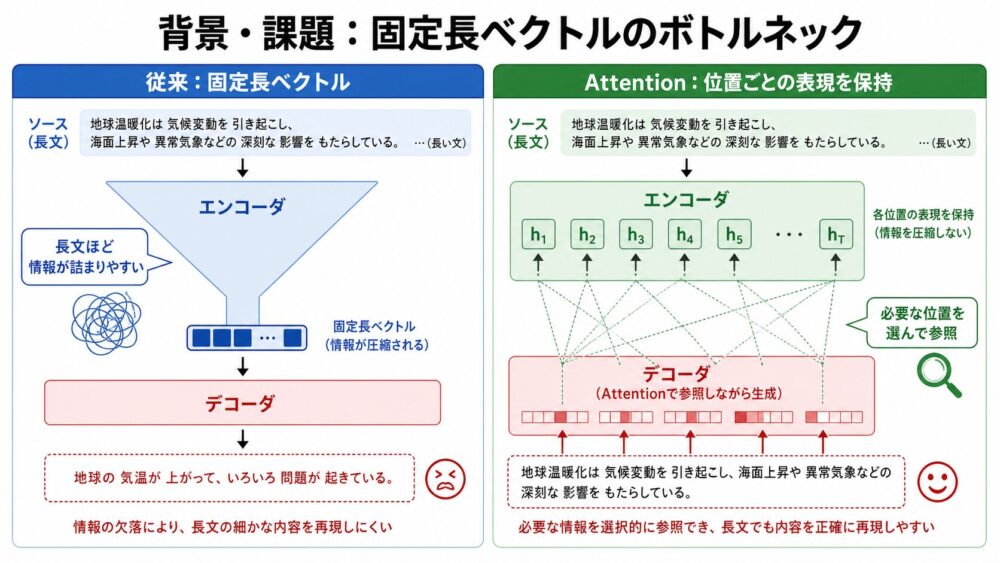
Bahdanau Attentionが登場する前の代表的なEncoder-Decoderモデルでは、Encoderが入力文全体を1つの固定長ベクトルへ圧縮し、Decoderがそのベクトルから翻訳文を生成していました。
この構造はシンプルですが、入力文が長くなるほど厳しくなります。
| 観点 | 固定長Encoder-Decoder | Attention付きEncoder-Decoder |
|---|---|---|
| 入力表現 | 入力文全体を1つのベクトルに圧縮 | 各入力位置の表現を系列として保持 |
| Decoderの参照先 | 同じcontext vectorを使い続ける | 出力単語ごとに異なるcontext vectorを使う |
| 長文への弱さ | 情報を詰め込みきれない可能性がある | 必要な位置を選んで参照しやすい |
| 対応関係の可視化 | 難しい | attention weightを行列として可視化できる |
論文では、この固定長ベクトルが翻訳性能を制限する可能性があると考え、入力文を1つに潰さず、入力位置ごとのannotation(入力各位置の文脈表現)として保持する設計を提案しています。
ここでのannotationは、画像の注釈ではなく、Encoderが各単語位置に対して作る特徴ベクトルのことです。
提案手法:jointly learning to align and translate
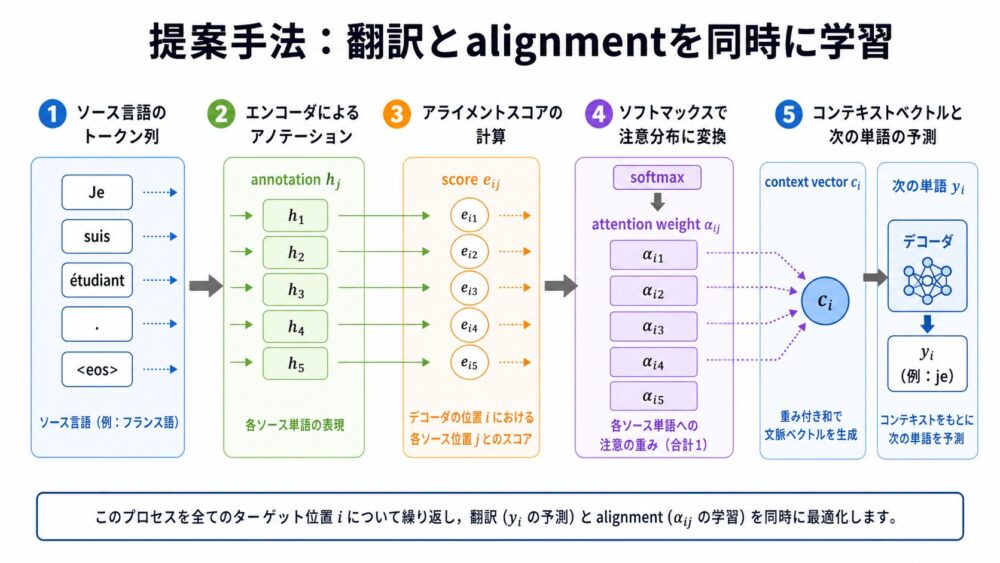
この論文の中心は、翻訳とalignment(入力単語と出力単語の対応付け)を同時に学習する点です。
従来の機械翻訳では、単語対応を別の手続きで推定することが多くありました。
Bahdanauらのモデルでは、alignmentを翻訳モデルの内部計算として扱い、誤差逆伝播で一緒に学習します。
流れは次のようになります。
- Encoderが入力文の各位置 $j$ に対してannotation $h_j$ を作る。
- Decoderが次の出力位置 $i$ で、過去のDecoder状態 $s_{i-1}$ と各 $h_j$ の相性をスコア化する。
- スコアをsoftmax(合計が1になる確率分布へ変換する関数)に通してattention weight $\alpha_{ij}$ を得る。
- $\alpha_{ij}$ で $h_j$ を重み付き和し、context vector $c_i$ を作る。
- Decoderは $c_i$ と過去の出力から次の単語を予測する。
固定長ベクトルを1回だけ渡すのではなく、出力単語ごとにcontext vectorを作り直す点が重要です。
数式で見るBahdanau Attention
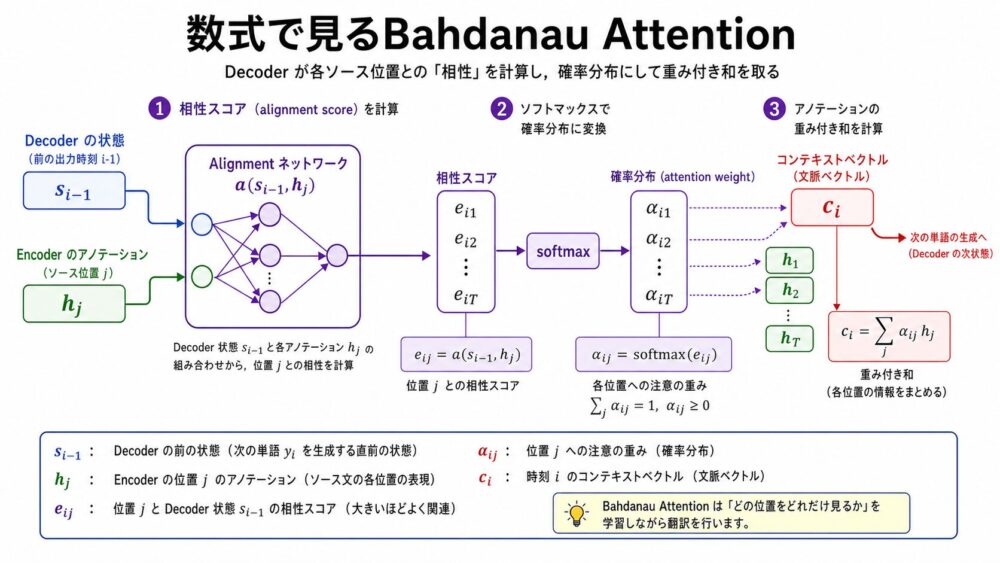
論文では、出力位置 $i$ の条件付き確率を次のように表します。
\[
p(y_i \mid y_1, \ldots, y_{i-1}, x) = g(y_{i-1}, s_i, c_i)
\]
$s_i$ はDecoderの隠れ状態、$c_i$ は出力位置 $i$ ごとに計算されるcontext vectorです。
context vectorは、入力側annotationの重み付き和です。
\[
c_i = \sum_{j=1}^{T_x} \alpha_{ij} h_j
\]
$T_x$ は入力文の長さ、$h_j$ は入力位置 $j$ のannotationです。
重み $\alpha_{ij}$ はsoftmaxで計算されます。
\[
\alpha_{ij} = \frac{\exp(e_{ij})}{\sum_{k=1}^{T_x} \exp(e_{ik})}
\]
ここで $e_{ij}$ はalignment scoreです。
\[
e_{ij} = a(s_{i-1}, h_j)
\]
$a$ はfeedforward neural network(順伝播型ニューラルネットワーク)としてパラメータ化され、翻訳モデル全体と一緒に学習されます。
この仕組みにより、$\alpha_{ij}$ は「出力単語 $y_i$ を生成するとき、入力位置 $j$ をどれくらい重視するか」を表します。
soft alignmentが重要な理由
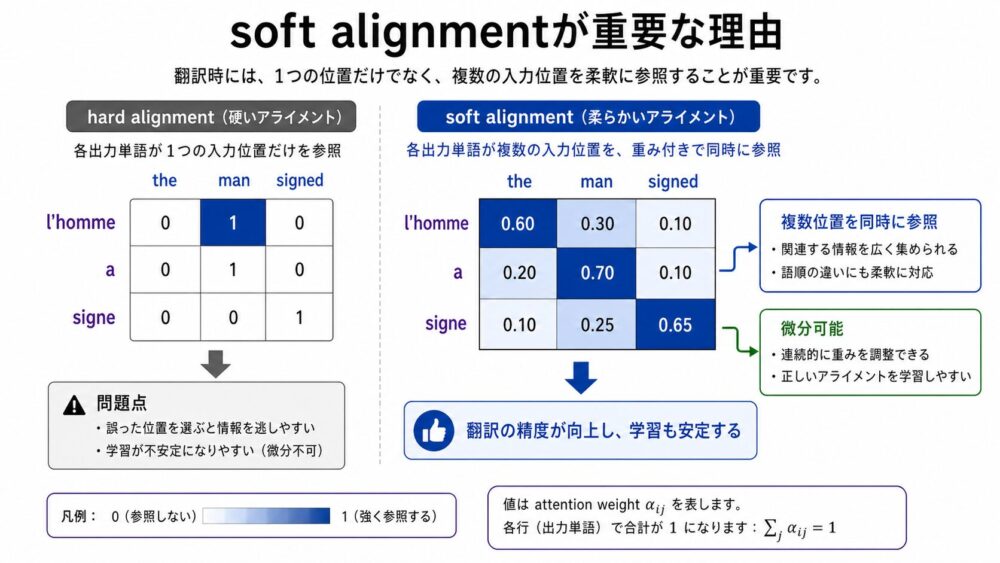
この論文で面白いのは、alignmentをhardに1対1で決めない点です。
soft alignmentでは、1つの出力単語が複数の入力位置を同時に少しずつ参照できます。
| 観点 | hard alignment | soft alignment |
|---|---|---|
| 対応 | 1つまたは少数の位置へ離散的に対応 | 全入力位置に連続値の重みを付ける |
| 学習 | 離散選択が絡み、扱いが難しい | softmaxにより微分可能 |
| 翻訳での利点 | 明確な対応には向く | 語順の入れ替えや句の対応に柔軟 |
| 可視化 | 対応線として見やすい | attention matrixとして見やすい |
たとえば、英語の the man をフランス語の l'homme に訳す場合、冠詞の訳は the だけで決まるわけではありません。
後続の名詞が男性名詞か女性名詞か、母音で始まるかなども関係します。
soft alignmentなら、the と man の両方を参照しながら訳語を決めることができます。
この柔軟さが、単語単位で無理に対応を固定しないAttentionの強みです。
Encoder:双方向RNNで入力位置ごとの表現を作る
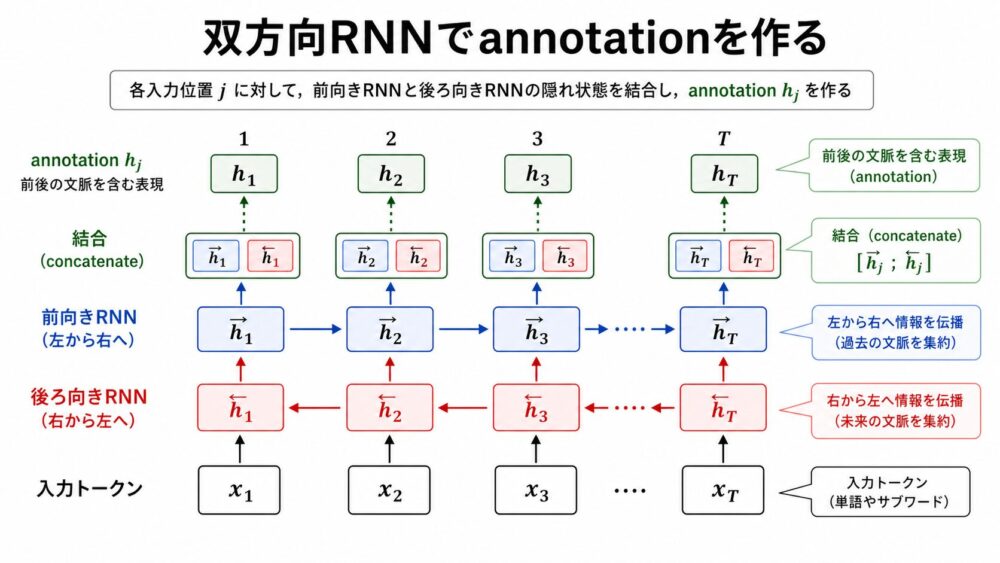
Bahdanauらのモデルでは、Encoderにbidirectional RNN(前向きと後ろ向きのRNNを組み合わせる構造)を使います。
通常のRNNは左から右へ読みますが、それだけだと各位置の表現は主に過去方向の情報を持ちます。
翻訳では、ある単語の意味を決めるために後ろの単語も重要です。
そこで論文では、前向きRNNと後ろ向きRNNの状態を結合してannotationを作ります。
\[
h_j = [\overrightarrow{h_j}; \overleftarrow{h_j}]
\]
これにより、各入力位置 $j$ のannotation $h_j$ は、前後の文脈を含んだ表現になります。
この「各位置に文脈化された表現を持たせる」という考え方は、後のBERTやTransformer Encoderの理解にもつながります。
実験結果:長文で効果が出やすい
論文では、WMT 2014 English-French翻訳タスクで評価しています。
比較対象は、AttentionなしのRNN Encoder-DecoderであるRNNencdecと、提案手法のRNNsearchです。
| モデル | All BLEU | No UNK BLEU | 特徴 |
|---|---|---|---|
| RNNencdec-30 | 13.93 | 24.19 | 30語以下で学習した固定長Encoder-Decoder |
| RNNsearch-30 | 21.50 | 31.44 | 30語以下で学習したAttention付きモデル |
| RNNencdec-50 | 17.82 | 26.71 | 50語以下で学習した固定長Encoder-Decoder |
| RNNsearch-50 | 26.75 | 34.16 | 50語以下で学習したAttention付きモデル |
| RNNsearch-50 長時間学習 | 28.45 | 36.15 | 開発セット性能が止まるまで長く学習 |
| Moses | 33.30 | 35.63 | 当時の句ベース統計的機械翻訳システム |
論文では、RNNsearchがすべての条件でRNNencdecを上回ったと報告されています。
特に重要なのは、文が長くなったときです。
固定長Encoder-Decoderは長文で性能が落ちやすい一方、RNNsearchは入力の必要な部分を選択的に参照できるため、長文でも比較的安定した結果を示しています。
ただし、この結果はEnglish-French翻訳タスク、当時のデータセット、RNNベースの設定における結果です。
現代のLLM全般にそのまま数値として当てはめるのではなく、Attentionが「長い入力の情報を動的に参照する設計」として有効だった例として読むのがよさそうです。
TransformerのSelf-Attentionとの違い
Bahdanau AttentionとTransformerのSelf-Attentionは、どちらも「重みを使って情報を混ぜる」点でつながっています。
一方で、構造はかなり違います。
| 観点 | Bahdanau Attention | Transformer Self-Attention |
|---|---|---|
| 主な文脈 | RNN Encoder-Decoder翻訳 | Transformer内部の系列処理 |
| 参照関係 | Decoder状態がEncoder出力を見る | 同じ系列内のtoken同士が互いを見る |
| スコア計算 | feedforward networkで $a(s_{i-1}, h_j)$ を計算 | QueryとKeyの内積を使うことが多い |
| 時間方向 | Decoderは逐次生成 | 層内では並列計算しやすい |
| LLMとの関係 | Attention発想の重要な先行研究 | 現代LLMの中核構造 |
つまり、Bahdanau Attentionは「翻訳Decoderが入力文のどこを見るか」を学習する仕組みです。
TransformerのSelf-Attentionは「同じ文中の各tokenが他のtokenをどう参照するか」を計算する仕組みです。
名前は似ていますが、実装や計算の形は同じではありません。
ただし、出力に必要な情報を固定ベクトルに閉じ込めず、重み付きで動的に取り出すという考え方は共通しています。
実装イメージ:Bahdanau Attention
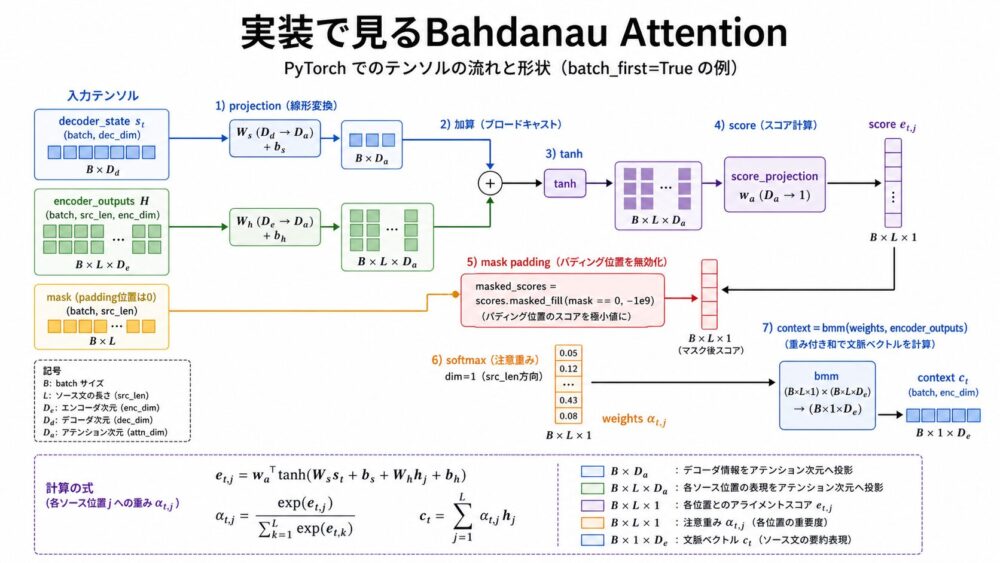
Bahdanau Attentionは、additive attention(加算型Attention)として説明されることが多いです。
以下は、論文の $e_{ij}=a(s_{i-1}, h_j)$、$\alpha_{ij}=\mathrm{softmax}(e_{ij})$、$c_i=\sum_j\alpha_{ij}h_j$ を、そのまま実装へ対応させた例です。
実務で必要になりやすいpadding maskも含めています。
import logging
import torch
from torch import Tensor, nn
logger = logging.getLogger(__name__)
class BahdanauAttention(nn.Module):
"""Compute Bahdanau attention with optional padding mask.
Args:
decoder_hidden_size: Hidden size of the previous decoder state.
encoder_hidden_size: Hidden size of each encoder annotation.
attention_hidden_size: Internal size of the alignment network `a`.
Returns:
A module that maps decoder state and encoder annotations to context.
Raises:
ValueError: If hidden sizes are not positive.
Example:
>>> attention = BahdanauAttention(16, 20, 8)
>>> s_prev = torch.randn(2, 16)
>>> annotations = torch.randn(2, 5, 20)
>>> source_mask = torch.ones(2, 5, dtype=torch.bool)
>>> context, weights = attention(s_prev, annotations, source_mask)
>>> context.shape, weights.shape
(torch.Size([2, 20]), torch.Size([2, 5]))
"""
def __init__(
self,
decoder_hidden_size: int,
encoder_hidden_size: int,
attention_hidden_size: int,
) -> None:
super().__init__()
if decoder_hidden_size <= 0 or encoder_hidden_size <= 0 or attention_hidden_size <= 0:
raise ValueError("hidden sizes must be positive")
self.decoder_projection = nn.Linear(decoder_hidden_size, attention_hidden_size, bias=False)
self.encoder_projection = nn.Linear(encoder_hidden_size, attention_hidden_size, bias=False)
self.score_projection = nn.Linear(attention_hidden_size, 1, bias=False)
def forward(
self,
previous_decoder_state: Tensor,
encoder_annotations: Tensor,
source_mask: Tensor | None = None,
) -> tuple[Tensor, Tensor]:
"""Return context vector `c_i` and attention weights `alpha_ij`.
Args:
previous_decoder_state: Previous decoder state `s_{i-1}` shaped `(batch, decoder_hidden_size)`.
encoder_annotations: Encoder annotations `h_j` shaped `(batch, source_len, encoder_hidden_size)`.
source_mask: Optional boolean tensor shaped `(batch, source_len)`.
`True` means the source position is valid, and `False` means padding.
Returns:
`(context, weights)`. `context` is the weighted sum `c_i` shaped
`(batch, encoder_hidden_size)`, and `weights` is `alpha_ij` shaped
`(batch, source_len)`.
Raises:
ValueError: If tensor ranks, batch sizes, or mask shapes are invalid.
Example:
>>> attention = BahdanauAttention(4, 6, 3)
>>> s_prev = torch.randn(1, 4)
>>> annotations = torch.randn(1, 7, 6)
>>> mask = torch.tensor([[True, True, True, False, False, False, False]])
>>> context, weights = attention(s_prev, annotations, mask)
>>> weights.sum(dim=-1).round()
tensor([1.], grad_fn=<RoundBackward0>)
"""
if previous_decoder_state.ndim != 2:
raise ValueError("previous_decoder_state must have shape (batch, decoder_hidden_size)")
if encoder_annotations.ndim != 3:
raise ValueError("encoder_annotations must have shape (batch, source_len, encoder_hidden_size)")
if previous_decoder_state.shape[0] != encoder_annotations.shape[0]:
raise ValueError("previous_decoder_state and encoder_annotations must have the same batch size")
if source_mask is not None and source_mask.shape != encoder_annotations.shape[:2]:
raise ValueError("source_mask must have shape (batch, source_len)")
logger.debug(
"compute bahdanau attention: batch=%d source_len=%d",
encoder_annotations.shape[0],
encoder_annotations.shape[1],
)
# 論文の alignment model a(s_{i-1}, h_j) を全入力位置 j に対してまとめて計算する。
decoder_features = self.decoder_projection(previous_decoder_state).unsqueeze(1)
annotation_features = self.encoder_projection(encoder_annotations)
scores = self.score_projection(torch.tanh(decoder_features + annotation_features)).squeeze(-1)
if source_mask is not None:
# padding位置を選べないようにして、softmax後の重みを有効tokenだけへ割り当てる。
scores = scores.masked_fill(~source_mask, torch.finfo(scores.dtype).min)
weights = torch.softmax(scores, dim=-1)
# soft alignmentを期待値として扱うため、annotation h_j の重み付き和として c_i を作る。
context = torch.bmm(weights.unsqueeze(1), encoder_annotations).squeeze(1)
logger.info("created bahdanau attention context: shape=%s", tuple(context.shape))
return context, weightsこの実装では、previous_decoder_state が論文の $s_{i-1}$、encoder_annotations が $h_j$、scores が $e_{ij}$、weights が $\alpha_{ij}$、context が $c_i$ に対応します。
翻訳や系列変換のbatchでは文長をそろえるためにpaddingを入れることが多いため、source_mask でpadding位置をsoftmaxの対象から外しています。
よくある誤解
| 誤解 | 正確な見方 |
|---|---|
| AttentionはTransformerで初めて出た | Transformer以前からRNN翻訳などで重要な役割を持っていた |
| Attention weightは必ず人間の説明になる | 参照傾向の可視化には使えるが、常に因果的説明とは限らない |
| Bahdanau AttentionとSelf-Attentionは同じ | 重み付き参照という発想は共通だが、参照関係とスコア計算が違う |
| Attentionがあれば長文問題は完全に解決する | 固定長圧縮の弱さは緩和されるが、計算量や学習データなど別の制約は残る |
関連技術
| 技術 | 関係 |
|---|---|
| Encoder-Decoder | Attentionが導入された翻訳モデルの土台 |
| BiRNN | 入力位置ごとの前後文脈を持つannotationを作る |
| Self-Attention | Transformerで系列内token同士の関係を計算する仕組み |
| Cross-Attention | DecoderがEncoder出力など別系列を参照するAttention |
| KV Cache | 自己回帰生成で過去のKey/Valueを再利用する高速化技術 |
まとめ
Bahdanau Attentionは、固定長ベクトルに入力文全体を押し込めるEncoder-Decoderの弱点を、出力単語ごとの動的な参照で緩和した手法です。
論文では、入力位置ごとのannotationにattention weightを付け、重み付き和としてcontext vectorを作ることで、翻訳とalignmentを同時に学習します。
現代のLLMで使われるSelf-Attentionとは構造が違いますが、「必要な情報を重み付きで取り出す」という発想を理解する入口として非常に重要です。
次回のTransformer編では、このAttentionの考え方が、RNNを使わない並列計算しやすいアーキテクチャへどう発展したのかを見ていきます。
次に読むべき記事
- LLMシリーズ第3回: Embeddingとは?BERT論文から単語・文章をベクトルで表す仕組みを解説
- LLMシリーズ第5回: Transformerとは?Attention Is All You Needを実装目線で読む
- LLMシリーズ第6回: Self-Attentionとは?Scaled Dot-Product Attentionを数式から理解する

コメント