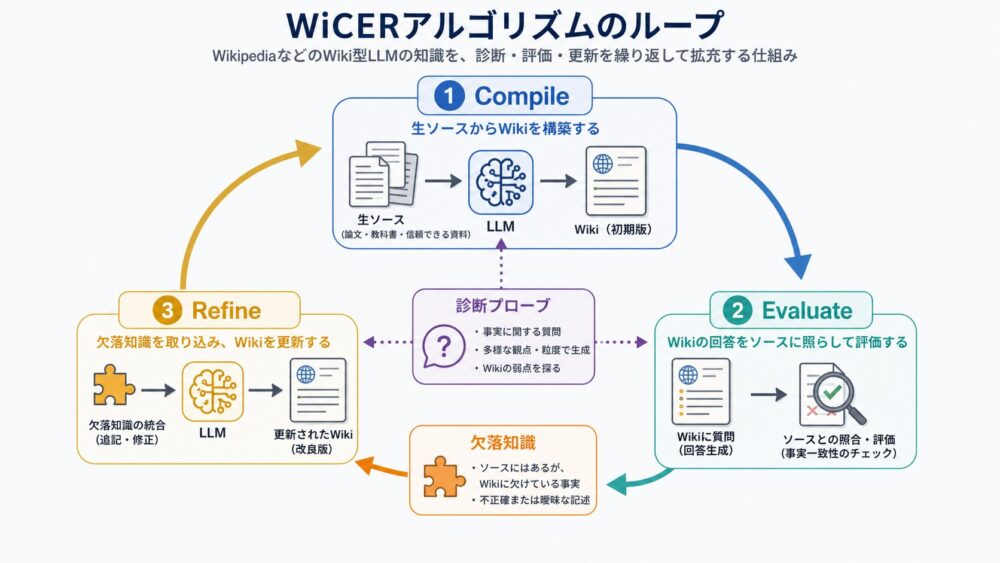
概念図:実際の製品回路を理解しやすく簡略化した図。
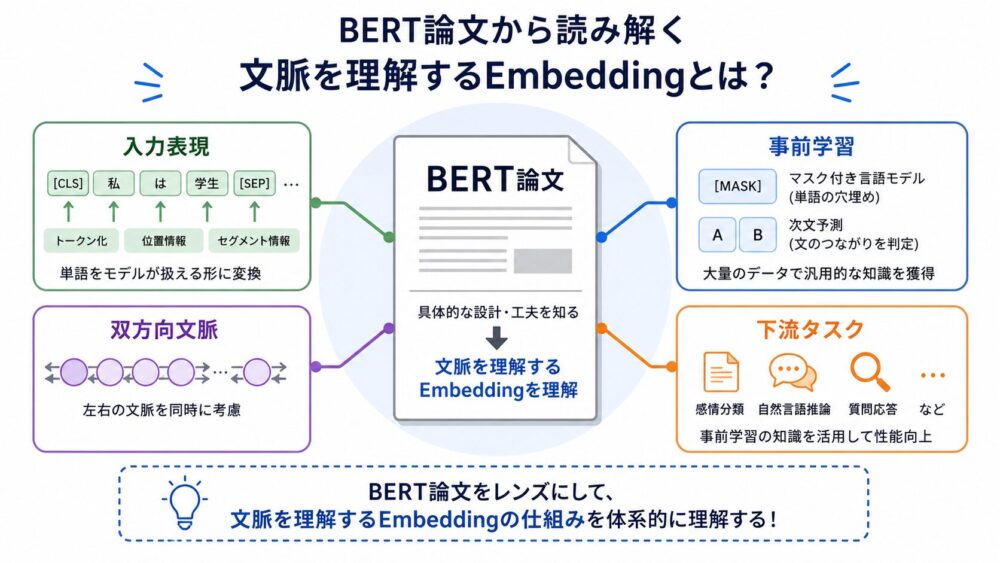
本記事の目的
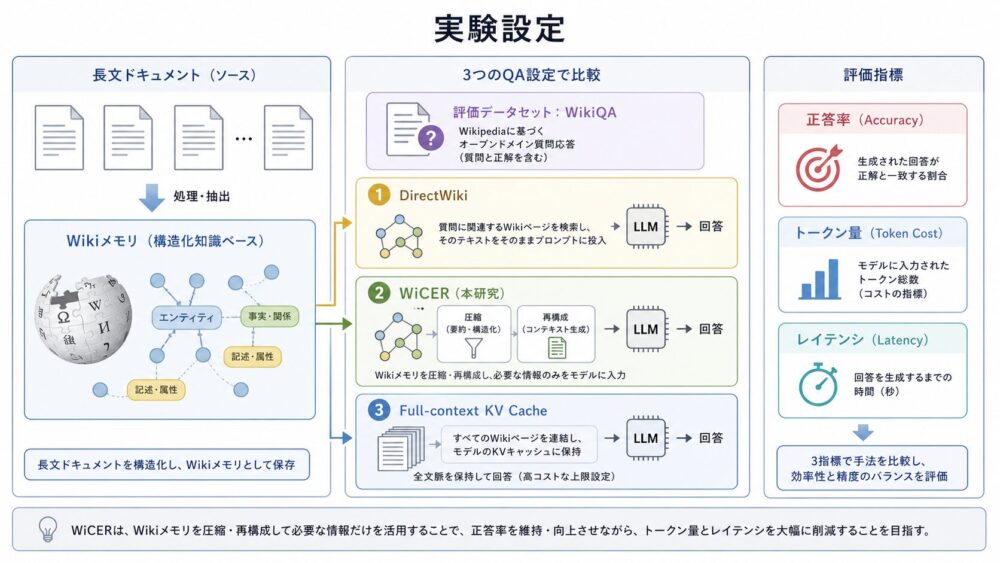
前編では、GPUが行列積をtile(小さな部分行列)へ分割し、Shared Memory(SM内で共有する高速メモリ)やRegisters(thread近傍の保存領域)でA/B tileを再利用する仕組みを整理しました。
前編はこちらです。
GPUはなぜ行列積をtile化するのか──thread・warp・Shared Memory・Tensor Coreを積和から理解する
本記事では、NPU(Neural Processing Unit、ニューラルネットワーク処理向けアクセラレータ)が、PE Array(Processing Elementの配列)やSystolic Array(拍動するようにデータを隣接セルへ流す配列構造)を使って、なぜDRAMへの高コストなアクセスを減らしやすいのかを説明します。
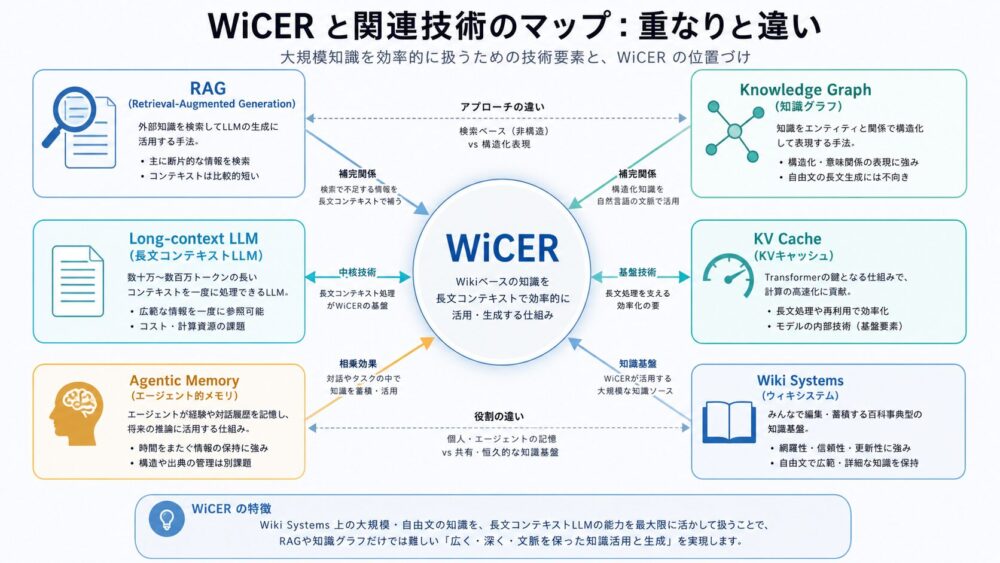
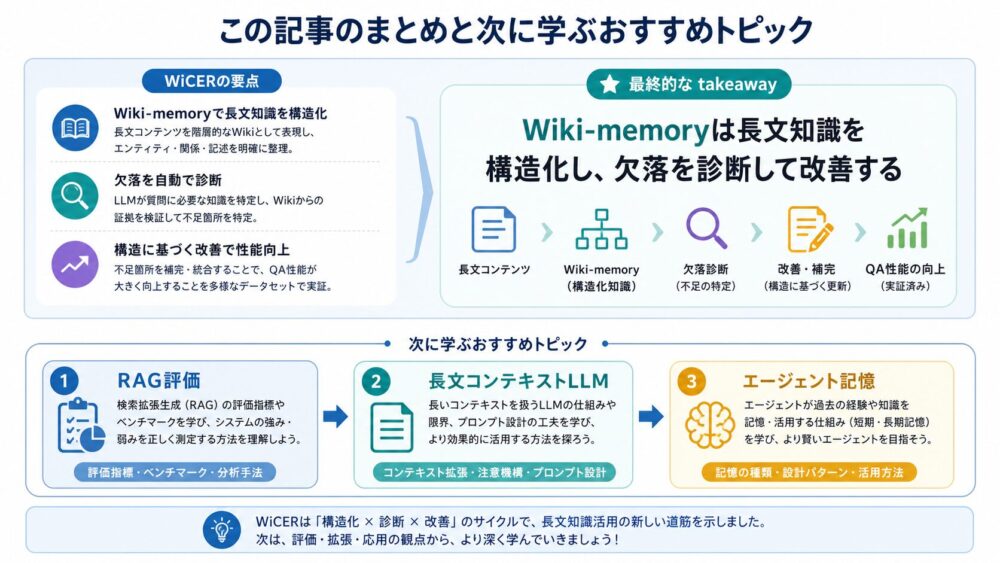
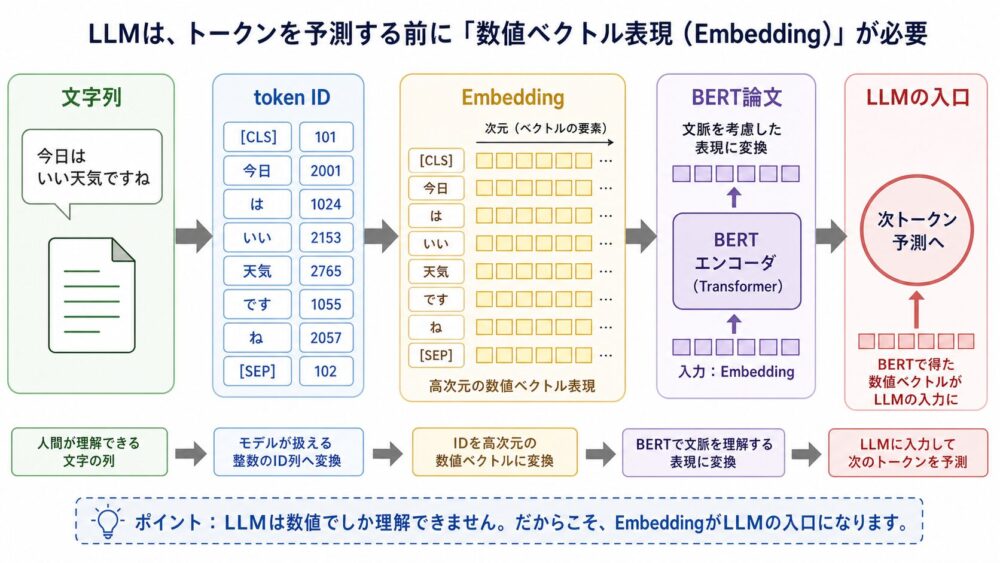
重要なのは、NPUが「AI専用チップだから速い」とだけ理解しないことです。GPUもNPUもデータ再利用を行います。違いは、GPUが近いメモリ階層にtileを置いて再利用するのに対し、NPUはPE Array内の空間的なデータフローそのものへ再利用を埋め込みやすい点にあります。
3文要約
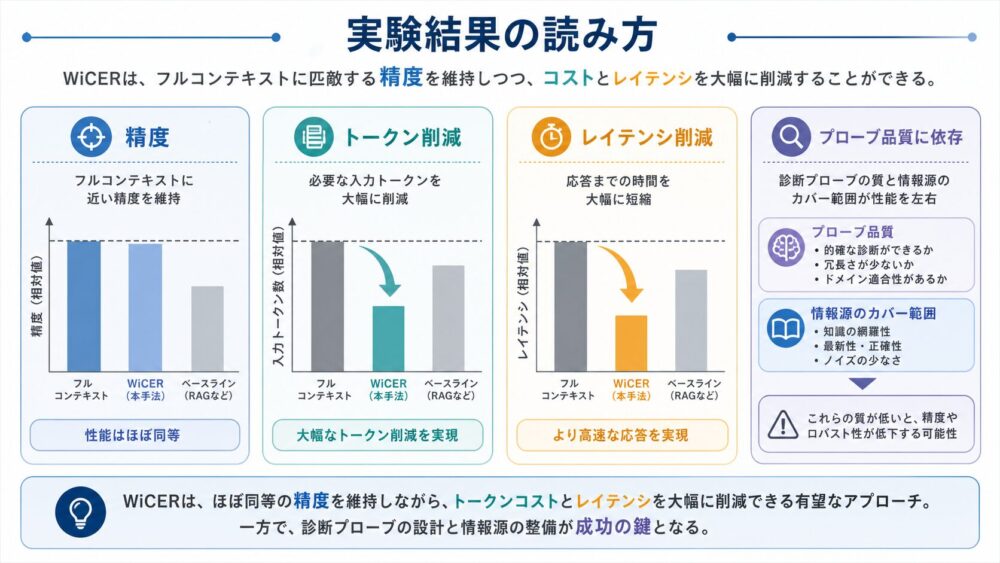
NPUもGPUと同じく、大きな行列をtileへ分割して処理します。On-chip SRAM(チップ内SRAM)へ持ち込んだA/B tileをFIFO(先入れ先出しバッファ)からPE Arrayへ供給し、隣接PEへ渡しながら複数のMAC(Multiply-Accumulate、乗算加算)へ再利用します。DRAMアクセスをゼロにするのではなく、DRAMアクセスや長距離通信のような高コストなデータ移動を、多数のMACへ償却しやすいことが本質です。
論文・一次資料情報
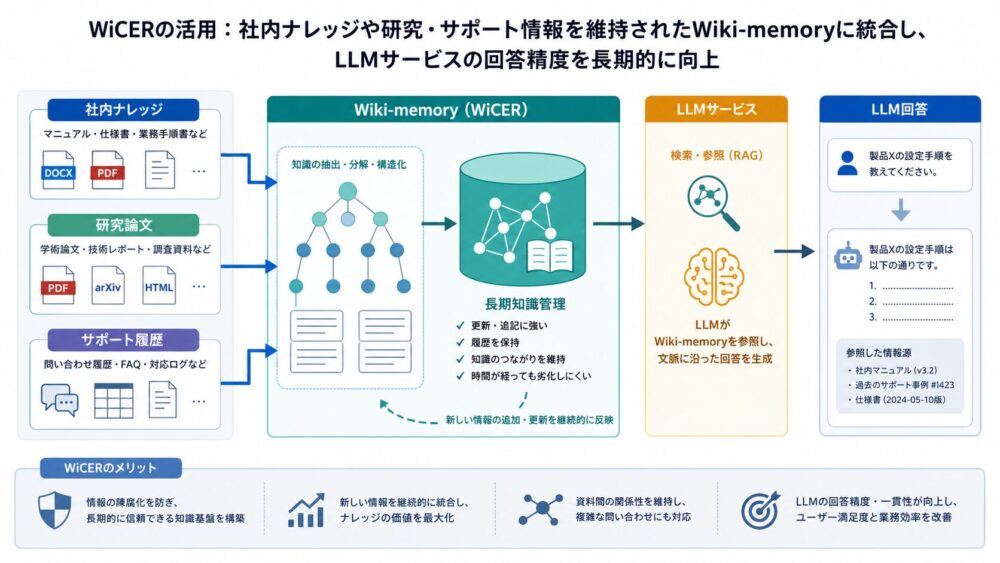
この記事は、単一論文の要約ではありません。Systolic Arrayの考え方、TPUv1の行列積ユニット、Eyerissのdataflow設計を組み合わせ、NPUのデータ移動を理解するための概念として整理します。
| 種別 | タイトル | 著者・組織 | 年 | この記事で参照する内容 | リンク |
|---|---|---|---|---|---|
| 論文 | Why Systolic Architectures? | H. T. Kung | 1982 | Systolic Architectureの基本思想。隣接セル間でデータを規則的に流し、局所通信で計算を進める考え方 | Why Systolic Architectures? |
| 論文 | In-Datacenter Performance Analysis of a Tensor Processing Unit | Norman P. Jouppi et al. | 2017 | TPUv1をSystolic Array型アクセラレータの代表例として参照。65,536個の8-bit MACとソフトウェア管理のOn-chip Memoryを持つ例 | In-Datacenter Performance Analysis of a Tensor Processing Unit |
| 論文 | Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks | Yu-Hsin Chen et al. | 2016 | CNN向けアクセラレータで、データ再利用を意識したdataflow設計の例として参照 | Eyeriss |
| 論文 | Eyeriss v2: A Flexible Accelerator for Emerging Deep Neural Networks on Mobile Devices | Yu-Hsin Chen et al. | 2018 | DNN形状に応じたデータ再利用、PE Array、Global Buffer、NoC(Network-on-Chip)の設計例 | Eyeriss v2 |
注意点として、NPUは特定製品名ではなく広い分類です。TPUv1、Eyeriss、スマートフォンのモバイルNPUは、内部構成、対応演算子、データフロー、メモリ容量が同じではありません。本記事では、TPUv1をSystolic Array型アクセラレータの代表例、Eyerissをデータ再利用を最適化するdataflow設計の代表例として扱います。
行列積とPEが実行する積和
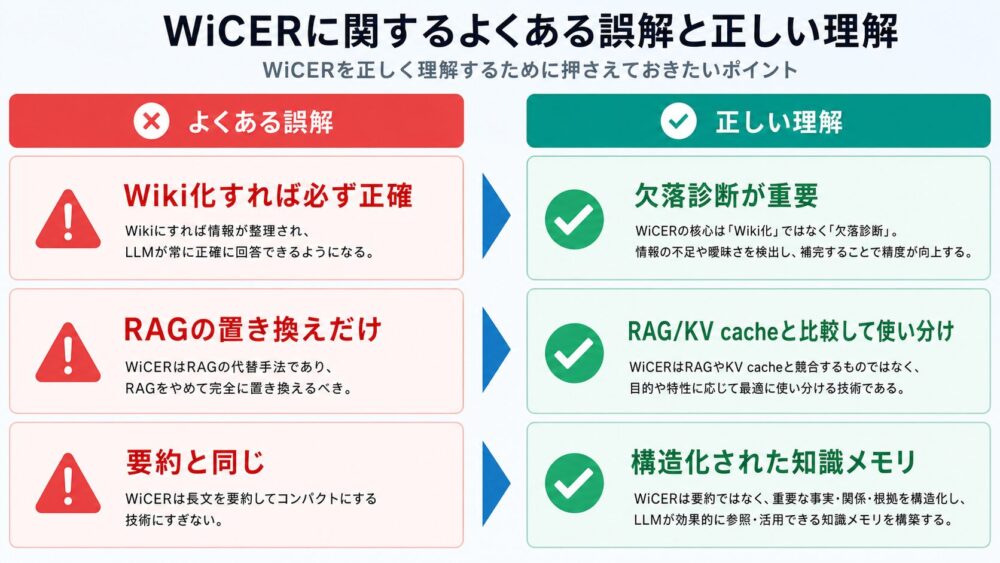
ニューラルネットワークの推論では、畳み込み、全結合層、attention(系列内の要素間関係を重み付けする処理)などが、行列積または行列積に近い形へ変換されます。
\[ C = A \times B \]
各出力要素は、次のようなK方向の積和で作られます。
\[ C_{i,j} = \sum_k A_{i,k}B_{k,j} \]
3×3の例で、\( C_{1,1} \) は次のように作られます。
\[ C_{1,1} = A_{1,1}B_{1,1} + A_{1,2}B_{2,1} + A_{1,3}B_{3,1} \]
ここで、Aはactivation(アクティベーション、前段の出力)または入力、Bはweight(重み)、Cは出力または部分和です。
NPUの文脈で重要なのは、PEが単なるメモリではなく、\( \mathrm{partial\_sum} += A \times B \) を実行するMAC演算要素である点です。Accumulator(累算器)は、K方向に複数回発生する積和の途中結果を保持します。つまり、PEがMACを実行し、AccumulatorがCの部分和を保持する、という役割分担です。
NPUの典型回路構成
NPUの内部構成は製品や研究チップごとに異なりますが、行列積や畳み込みを効率よく処理するアクセラレータでは、概念的に次のような流れでデータを扱います。
DRAM ↓ On-chip SRAM / Unified Buffer ↓ Activation FIFO (A) と Weight FIFO (B) ↓ PE Array / Systolic Array ↓ Accumulator / Output Buffer ↓ DRAM
| 回路 | 初学者向けの比喩 | 技術的役割 |
|---|---|---|
| DRAM | 大きい倉庫 | 大容量の重み・入力・出力を保存する |
| On-chip SRAM | ライン横の材料置き場 | tileを保持し、DRAMアクセスを減らす |
| FIFO | ベルトコンベアの入口 | A/Bを規則的なタイミングでPEへ供給する |
| PE | 小さな作業員兼加工機 | MACを実行し、部分和を更新する |
| PE Array | 作業ライン | 多数PEを並べ、データを隣へ流す |
| Accumulator | 途中結果置き場 | Cの部分和を蓄積する |
| Output Buffer | 完成品置き場 | 出力をまとめ、後段またはDRAMへ渡す |
SRAM、FIFO、PE、Accumulatorは同じものではありません。SRAMとFIFOはデータを置き、規則的に供給するための回路です。PEは演算器を含む計算セルです。Accumulatorは、Cの部分和を保持する回路です。
NPUであっても、巨大な行列全体を常にOn-chip SRAMへ置けるとは限りません。そのため、NPUもGPUと同じく、行列をtile単位で持ち込み、必要な範囲を処理してから次のtileへ入れ替えます。
Systolic Arrayを時間方向に追う
Systolic Arrayは、PEを格子状に並べ、データを隣接PEへ規則的に流しながら計算する構造です。心臓の拍動のように、一定のリズムでデータが配列内を進むため、systolicという名前が付いています。
代表的な行列積mappingでは、Aの要素を左から右へ流し、Bの要素を上から下へ流します。各PEは、流れてきたAとBを使ってMACを実行し、自分が担当するC要素の部分和を更新します。
時刻 t0
t0では、Aの先頭要素が左端PEへ投入され、Bの先頭要素が上端PEへ投入されます。左上のPEだけが最初のMACを実行します。
この段階では、PE Array全体はまだ埋まっていません。DRAMから持ってきたA/B tileは、On-chip SRAMとFIFOを経由して、配列の入口へ供給され始めた状態です。
時刻 t1
t1では、Aの要素が右隣PEへ進み、Bの要素が下隣PEへ進みます。同時に、新しいA/B要素も左端・上端から投入されます。
この結果、複数のPEが同時にMACを実行します。A/Bが波のようにPE Arrayへ広がり、同じA要素は横方向の複数PEで、同じB要素は縦方向の複数PEで使われます。
時刻 t2以降
t2以降は、PE Arrayのより広い範囲でMACが並列に進みます。各PEは、自分が担当するC要素の部分和をPE内またはAccumulator方向へ蓄積します。K方向の積和が完了すると、Cの要素またはC tileが完成します。
ここで重要なのは、1回読み込んだA/B要素を、DRAMから毎回取り直すのではなく、局所配線を通じて隣のPEへ渡す点です。これにより、1回のDRAMロードを複数MACへ再利用しやすくなります。
ただし、これは代表的なmappingの概念例です。実際のNPUでは、A/B/Cの移動方向、部分和の保持場所、weight stationary(重みを固定する方式)、output stationary(出力部分和を固定する方式)、row-stationary dataflow(畳み込みの複数種の再利用をバランスさせる方式)などが異なり得ます。
NPUはなぜデータ移動を減らしやすいのか
NPUについて、「データ移動がゼロになる」と理解すると誤解になります。実際には、NPUもDRAMからA/B tileを読み込み、完成したC tileをDRAMへ書き戻します。減らしやすいのは、特にDRAMアクセスや長距離通信のような高コストな移動です。
GPUの再利用は、概念的には次のような流れです。
HBM/GDDR → L2 → Shared Memory → Registers → Tensor Core
GPUは、A/B tileを近いメモリへ置き、同じtileを複数の積和へ使います。大きい行列ではK方向にtile入れ替えを繰り返します。つまり、GPUはメモリ階層を通じて演算器へデータを供給する方式です。
NPUの再利用は、概念的には次のような流れです。
DRAM → On-chip SRAM → FIFO → PE → 隣のPE → 隣のPE
NPUは、A/B tileをOn-chip SRAMへ持ち込んだ後、FIFOを通じてPE Arrayへ供給します。そして、PE Array内の局所配線を使い、A/Bを隣のPEへ渡します。これにより、1回のDRAMロードを複数PEのMACへ再利用しやすくなります。
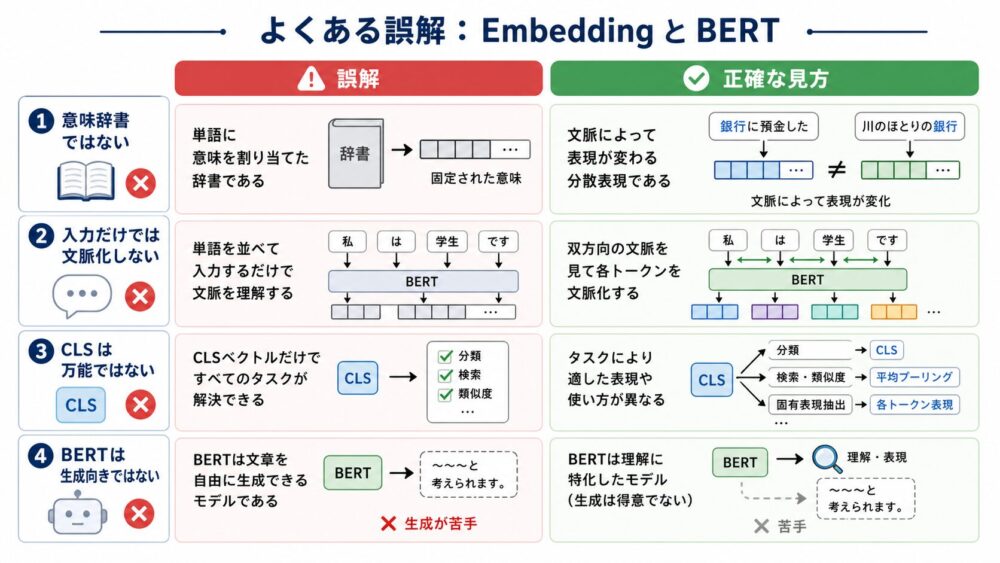
| よくある誤解 | 正確な情報・解釈 |
|---|---|
| NPUはDRAMアクセスが不要 | NPUもDRAMからtileを読み込み、出力を書き戻す |
| NPUは行列をtile化しない | SRAM容量を超える行列はNPUでもtile化する |
| GPUは再利用しない | GPUもShared MemoryやRegistersで再利用する |
| NPUはデータを動かさない | NPUも移動させるが、PE間の局所通信へ置き換えやすい |
| NPUは常にGPUより高速・省電力 | モデル、精度、batch、データフロー、コンパイラ、帯域に依存する |
GPUとNPUの差は、GPUが再利用せずNPUだけが再利用することではありません。両者とも再利用します。GPUがメモリ階層の近い場所にtileを置いて再利用するのに対し、NPUはPE Arrayの空間的なデータフローそのものに再利用を埋め込む点が大きな違いです。
GPUとNPUの回路構成・データフロー比較
前編のGPUと、本記事のNPUを並べると、違いは「再利用するかどうか」ではなく、「どこで、どう再利用するか」にあります。
| 観点 | GPU | NPU |
|---|---|---|
| 主な実行単位 | thread / warp / SM | PE / PE Array |
| 積和の実行場所 | Tensor Core / CUDA Core | PE |
| 主な再利用場所 | Shared Memory / Registers | PE Array / On-chip SRAM |
| 再利用方法 | 近いメモリから複数回読む | 配列内を流し、隣のPEへ渡す |
| メモリ階層 | HBM/GDDR、L2、SM内メモリ | DRAM、SRAM、FIFO、PE近傍メモリ |
| 遠いメモリへのアクセス | tile入れ替えに伴い発生 | tileロード・書き戻しで発生 |
| 強み | 柔軟性、汎用性、多様な演算 | 規則的な行列積での効率、電力効率、レイテンシ予測性 |
| たとえ | 作業台に材料を置いて何度も使う | ベルトコンベアで隣へ渡しながら加工する |
GPUは、thread、warp(NVIDIA GPUでは通常32 threadsの実行単位)、SM、Shared Memory、Registers、Tensor Coreを組み合わせ、多様な演算を高い柔軟性で処理できます。一方、NPUは、演算パターンが規則的なGEMM(General Matrix Multiplication、汎用行列積)や畳み込みで、PE Arrayのデータフローをうまく使える場合に効率を出しやすい設計です。
ただし、NPUが常にGPUより優れるわけではありません。動的shape(実行時にテンソル形状が変わる処理)、複雑な分岐、未対応演算子、頻繁なモデル変更では、GPUやCPUの柔軟性が有利になる場合があります。
カメラAI・画像処理への応用
カメラAIでは、DLNR(Deep Learning Noise Reduction、深層学習ノイズ低減)、Demosaic(カラーフィルタ配列からRGB画像を復元する処理)、Super Resolution(超解像)、Transformer系画像処理などが使われます。
モデル形状が比較的固定で、畳み込みやGEMM中心なら、NPUは有利になりやすいです。理由は、入力・重み・部分和の流れを事前に最適化しやすく、PE Array上での再利用を設計しやすいためです。
一方で、動的shape、複雑な分岐、独自演算、頻繁なモデル変更、研究段階の試行では、GPUの柔軟性が有利になりやすいです。NPUは対応演算子、対応精度、SRAM容量、メモリ帯域、コンパイラの成熟度に強く依存します。
実機のカメラパイプラインでは、CPU、GPU、ISP、DSP(Digital Signal Processor、信号処理向けプロセッサ)、NPUを役割分担させる場合があります。GPUかNPUかの二択ではなく、演算特性とデータフローによって配置先を決めるべきです。
NPU搭載時には、ISPとの入出力形式、メモリ共有、レイテンシ制約、対応する量子化精度、モデル更新のしやすさも課題になります。特に高ISOノイズ除去や高解像度化ではfeature map(特徴マップ)が大きくなり、オンチップ容量と外部メモリ帯域が効きやすくなります。
まとめ
NPUは、行列をtileとしてOn-chip SRAMへ持ち込んだ後、AとBをPE Arrayの中で規則的に流し、隣接PEへ受け渡しながら積和します。
DRAMアクセスを完全になくすのではありません。大きな行列では、NPUでもtileロードと書き戻しが必要です。
本質は、DRAMアクセスや長距離通信のような高コストなデータ移動を多数のMACへ償却し、PE間の局所的な通信へ置き換えやすい点です。GPUもNPUも再利用しますが、GPUは近いメモリ階層でtileを再利用し、NPUはPE Arrayの空間的なデータフローに再利用を埋め込みます。
関連技術
| 関連技術 | 概要 |
|---|---|
| Systolic Array | データを隣接PEへ規則的に流しながら計算する配列構造 |
| PE Array | MACを実行するPEを多数並べた計算配列 |
| MAC | Multiply-Accumulate。\( \mathrm{partial\_sum} += A \times B \) の演算 |
| Dataflow accelerator | データの流れを設計の中心に置くアクセラレータ |
| Row-stationary dataflow | Eyerissで扱われる、畳み込みの複数種の再利用を意識したdataflow |
| TPU | GoogleのTensor Processing Unit。TPUv1はSystolic Array型アクセラレータの代表例 |
| Eyeriss | CNN向けエネルギー効率アクセラレータ。データ再利用とdataflow設計の代表例 |
| On-chip SRAM | チップ内に置かれる高速メモリ。DRAMアクセス削減に使われる |
| NoC | Network-on-Chip。チップ内のデータ転送ネットワーク |
| GPU | 汎用性の高い並列プロセッサ。Shared MemoryやRegistersでtileを再利用する |
| Tensor Core | NVIDIA GPUの行列積和向け演算器。GPU前編で扱った中心要素 |
次に読むべき記事
GPU側のtile化、thread、warp、SM、Shared Memory、Registers、Tensor Coreの関係は、前編で詳しく整理しています。
GPUはなぜ行列積をtile化するのか──thread・warp・Shared Memory・Tensor Coreを積和から理解する
GPUとNPUの違いを理解するときは、「GPUは再利用しない、NPUだけが再利用する」と考えないことが重要です。両者とも再利用します。違いは、GPUが近いメモリ階層にtileを置いて再利用するのに対し、NPUがPE Array内のデータフローに再利用を埋め込みやすい点です。

コメント