LLMとは?ChatGPTの原点をGPT-3論文から読み解く
LLMとは、大量のテキストから「文脈の次に来るtoken(モデルが扱う文字列の単位)」を予測する力を学び、指示、質問、例示に応じて文章を生成する大規模言語モデルです。
この記事は、LLM記事シリーズを読み始める前に、全体像と学習の道筋をつかむための記事です。
この記事を読むと、LLMが「大量のテキストから次tokenを予測するモデル」であること、TransformerやSelf-Attentionがどこで効いているのか、そしてFew-shot prompting(少数例をプロンプトに入れる使い方)がなぜ出力の安定に関係するのかが分かります。
また、このシリーズでは本記事を入口として、Tokenization、Embedding、Attention、Transformer、Self-Attention、Positional Encoding、Decoder-only Transformerを順番に扱い、その後にFine-tuning、RAG(検索で外部知識を補強する手法)、マルチモーダルAI(画像・音声なども扱うAI)など、LLMを実サービスで使うための発展技術へ進んでいきます。
1. 3行要約
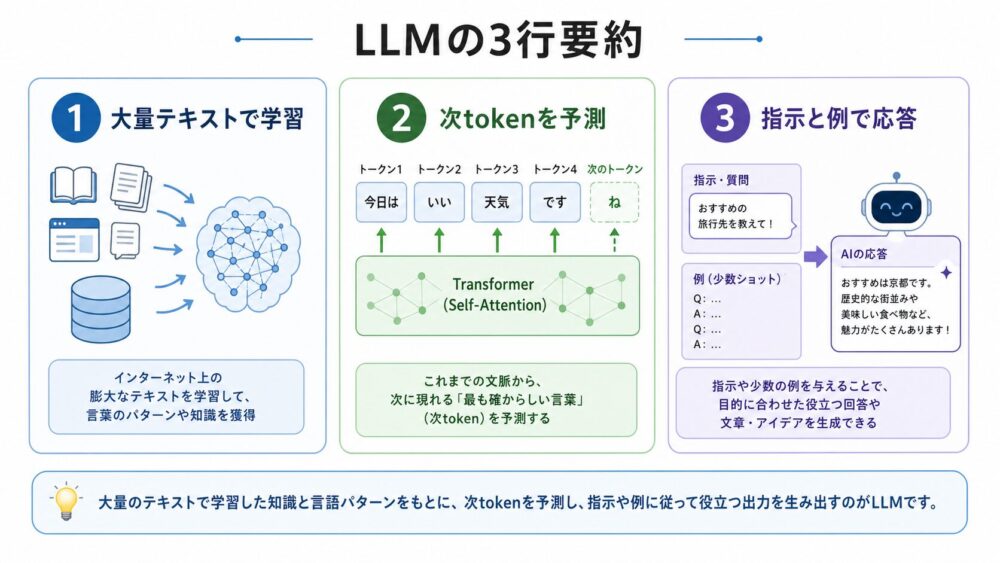
- LLMは、大量のテキストから次token予測を学ぶことで、文章生成、質問応答、翻訳、要約などに使える基盤モデルになります。
- その中核には、Tokenization、Embedding、Transformer、Self-Attention、Decoder-only構造などの技術があり、これらが組み合わさって文脈に応じた出力を作ります。
- GPT-3論文は、Few-shot learning(少数例をプロンプト内に入れて振る舞いを変える使い方)を大規模に検証し、現在のプロンプト設計を理解する重要な入口になります。
2. LLMとは何か
LLMは、Large Language Modelの略で、日本語では大規模言語モデルと呼ばれます。
言語モデルとは、簡単に言えば「ある文脈の次に何が来そうか」を予測するモデルです。
たとえば、次の文があるとします。
今日は天気がいいので、近くの公園へこの続きを予測するなら、「行く」「散歩に行く」「出かける」などが自然です。
LLMは、このような続きを大量の文章から学習します。
ただし、現在のLLMは単に続きを書くだけの仕組みではありません。
質問、翻訳、要約、コード生成、対話、表形式の出力など、さまざまなテキスト形式を学習することで、入力された文脈に合わせた次tokenを予測します。
その結果として、ユーザーから見ると「質問に答えている」「翻訳している」「コードを書いている」ように見えます。
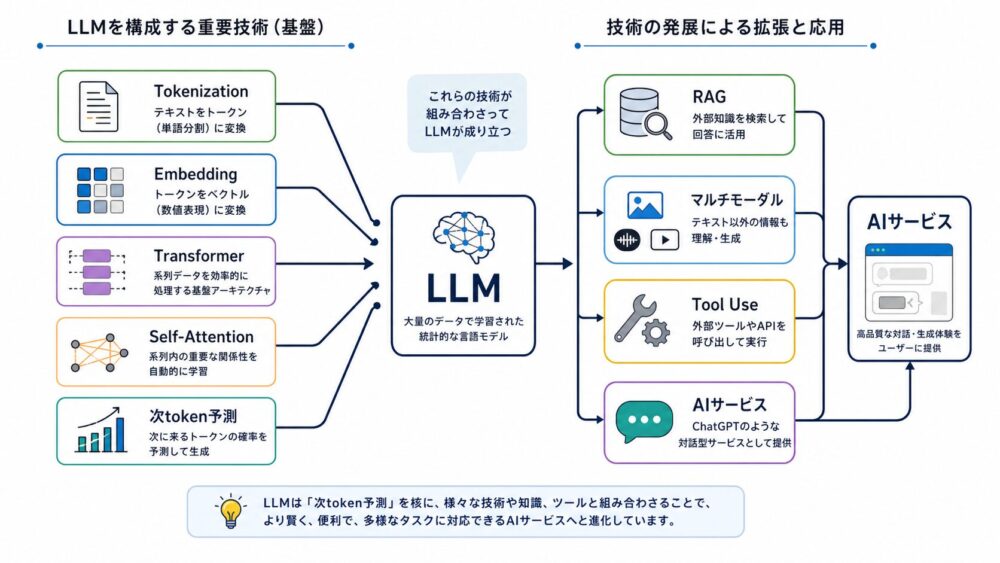
LLMを理解するうえで重要な技術は、次のように整理できます。
| 技術 | 役割 | シリーズ内リンク |
|---|---|---|
| Tokenization | 文字列をtokenへ分割し、モデルが扱えるID列に変換する | Tokenizationとは?SentencePiece論文からLLMのトークン化を解説 |
| Embedding | token IDを、意味や文脈を計算しやすいベクトルに変換する | Embeddingとは?BERT論文から単語・文章をベクトルで表す仕組みを解説 |
| Attention | 入力中の重要な情報を重み付きで参照する | Attentionとは?Bahdanau Attention論文からLLMの「どこを見るか」を理解する |
| Transformer | Attentionを中心にtoken列を並列に処理する基本アーキテクチャ | Transformerとは?Attention Is All You Need論文からLLMの基本構造をやさしく解説 |
| Self-Attention | 同じ文中のtoken同士の関係を計算する | Self-Attentionとは?Scaled Dot-Product Attentionを数式と実装でやさしく解説 |
| Positional Encoding / RoPE | tokenの順序や相対位置をモデルに渡す | Positional Encodingとは?RoPEでLLMが語順を扱う仕組みをやさしく解説 |
| Decoder-only Transformer | GPT系LLMで使われる、次token生成に向いたTransformer構造 | Decoder-only Transformerとは?GPT系LLMの仕組みを解説 |
2.1 LLMの基本的な処理の流れ
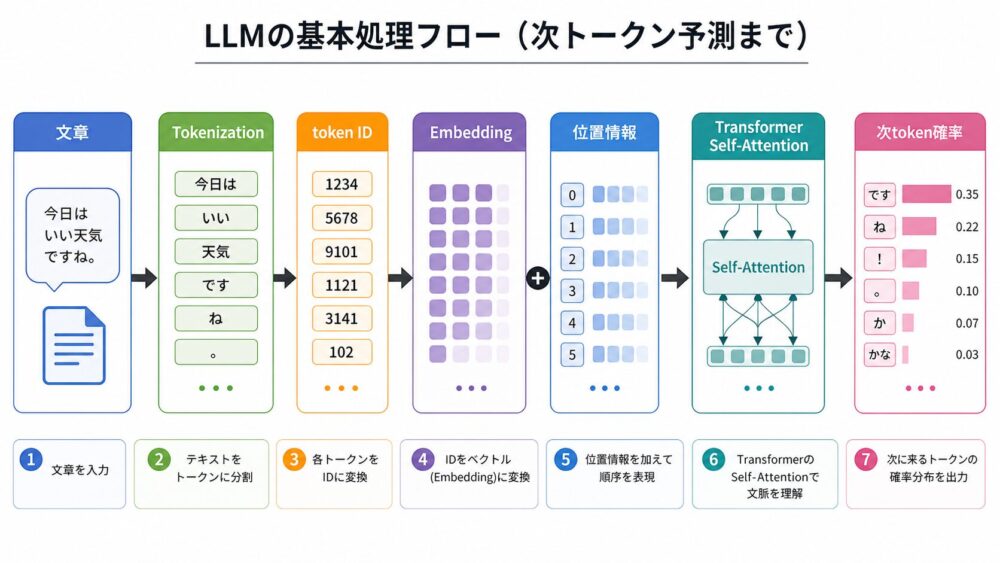
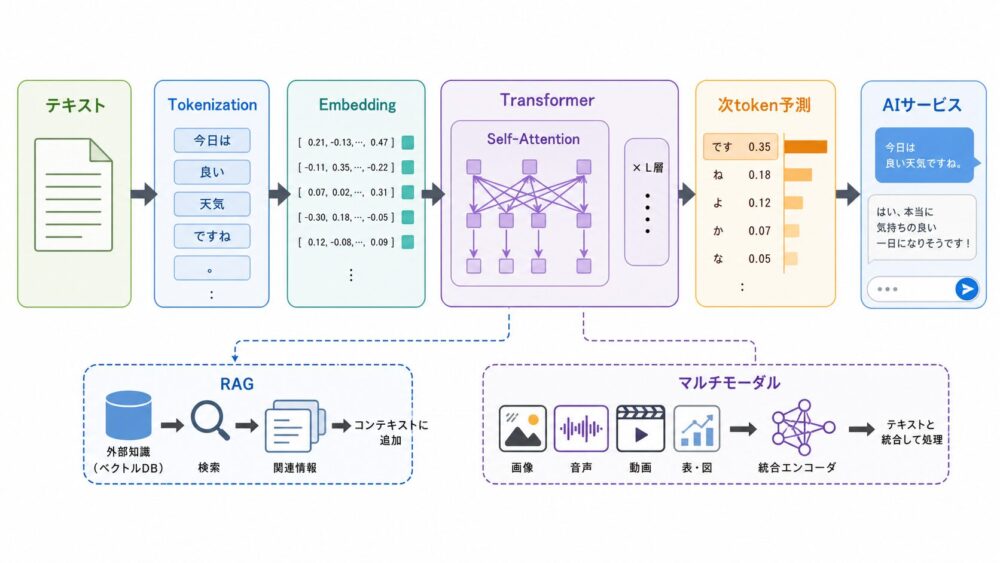
流れとしては、まず文章がTokenizationでtoken列になります。
次にEmbeddingでベクトルへ変換され、位置情報が加えられます。
Transformer内部ではSelf-Attentionが文脈中のtoken関係を計算し、その結果をもとに次tokenの確率分布を出します。
この「次tokenを予測する」基本動作を、非常に大きなデータと計算資源で学習したものがLLMの土台です。
2.2 現代AIサービスへの発展
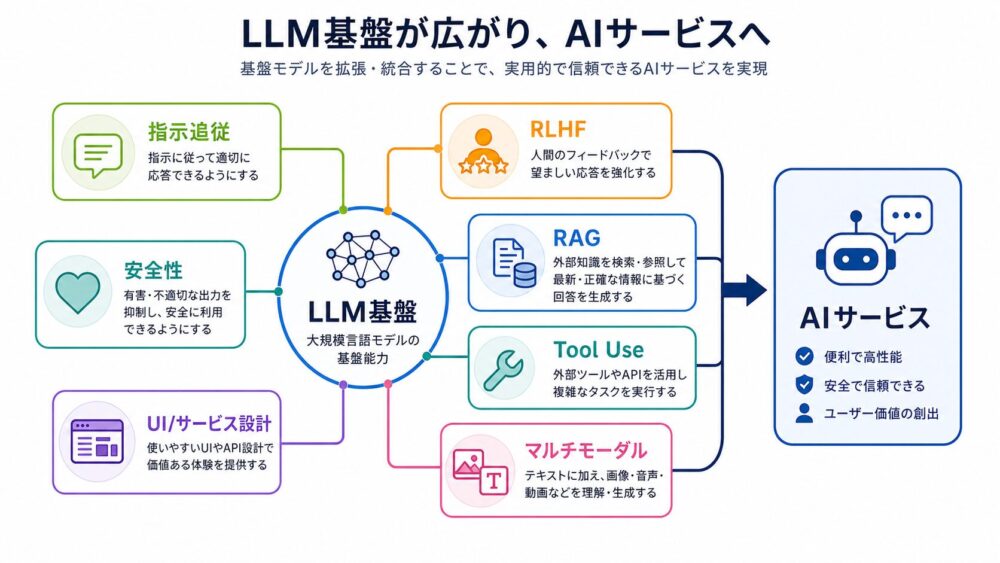
さらに現在のAIサービスでは、この土台の上に多くの技術が重なっています。
| 発展技術 | 何を補うか | 代表的な使いどころ |
|---|---|---|
| Instruction Tuning | 人間の自然言語指示に従いやすくする | チャット、業務アシスタント |
| RLHF | 人間にとって望ましい応答へ近づける | 安全性、会話品質 |
| RAG | 外部文書を検索して回答に使う | 社内文書QA、最新情報の参照 |
| Tool Use | APIや外部ツールを呼び出す | 予約、検索、計算、ワークフロー実行 |
| マルチモーダル | テキスト以外の画像・音声・動画も扱う | 画像理解、音声対話、資料解析 |
ChatGPTのようなAIサービスは、LLM単体だけで成立しているわけではありません。
次token予測を学んだ基盤モデルに、指示追従、対話最適化、安全性調整、検索、ツール実行、UI設計などが組み合わさることで、実用的なサービスになります。
2.3 このシリーズの推奨順
このシリーズは、次の順番で読むと理解しやすいです。
| 推奨順 | 記事 | 理由 |
|---|---|---|
| 1 | 本記事: LLM概要 | 全体像と読む順番をつかむ |
| 2 | Tokenization | 文字列がモデル入力になる入口を理解する |
| 3 | Embedding | tokenがベクトルになる仕組みを理解する |
| 4 | Attention | 必要な情報を参照する考え方を理解する |
| 5 | Transformer | LLMの基礎アーキテクチャを理解する |
| 6 | Self-Attention | Transformerの中心計算を数式寄りに理解する |
| 7 | Positional Encoding / RoPE | 語順や長文処理の土台を理解する |
| 8 | Decoder-only Transformer | GPT系LLMの生成構造を理解する |
3. GPT-3から読み解く
LLM全体を理解するうえで、GPT-3論文はとてもよい入口です。
理由は、現代のLLM活用でよく使われる「自然言語で指示する」「例を入れて出力形式を安定させる」「Fine-tuningなしでタスクを切り替える」という考え方を、大規模に検証した代表的な論文だからです。
ここからは、GPT-3論文をLLM理解の補助線として読みます。
3.1 論文情報
| 項目 | 内容 |
|---|---|
| 論文タイトル | Language Models are Few-Shot Learners |
| 著者 | Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan ほか |
| 公開日 | 2020年5月28日、最終改訂 2020年7月22日 |
| 分野 | Computation and Language |
| arXiv | Language Models are Few-Shot Learners |
| DOI | 10.48550/arXiv.2005.14165 |
GPT-3は、175B、つまり1750億パラメータの自己回帰型言語モデルとして発表されました。
当時の非スパースな言語モデルとして非常に大きく、LLM時代を象徴する論文の1つになりました。
3.2 GPT-3から読み解く
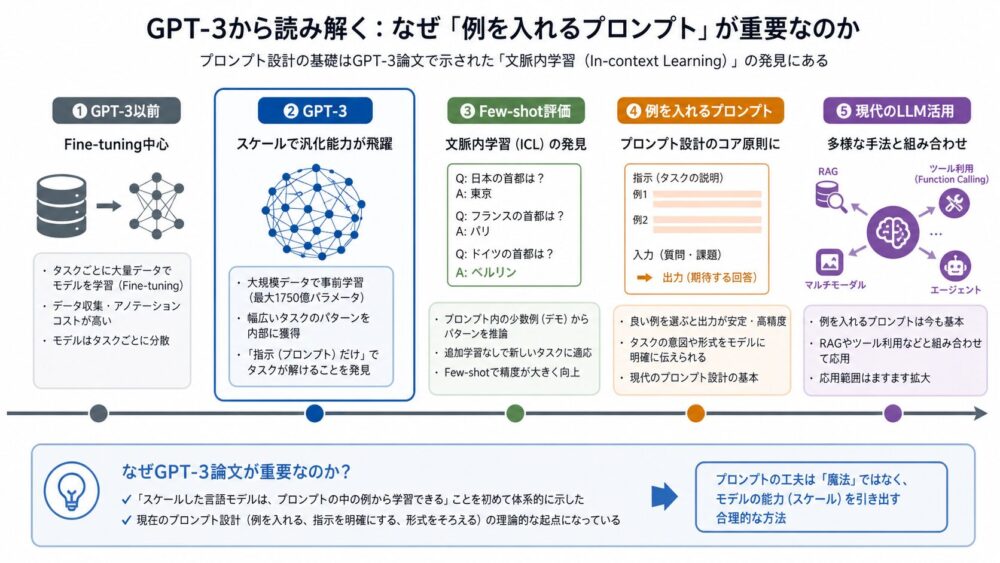
GPT-3論文以前にも、BERT、GPT-2、T5などの大規模な事前学習モデルは存在していました。
その多くは、まず大量のテキストで事前学習し、その後に特定タスクのデータでFine-tuning(特定タスク用に追加学習すること)する流れを取っていました。
この方法は強力ですが、タスクごとにデータ、学習、評価、運用を用意する必要があります。
| 方法 | 何をするか | 強み | 課題 |
|---|---|---|---|
| Fine-tuning | タスクごとの教師データで追加学習する | 特定タスクで高精度を出しやすい | タスクごとにデータと学習が必要 |
| Zero-shot | 例を与えず、指示だけで解かせる | 追加学習が不要 | 指示理解が難しい場合がある |
| One-shot | 1つの例をプロンプト内に入れる | 出力形式を伝えやすい | 例が少なく不安定なことがある |
| Few-shot | 少数の例をプロンプト内に入れる | タスク形式をその場で示せる | 長いプロンプトが必要になりやすい |
GPT-3論文が重要なのは、モデルの重みを更新せず、プロンプト内の指示や少数例だけで多様なタスクへ適応できるかを広く調べた点です。
今日のプロンプト入力では、「望む出力例を数個入れると安定しやすい」とよく言われます。
これは単なる経験則ではありません。
LLMはプロンプト全体を「すでに始まっている文章」として読み、その続きを予測します。
そのため、入力例と出力例があると、モデルは「この形式の続きを書けばよい」と推測しやすくなります。
GPT-3論文は、この使い方をFew-shot learningとして大規模に評価したため、現代のプロンプト設計を理解するうえで重要です。
3.3 GPT-3の基本構造
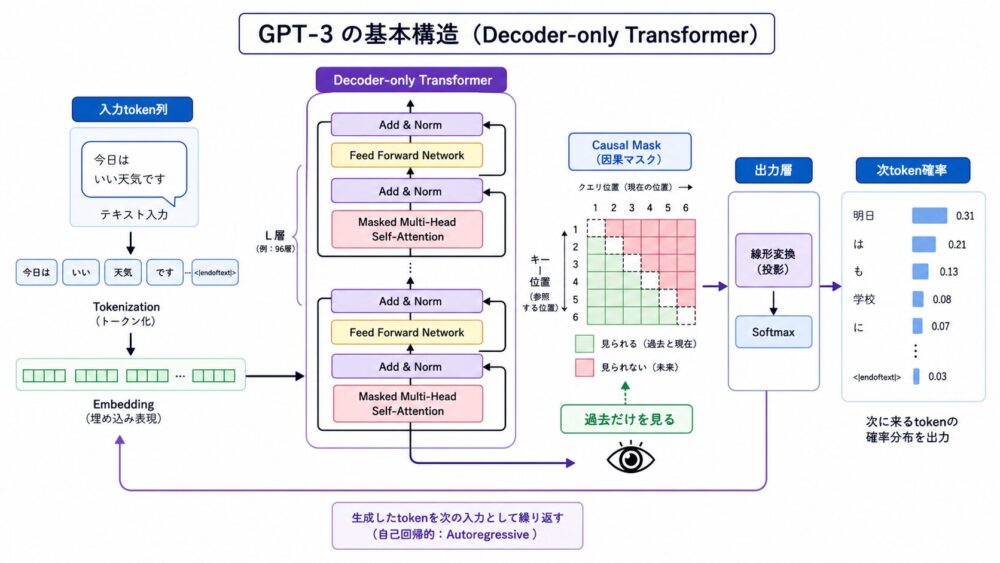
GPT-3は、自己回帰言語モデルです。
自己回帰(過去の出力や文脈を使って次を予測する方式)とは、左から右へ順番にtokenを予測する仕組みです。
入力: LLM は 文章 の
予測: 次に来るtokenモデルは、文脈 $u_1, u_2, …, u_{i-1}$ が与えられたとき、次のtoken $u_i$ の確率を学習します。
論文で扱われる基本的な学習目的は、次のように整理できます。
\[
L(U) = \sum_i \log P(u_i \mid u_{i-k}, …, u_{i-1}; \Theta)
\]
ここで、$U$ はtoken列、$k$ は参照する文脈長、$\Theta$ はモデルのパラメータです。
GPT-3論文の提案手法の中心は、新しい複雑なアーキテクチャを発明することではありません。
既存のTransformer系自己回帰言語モデルを非常に大規模にし、Zero-shot、One-shot、Few-shotの設定で広く評価した点にあります。
| ステップ | 内容 |
|---|---|
| 1 | 大規模なテキストコーパスで自己回帰言語モデルを事前学習する |
| 2 | 175Bパラメータまで複数サイズのモデルを用意する |
| 3 | Zero-shot、One-shot、Few-shotの設定で評価する |
| 4 | Fine-tuningせず、プロンプト内の指示と例だけでタスクを解かせる |
| 5 | モデルサイズと性能の関係を分析する |
GPT-3の土台はTransformerです。
Transformerは、Attention(入力中のどの部分を重視するかを計算する仕組み)を中心にしたニューラルネットワーク構造です。
Transformerの基本は、シリーズ第5回の Transformerとは?Attention Is All You Need論文からLLMの基本構造をやさしく解説 で詳しく扱っています。
GPT系モデルは、TransformerのうちDecoder-only Transformerと呼ばれる構造を使います。
これは、生成方向に合わせて過去のtokenだけを参照する構造です。
未来のtokenを見ないようにする点が特徴です。
3.4 Few-shot learningとは何か
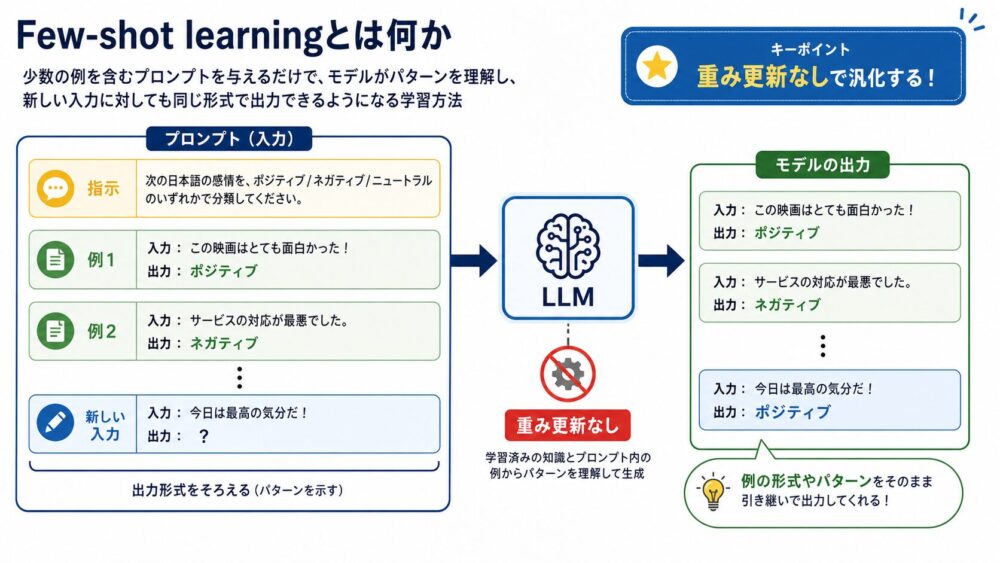
Few-shot learning(少数例からタスクを解く設定)は、GPT-3論文のキーポイントです。
ここは特に重要です。
GPT-3におけるFew-shotは、モデルを追加学習するという意味ではありません。
プロンプトの中に、いくつかの入出力例を並べます。
その後に、解かせたい入力を続けます。
たとえば感情分類なら、次のような形です。
文章: この映画はとても面白かった
分類: ポジティブ
文章: 待ち時間が長くて疲れた
分類: ネガティブ
文章: 店員さんの対応が丁寧だった
分類:モデルは、このプロンプトのパターンから「分類:」の後に何を出すべきかを推測します。
注目ポイント:Few-shotの本質は、モデルに「このタスクでは、こういう入力の後にこういう出力が続く」という文脈パターンを見せることです。
この仕組みは、現在のプロンプトエンジニアリングにもつながっています。
「あなたは技術編集者です」と役割を書くことも、「次のJSON形式で返してください」と出力形式を指定することも、「例: 入力A -> 出力B」を入れることも、LLMから見ると次tokenを決めるための文脈です。
出力例があるほど、モデルは「この後に何を書けば自然か」を狭い候補へ絞り込みやすくなります。
3.5 技術的な新規性
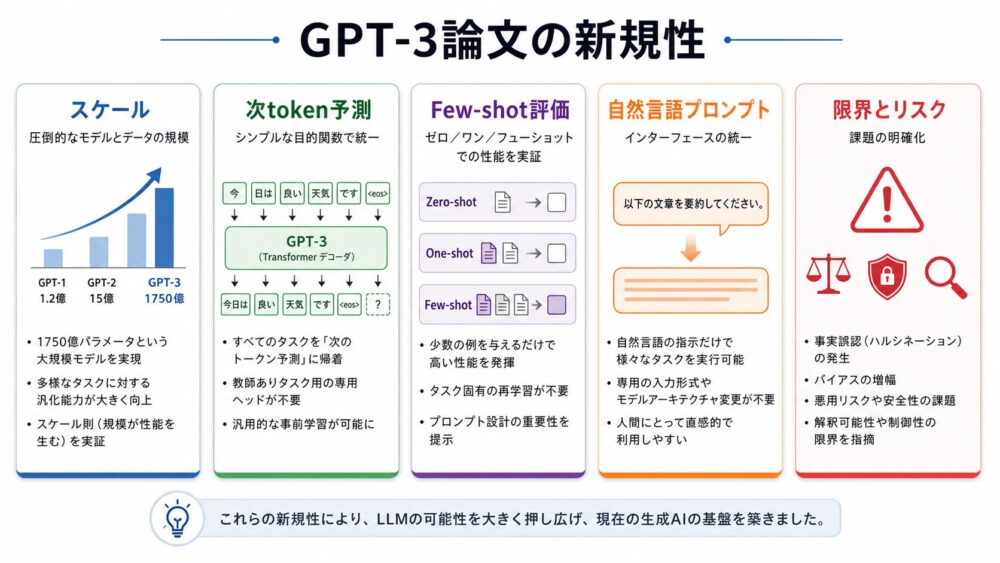
GPT-3論文の技術的な新規性は、単に「大きいモデルを作った」ことだけではありません。
重要なのは、スケール、学習目的、評価設定、インターフェースを組み合わせて、言語モデルの使い方を変えた点です。
| 観点 | GPT-3論文のポイント | 何が重要か |
|---|---|---|
| モデル規模 | 最大175Bパラメータ | 性能がモデルサイズに応じて改善する傾向を検証 |
| 学習目的 | 次token予測 | タスク固有の目的関数を使わず汎用的に学習 |
| 評価方法 | Zero-shot / One-shot / Few-shot | Fine-tuningなしのタスク適応を評価 |
| インターフェース | 自然言語プロンプト | ユーザーがテキストでタスクを指定できる |
| 社会的影響 | 生成文章の人間らしさも議論 | 悪用、バイアス、評価方法の課題を扱う |
この論文以降、「大規模に事前学習したモデルを、自然言語の指示や例で使う」という方向性が一気に重要になりました。
3.6 実験結果の要約

論文では、GPT-3が多くのNLP(Natural Language Processing、自然言語処理)ベンチマークで強いFew-shot性能を示したと報告されています。
代表的な傾向は次の通りです。
| 評価領域 | 論文での傾向 |
|---|---|
| 翻訳 | 一部設定で強い性能を示すが、言語や条件により差がある |
| 質問応答 | Few-shot設定で性能が改善しやすい |
| Cloze / 穴埋め | 言語モデルの得意領域として比較的強い |
| 常識推論 | モデルサイズ拡大で改善するが、苦手なデータセットもある |
| 算術 | 桁数や形式によって難しさが大きく変わる |
| 文章生成 | 人間評価で識別が難しいサンプルがあると報告されている |
ここで注意したいのは、GPT-3がすべてのタスクを完全に解決したわけではないことです。
論文でも、苦手なデータセットや評価上の問題が指摘されています。
特に、Web由来の大規模学習データには注意が必要です。
ベンチマークデータが学習データに混入している可能性、社会的バイアス、誤情報生成などは重要な論点です。
4. なぜ次token予測だけで多様なタスクができるのか
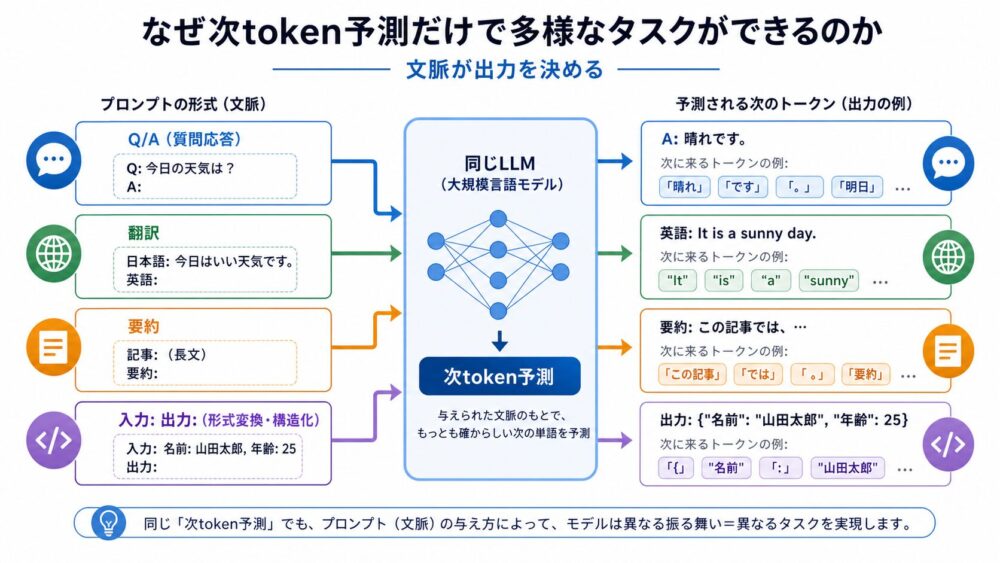
これはLLMを理解するときに一番不思議に見えるポイントです。
次token予測は、一見すると「文章の続きを当てるだけ」です。
しかし、大量のテキストには、説明、翻訳、対話、コード、問題と解答、表、手順書など、さまざまな形式が含まれています。
モデルがそれらの続きを予測するには、文脈の形式を読み取り、次に自然な文字列を出す必要があります。
たとえば、プロンプトに「英語を日本語に翻訳してください」と書かれている場合を考えます。
その場合、後ろには翻訳文が続く確率が高くなります。
いくつかの例を示せば、さらにその形式に合わせやすくなります。
| プロンプト内の形式 | モデルが予測しやすくなる次token |
|---|---|
Q: ... A: |
質問への回答文 |
English: ... Japanese: |
日本語訳 |
要約してください: ... 要約: |
要約文 |
入力: ... 出力: |
例と同じ形式の出力 |
つまり、LLMは入力された文章とは無関係な別文を突然作っているわけではありません。
質問文、区切り記号、出力欄、過去の例を含めたプロンプト全体を読みます。
それを「すでに始まっている文章」として扱い、その続きとして回答を生成しています。
この考え方を理解すると、プロンプトに役割や出力例を入れる理由も見えやすくなります。
役割は「どんな文体や観点で続けるか」を決める文脈になります。
出力例は「どんな構造で続けるか」を決める文脈になります。
Few-shot promptingは、この性質を意図的に使う方法です。
5. よくある誤解
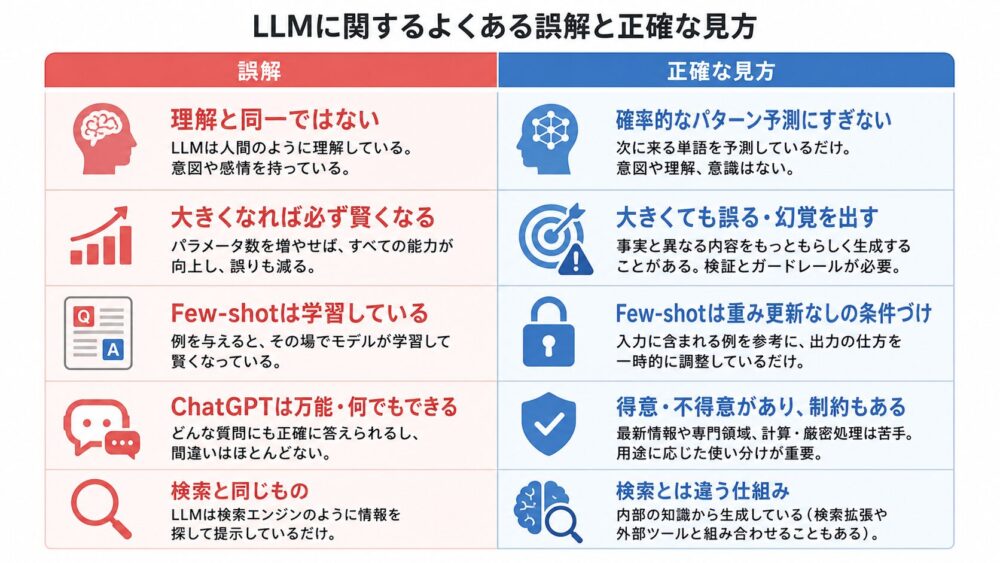
LLMについては、次のような誤解がよくあります。
| 誤解 | 正確な見方 |
|---|---|
| LLMは人間と同じ意味で文章を理解している | 内部表現として言語パターンを学習しているが、人間の理解と同一とは言えない |
| モデルを大きくすれば必ず正しくなる | 多くのタスクで改善傾向はあるが、誤情報やバイアスは残る |
| Few-shot learningは追加学習のこと | GPT-3文脈では、重み更新なしでプロンプト内の例から振る舞いを変えること |
| GPT-3はChatGPTと同じ | ChatGPTには指示追従や対話向けの追加調整が含まれる |
| LLMは検索エンジンのように事実を取り出している | 学習した確率分布から文章を生成しており、事実確認は別途必要 |
特に重要なのは、LLMの出力が「もっともらしい」ことと「正しい」ことは別だという点です。
RAGや外部ツール連携は、この限界を補うための実務上の重要な設計要素になります。
6. 実務でLLMを使うときのポイント
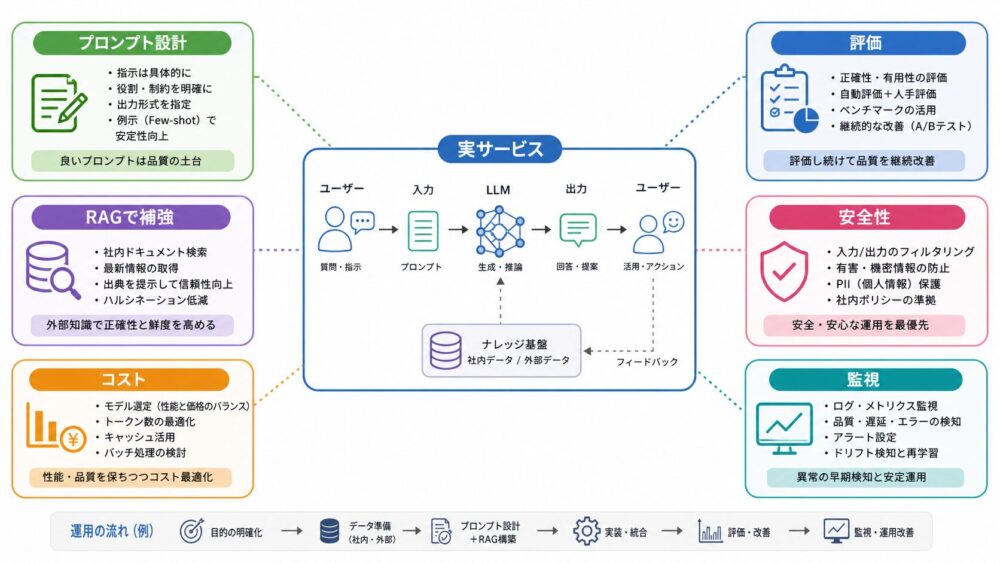
GPT-3論文から実務に引き寄せると、次のような示唆があります。
| 実務ポイント | 内容 |
|---|---|
| プロンプト設計 | 指示だけでなく、入出力例を入れると形式が安定しやすい |
| 評価 | タスクごとに正解率、再現率、人間評価などを設計する必要がある |
| 事実性 | 重要な情報はRAGや外部DBで補強する |
| 安全性 | バイアス、個人情報、誤情報、悪用リスクを考慮する |
| コスト | モデルサイズが大きいほど推論コストや遅延が増えやすい |
| 監視 | ログ、失敗例、ユーザー評価を継続的に確認する |
LLMは汎用性が高い一方で、すべてを1つのプロンプトで解決できるわけではありません。
実サービスでは、検索、ルールベース処理、ツール呼び出し、ログ監視、ユーザー体験設計と組み合わせることが重要です。
7. 限界点

GPT-3論文の結果を見るときは、以下の点に注意が必要です。
| 限界 | 内容 |
|---|---|
| 評価データ混入の懸念 | Web由来の大規模データでは、評価データが学習データに含まれる可能性がある |
| 苦手タスクの存在 | 複雑な推論、長い計算、厳密な事実確認では失敗することがある |
| 社会的バイアス | 学習データに含まれる偏りを反映する可能性がある |
| 推論コスト | 大規模モデルは計算資源と運用コストが大きい |
| 説明可能性 | なぜその出力になったかを完全に説明することは難しい |
論文では、生成文章の人間らしさや社会的影響についても議論されています。
LLMは便利な技術です。
一方で、出力の信頼性や利用範囲を慎重に設計する必要があります。
8. 今後の展望
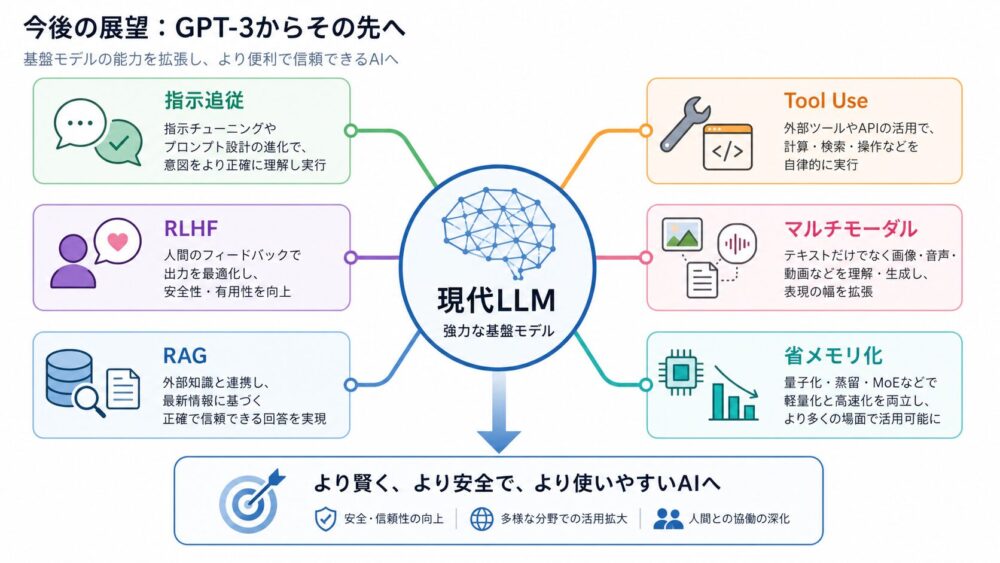 GPT-3以降のLLMが指示追従、RLHF、RAG、Tool Use、マルチモーダル、省メモリ化へ発展する流れ
GPT-3以降のLLMが指示追従、RLHF、RAG、Tool Use、マルチモーダル、省メモリ化へ発展する流れGPT-3以降、LLMは次のような方向へ発展してきました。
| 方向性 | 内容 |
|---|---|
| 指示追従 | 自然言語の命令により正確に従う |
| 対話最適化 | ユーザーとの複数ターン対話に適応する |
| RAG | 外部知識を検索して回答に使う |
| Tool Use | APIや外部ツールを呼び出す |
| マルチモーダル | 画像、音声、動画も扱う |
| 省メモリ化 | 量子化やKV Cache最適化で運用しやすくする |
LLMの基本は「次token予測」です。
その上に多くの技術が積み重なることで、現在の生成AIアプリケーションが成立しています。
今後のシリーズでは、基礎技術を押さえたあと、Fine-tuning、Instruction Tuning、RLHF、RAG、推論高速化、マルチモーダルAIへ進んでいきます。
9. まとめ
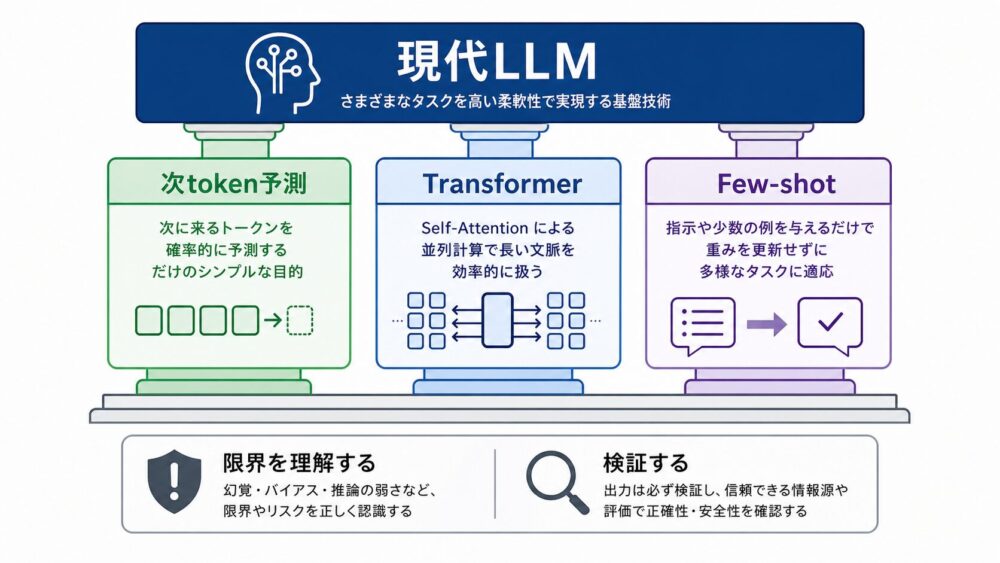
LLMとは、大量のテキストから次token予測を学び、入力された文脈に応じて文章を生成する大規模言語モデルです。
その動作は、Tokenization、Embedding、Transformer、Self-Attention、位置情報、Decoder-only構造などの技術が組み合わさって成り立っています。
GPT-3論文「Language Models are Few-Shot Learners」は、LLMを理解するうえで非常に重要な論文です。
この論文は、175Bパラメータの自己回帰言語モデルを扱い、Fine-tuningなしでも自然言語の指示や少数例を使って多様なタスクに対応できる可能性を示しました。
LLMを理解する入口としては、まず「大量のテキストで次tokenを予測する」「Transformerが文脈を扱う」「プロンプト内の例で振る舞いを変えられる」という3点を押さえると分かりやすいです。
ただし、LLMは万能ではありません。
誤情報、バイアス、評価データ混入、コスト、安全性などの課題もあります。
LLMを使うときは、できることと限界を分けて理解することが大切です。
10. 関連技術
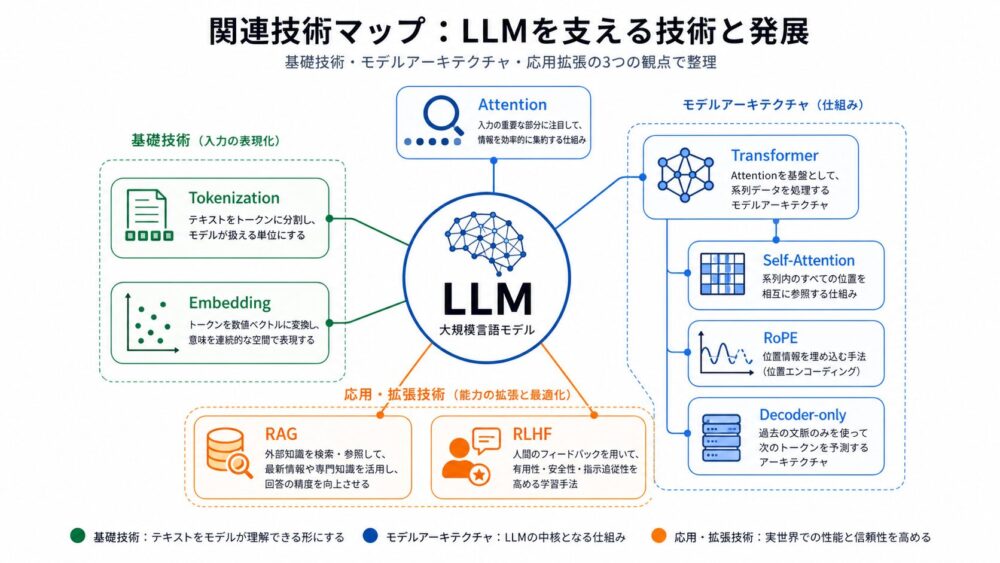
LLMの理解に関連する技術を、基礎から発展まで並べると次のようになります。
| 分類 | 関連技術 | 役割 |
|---|---|---|
| 入力処理 | Tokenization | 文章をtoken列へ変換する |
| 表現学習 | Embedding | tokenをベクトルに変換する |
| 情報参照 | Attention | 入力中の重要な部分を重み付きで参照する |
| 基本構造 | Transformer | Attentionを中心に系列を処理する |
| 文脈計算 | Self-Attention | 同じ系列内のtoken同士の関係を見る |
| 位置情報 | Positional Encoding / RoPE | tokenの順序や相対距離を扱う |
| 生成構造 | Decoder-only Transformer | GPT系LLMの次token生成を支える |
| 知識補強 | RAG | 外部文書を検索して生成に使う |
| 人間への適応 | Instruction Tuning / RLHF | 指示追従や応答品質を改善する |
参考になる代表的な論文・資料は次の通りです。
- Language Models are Few-Shot Learners
- Attention Is All You Need
- Language Models are Unsupervised Multitask Learners
- Training language models to follow instructions with human feedback
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
11. 次に読むべき記事
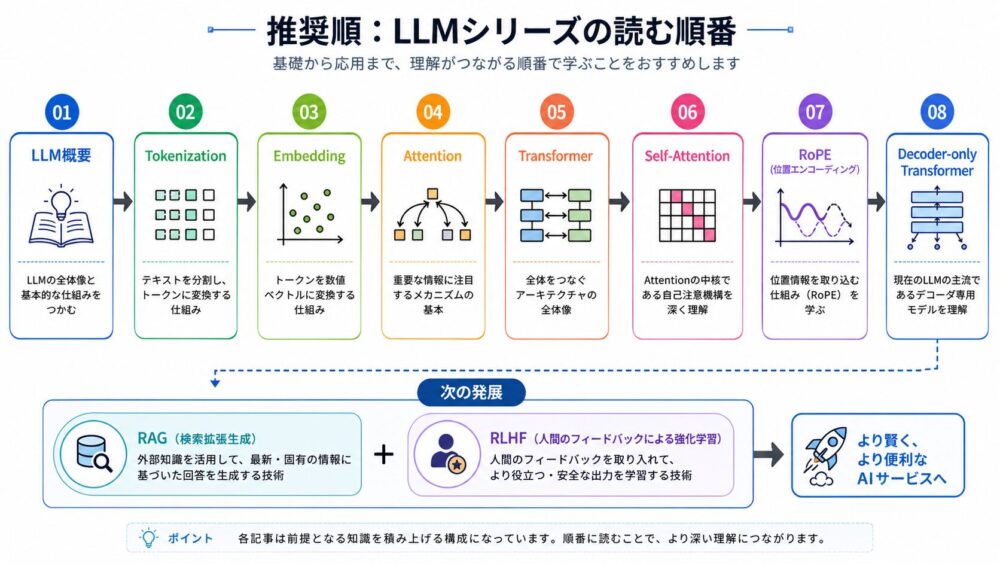
次に読むなら、まずTokenizationから進むのがおすすめです。
LLMは文章をそのまま読んでいるわけではありません。
文字列をtokenに分割し、それぞれをIDに変換してからモデルへ入力します。
特に日本語では、英語と比べてtokenizationの影響が見えにくいです。
それでも、コストや精度に関わるため重要です。
シリーズの推奨順は次の通りです。
- 本記事: LLMとは?ChatGPTの原点をGPT-3論文から読み解く
- Tokenizationとは?SentencePiece論文からLLMのトークン化を解説
- Embeddingとは?BERT論文から単語・文章をベクトルで表す仕組みを解説
- Attentionとは?Bahdanau Attention論文からLLMの「どこを見るか」を理解する
- Transformerとは?Attention Is All You Need論文からLLMの基本構造をやさしく解説
- Self-Attentionとは?Scaled Dot-Product Attentionを数式と実装でやさしく解説
- Positional Encodingとは?RoPEでLLMが語順を扱う仕組みをやさしく解説
- Decoder-only Transformerとは?GPT系LLMの仕組みを解説
この順番で読むと、LLMが「文字列をtokenにし、ベクトルにし、Attentionで文脈を見て、次tokenを生成する」流れを段階的に追いやすくなります。

コメント