LoRAとは何か?低コストなAIモデル微調整と、学習後にLoRAを圧縮するPARAの解説
論文情報
- 論文タイトル:Post-Optimization Adaptive Rank Allocation for LoRA
- arXiv:https://arxiv.org/abs/2604.27796v1
- 関連するLoRA原論文:LoRA: Low-Rank Adaptation of Large Language Models
- LoRA原論文:https://arxiv.org/abs/2106.09685
この記事で分かること
この記事では、まずLoRA(Low-Rank Adaptation:大規模モデルの重みを直接更新せず、小さな低ランク行列だけを学習する手法)の基本を説明します。
そのうえで、LoRAをさらに効率化する新しい手法である
PARA(Post-Optimization Adaptive Rank Allocation)
を解説します。
PARAは、LoRAを学習した後にSVD(Singular Value Decomposition:特異値分解)を使って不要なランク成分を削除し、層ごとに必要なランクだけを残す手法です。
LoRAとは何か
LoRAは、大規模言語モデルや画像生成モデルなどの巨大なニューラルネットワークを、低コストでファインチューニングするための手法です。
通常のファインチューニングでは、事前学習済みモデルの重み全体を更新します。
元の重みを \(W\)、ファインチューニング後の重みを \(W’\)、更新量を \(\Delta W\) とすると、次のように表せます。
\[
W’ = W + \Delta W
\]
通常のファインチューニングでは、この巨大な \(\Delta W\) を直接学習します。
しかし、モデルが大きくなるほど、学習対象のパラメータ数、GPUメモリ、Optimizer状態、保存容量が大きくなります。
そこでLoRAでは、\(\Delta W\) を直接学習せず、2つの小さな行列 \(A\) と \(B\) の積で表します。
\[
\Delta W = BA
\]
つまり、LoRAでは次のように重みを表します。
\[
W’ = W + BA
\]
ここで、元の重み \(W\) は固定し、学習するのは \(A\) と \(B\) だけです。
LoRAの数式
元の重み行列を次のように置きます。
\[
W \in \mathbb{R}^{d \times k}
\]
ここで、
- \(d\):出力次元
- \(k\):入力次元
です。
通常のファインチューニングでは、\(W\) 全体を更新するため、学習対象パラメータ数は次のようになります。
\[
d \times k
\]
一方、LoRAでは低ランク行列 \(A\) と \(B\) を使います。
\[
A \in \mathbb{R}^{r \times k}
\]
\[
B \in \mathbb{R}^{d \times r}
\]
ここで、\(r\) はLoRAのランクです。
通常は、\(r\) が \(d\) や \(k\) より十分小さくなるように設定します。
\[
r \ll \min(d, k)
\]
LoRAで学習するパラメータ数は次のようになります。
\[
r \times k + d \times r = r(d + k)
\]
つまり、通常のファインチューニングでは \(d \times k\) 個のパラメータを更新するのに対し、LoRAでは \(r(d+k)\) 個だけを更新すればよい、ということです。
また、実際のLoRAではスケーリング係数 \(\alpha\) を使い、forwardは次のように表されます。
\[
h = Wx + \frac{\alpha}{r}BAx
\]
ここで、
- \(x\):入力
- \(h\):出力
- \(\alpha\):LoRAのスケーリング係数
- \(r\):LoRAランク
です。
図で見るLoRAの基本アイデア
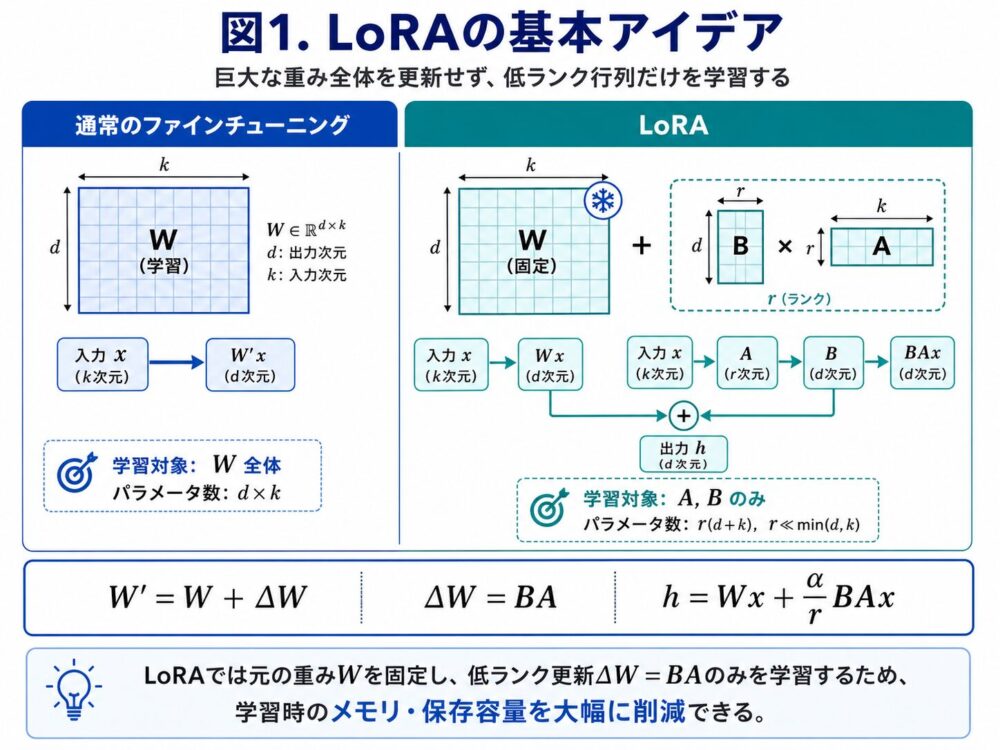
通常のファインチューニングでは、巨大な重み \(W\) 全体を更新します。
一方、LoRAでは元の重み \(W\) を固定し、横に小さな低ランクの経路を追加します。
具体的には、元の出力 \(Wx\) に対して、LoRAの出力 \(BAx\) を足し込みます。
そのため、LoRAの出力は次のようになります。
\[
h = Wx + \frac{\alpha}{r}BAx
\]
この仕組みにより、元のモデルを大きく変更せず、少ないパラメータだけでタスクに適応できます。
LoRAでどれくらいパラメータが減るのか
例として、1つの線形層を考えます。
\[
d = 4096
\]
\[
k = 4096
\]
\[
r = 8
\]
とします。
通常のファインチューニングでは、学習対象パラメータ数は次の通りです。
\[
4096 \times 4096 = 16,777,216
\]
一方、LoRAでは次のようになります。
\[
8 \times (4096 + 4096) = 65,536
\]
つまり、この例ではLoRAの学習対象パラメータは通常のファインチューニングの約1/256になります。
| 手法 | 学習対象 | パラメータ数 |
|---|---|---|
| 通常のファインチューニング | \(W\) 全体 | 16,777,216 |
| LoRA | \(A, B\) のみ | 65,536 |
このように、LoRAは学習時のパラメータ数を大幅に削減できます。
LoRAのメリット
LoRAの主なメリットは、単に「学習時のコストが下がる」だけではありません。
大きく分けると、以下のメリットがあります。
| 観点 | LoRAのメリット |
|---|---|
| 学習時メモリ | \(W\) の勾配を持たず、\(A, B\) だけを学習するため削減できる |
| Optimizer状態 | AdamなどのOptimizer状態を小さいLoRA行列分だけ持てばよい |
| 保存容量 | タスクごとに保存するのは小さいLoRAアダプタだけでよい |
| 複数タスク運用 | 1つのベースモデルを共有し、タスクごとにLoRAを切り替えられる |
| 推論時 | 必要に応じて \(W + BA\) にマージできる |
「LoRAは最終的にパラメータが増えるのでは?」という疑問
LoRAでは、元の重み \(W\) に加えて、追加の \(A\) と \(B\) を持ちます。
そのため、未マージの状態では、確かに保持するパラメータは次のようになります。
\[
W,\ A,\ B
\]
つまり、元のモデル単体と比べると、\(A, B\) の分だけパラメータは増えます。
しかし、重要なのは、\(A, B\) が非常に小さいことです。
また、推論時には次のようにマージできます。
\[
W_{\text{merged}} = W + BA
\]
このようにマージすれば、推論時には通常の重みと同じ形で扱えます。
\[
h = W_{\text{merged}}x
\]
したがって、LoRAは未マージ状態では少しパラメータが増えますが、学習対象やタスクごとの保存容量は大きく削減できます。
LoRAの真価は複数タスク運用で発揮される
LoRAは単一タスクでも有効です。
たとえば、1つのモデルを社内FAQ用に微調整するだけでも、学習時のGPUメモリや保存容量を減らせます。
しかし、LoRAの真価が特に発揮されるのは、複数タスクや複数ユーザー向けにモデルを運用する場合です。
通常のファインチューニングでは、タスクごとに巨大なモデル全体を保存する必要があります。
翻訳用モデル W_translation
要約用モデル W_summary
コード生成用モデル W_code
FAQ用モデル W_faq一方、LoRAでは共通のベースモデルを1つだけ持ち、タスクごとに小さなLoRAアダプタだけを保存します。
共通ベースモデル W
+ 翻訳用LoRA A_translation, B_translation
+ 要約用LoRA A_summary, B_summary
+ コード生成用LoRA A_code, B_code
+ FAQ用LoRA A_faq, B_faqこのため、複数タスクを扱う運用では、保存容量や管理コストを大きく削減できます。
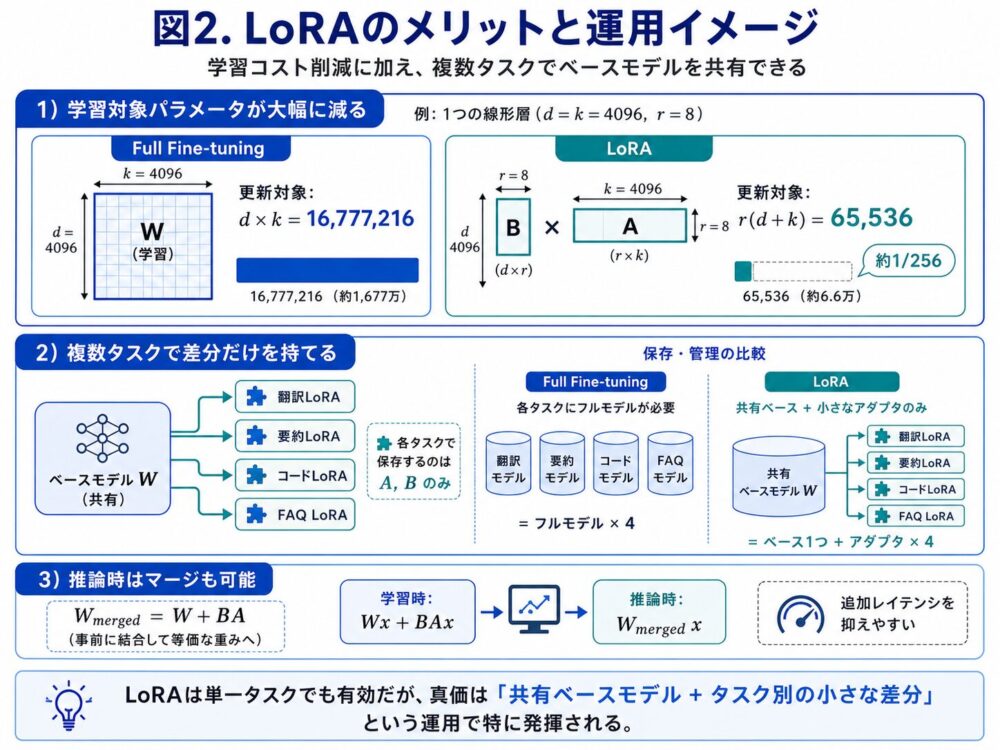
LoRAは、単一タスクでも学習コスト削減手法として有効です。
しかし、より大きな価値は、次の運用にあります。
共有ベースモデル + タスク別の小さな差分
LoRAの課題
LoRAは非常に便利な手法ですが、いくつか課題もあります。
特に重要なのが、ランク \(r\) の決め方です。
LoRAでは、すべての層に同じランクを設定することが多いです。
たとえば、すべてのLoRA対象層に対して、次のように一律で指定します。
rank = 16しかし、実際には層ごとに必要な表現力は異なります。
ある層ではrank 16が必要かもしれませんが、別の層ではrank 2で十分かもしれません。
さらに、場合によっては、ほとんど不要な層もあります。
つまり、すべての層に同じランクを割り当てると、不要なパラメータが残る可能性があります。
PARAとは何か
今回紹介する論文
Post-Optimization Adaptive Rank Allocation for LoRA
では、このLoRAのランク割り当て問題に対して、PARAという手法を提案しています。
PARAは、LoRAを学習した後に、各層のLoRA更新を解析し、重要な成分だけを残す後処理手法です。
正式名称は次の通りです。
Post-Optimization Adaptive Rank Allocation
日本語で言えば、学習後に適応的にランクを再配分する手法です。
ポイントは、学習中に複雑な制御を入れるのではなく、まず高ランクLoRAを普通に学習し、その後で不要なランク成分を削ることです。
論文では、この考え方を次のように表現しています。
Train First, Tune Later
PARAの基本アイデア
PARAの流れは以下の通りです。
- まず高ランクLoRAを通常どおり学習する
- 各層のLoRA更新 \(\Delta W = BA\) をSVDで分解する
- 全層の特異値をまとめて比較する
- 小さい特異値を削る
- 層ごとに必要なランクだけを残す
LoRAの更新行列は次のように表されます。
\[
\Delta W = BA
\]
PARAでは、この \(\Delta W\) に対してSVDを行います。
\[
\Delta W = U \Sigma V^T
\]
ここで、
- \(U\):左特異ベクトル
- \(\Sigma\):特異値
- \(V^T\):右特異ベクトル
- 特異値:その成分がどれだけ重要かを表す値
です。
大きい特異値を持つ成分は重要で、小さい特異値を持つ成分は影響が小さいと考えられます。
PARAは、この特異値を使って、どのランク成分を残すかを決めます。
PARAの図解
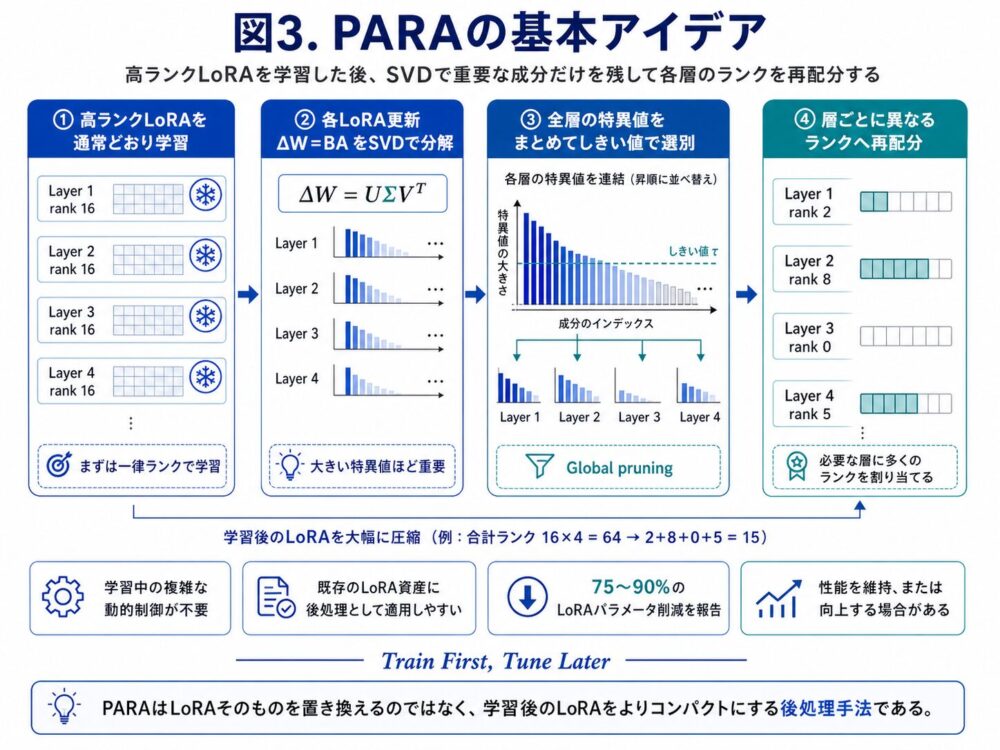
PARAでは、まず一律の高ランクLoRAを学習します。
たとえば、すべての層をrank 16で学習したとします。
Layer 1:rank 16
Layer 2:rank 16
Layer 3:rank 16
Layer 4:rank 16その後、各層のLoRA更新 \(\Delta W\) をSVDで分解し、特異値を調べます。
重要な特異値だけを残すと、層ごとに必要なランクは次のように変わるかもしれません。
Layer 1:rank 2
Layer 2:rank 8
Layer 3:rank 0
Layer 4:rank 5つまり、重要な層には多くのランクを残し、重要でない層は大きく削減します。
これにより、LoRA全体のパラメータ数を減らしながら、性能を維持しやすくなります。
PARAの特徴
PARAの特徴は、学習後に処理する点です。
既存のランク適応手法には、学習中にランクを動的に削るものがあります。
しかし、そのような手法では、pruning scheduleや正則化、重要度計算などを学習中に設計する必要があります。
一方、PARAは学習済みLoRAに対して後処理として適用できます。
| 手法 | ランク制御のタイミング | 特徴 |
|---|---|---|
| LoRA | 固定 | すべての対象層に同じrankを設定することが多い |
| AdaLoRAなど | 学習中 | 動的にランクを調整するが、学習設定が複雑になりやすい |
| PARA | 学習後 | 学習済みLoRAをSVDで解析し、後からランクを再配分する |
PARAは、LoRAそのものを置き換える手法ではありません。
むしろ、学習済みLoRAをさらにコンパクトにする後処理と考えると分かりやすいです。
PARAの2つの圧縮方針
論文では、圧縮の方針として主に2種類が説明されています。
γ-PARA
\(\gamma\)-PARAは、目標となる平均ランクを指定する方法です。
たとえば、次のように、メモリ予算や保存容量の制約から圧縮率を決めたい場合に使いやすい方法です。
平均rankを4にしたいε-PARA
\(\varepsilon\)-PARAは、保持するスペクトルエネルギー比を指定する方法です。
スペクトルエネルギーとは、特異値が持つ情報量のようなものです。
たとえば、次のように、性能維持を重視したい場合に向いています。
重要な情報量の95%を残したい| 方法 | 指定するもの | 向いているケース |
|---|---|---|
| \(\gamma\)-PARA | 目標平均ランク | メモリや保存容量の予算が明確な場合 |
| \(\varepsilon\)-PARA | 保持する情報量 | 性能維持を重視したい場合 |
PARAの実験結果
論文では、画像分類、自然言語理解、常識推論、数学推論などのタスクでPARAを評価しています。
比較対象には、通常のLoRAのほか、AdaLoRA、SoRA、DoRA、GoRAなどの手法が含まれています。
画像分類
画像分類では、CIFAR-10、CIFAR-100、EuroSAT、Oxford Flowers、Oxford-IIIT Pet、Stanford Cars、Food-101などで評価されています。
論文では、PARAが平均精度で通常のLoRAや他のランク適応手法を上回る結果が報告されています。
自然言語理解
自然言語理解では、RoBERTa Baseを使い、GLUE系タスクで評価されています。
こちらでも、PARAは通常のLoRAと同等以上の性能を示し、他の動的ランク手法より安定した結果を示しています。
常識推論・数学推論
常識推論や数学推論では、Gemma3-4Bを使った評価が行われています。
PARAは、LoRAパラメータを削減しながら、平均性能を維持または向上させる結果が報告されています。
論文全体としては、PARAにより75〜90%のLoRAパラメータ削減が可能でありながら、多くのタスクで性能を維持、または向上できるとされています。
LoRAとPARAの関係
LoRAとPARAの関係は、次のように整理できます。
| 項目 | LoRA | PARA |
|---|---|---|
| 目的 | フルファインチューニングを低コスト化する | 学習済みLoRAをさらに圧縮する |
| タイミング | 学習時 | 学習後 |
| 学習対象 | \(A, B\) | 新たな学習は基本的に不要 |
| 主な処理 | \(\Delta W = BA\) を学習 | \(\Delta W\) をSVDして重要成分を残す |
| メリット | 学習コストと保存容量を削減 | LoRAアダプタをさらに小さくできる |
LoRAは、巨大モデルの重み全体を更新せず、小さな低ランク行列だけを学習する手法です。
PARAは、そのLoRAで学習した低ランク更新をさらに解析し、不要な成分を取り除く手法です。
つまり、PARAはLoRAの後処理として機能します。
PARAが特に有効な場面
PARAは、特に次のような場面で有効です。
| 利用場面 | PARAが効く理由 |
|---|---|
| 多数のLoRAアダプタを保存する場合 | 各アダプタのサイズを削減できる |
| 複数タスク向けにLoRAを切り替える場合 | タスクごとの差分をより軽量化できる |
| GPUメモリやストレージが限られる場合 | 不要なランクを削ってメモリ効率を上げられる |
| 既存のLoRA資産がある場合 | 学習済みLoRAに後処理として適用しやすい |
| 学習中の複雑なランク制御を避けたい場合 | まず普通にLoRAを学習し、後から圧縮できる |
特に、サービス運用で多数のLoRAアダプタを管理する場合には、PARAのような後処理圧縮は実用的な価値が高いと考えられます。
注意点
PARAにも注意点はあります。
| 注意点 | 内容 |
|---|---|
| 高ランクLoRAで一度学習する必要がある | 最初の学習時にはある程度のランクを確保する必要がある |
| 圧縮率の選択が必要 | どこまで削るかはタスクや性能要件に依存する |
| すべてのタスクで必ず性能向上するとは限らない | 圧縮しすぎると性能が落ちる可能性がある |
| LoRA以外への適用は限定的 | 低ランク更新を前提にした手法である |
| 実運用ではレイテンシやロード時間の評価も必要 | 論文では主に精度とパラメータ削減が中心 |
PARAは強力な手法ですが、圧縮率を高くしすぎると性能低下のリスクがあります。
そのため、実際に使う場合は、圧縮率と性能のバランスを検証する必要があります。
まとめ
LoRAは、巨大モデルのファインチューニングを低コスト化する非常に有用な手法です。
通常のファインチューニングでは重み全体を更新しますが、LoRAでは元の重み \(W\) を固定し、低ランク行列 \(A, B\) だけを学習します。
\[
W’ = W + BA
\]
これにより、学習時のGPUメモリ、Optimizer状態、保存容量を大幅に削減できます。
また、LoRAの真価は、複数タスクや複数ユーザー向けに、次のように運用できる点にあります。
共有ベースモデル + タスク別の小さな差分
一方で、LoRAでは各層に同じランクを割り当てることが多く、層によっては不要なランク成分が残る可能性があります。
そこでPARAは、学習済みLoRAをSVDで解析し、重要な成分だけを残すことで、LoRAアダプタをさらに小さくします。
PARAの考え方は非常にシンプルです。
まず高ランクLoRAで学習する
↓
学習後にSVDで重要成分を調べる
↓
不要なランクを削る
↓
層ごとに必要なランクだけを残すつまり、LoRAが「学習を軽くする手法」だとすると、PARAは「学習済みLoRAをさらに軽くする手法」です。
今後、複数のLoRAアダプタを切り替えて運用する場面では、PARAのような後処理型の圧縮手法が重要になっていくと考えられます。
参考文献
- Post-Optimization Adaptive Rank Allocation for LoRA
 Post-Optimization Adaptive Rank Allocation for LoRAExponential growth in the scale of modern foundation models has led to the widespread adoption of Low-Rank Adaptation (L...
Post-Optimization Adaptive Rank Allocation for LoRAExponential growth in the scale of modern foundation models has led to the widespread adoption of Low-Rank Adaptation (L... arxiv.org
arxiv.org - LoRA: Low-Rank Adaptation of Large Language Models
LoRA: Low-Rank Adaptation of Large Language ModelsAn important paradigm of natural language processing consists of large-scale pre-training on general domain data and ada...arxiv.org




コメント