
【論文解説】SplitFT:LLMの分散ファインチューニングを実用化する適応型Split Learning
LLM(大規模言語モデル)の分散学習は、「計算負荷」「通信コスト」「データ偏り」という大きな課題を抱えています。
本記事では、それらを同時に解決する最新研究 SplitFT を分かりやすく解説します。
📄 論文情報
- タイトル:SplitFT: An Adaptive Federated Split Learning System For LLMs Fine-Tuning
- URL:https://arxiv.org/abs/2604.26388
TL;DR(要約)
- LLM分散学習の課題は「計算負荷・通信コスト・非IIDデータ」
- SplitFTはデバイスごとに分割位置を最適化
- LoRAにより通信量を削減しつつ性能を維持
背景:なぜこの研究が必要か?
① 計算リソース不足
LLMは巨大であり、エッジデバイスでは処理が困難です。
② データの分散(非IID)
各クライアントのデータ分布が異なり、学習が不安定になります。
③ 通信コストの増大
分散学習ではデータや特徴量のやり取りが必要で、通信量が膨大になります。
提案手法:SplitFTとは?
SplitFTは、以下を組み合わせたハイブリッド手法です:
- Federated Learning(データを共有しない分散学習)
- Split Learning(モデルを分割して学習)
システム構成(SplitFTの全体像)
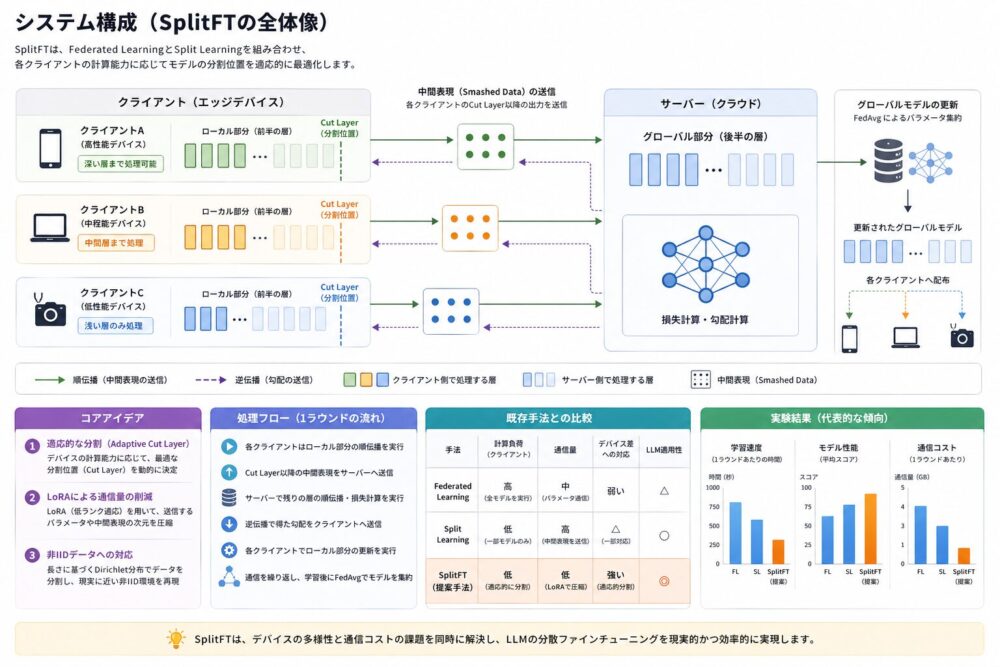
コアアイデア
① Adaptive Cut Layer(適応的分割)
デバイス性能に応じて、モデルの分割位置(cut layer)を動的に変更します。
高性能デバイスは深く、低性能デバイスは浅く処理します。
② LoRAによる通信削減
LoRA(Low-Rank Adaptation:低ランク近似による効率的学習)を用いて、通信するパラメータ量を削減します。
③ 非IIDデータへの対応
Dirichlet分布を用いて、現実的なデータ偏りを再現しています。
処理フロー
- モデルをクライアントとサーバに分割
- クライアントで前半部分を学習
- 中間表現をサーバへ送信
- サーバで後半部分を学習
- FedAvgで統合
既存手法との比較
| 手法 | 計算負荷 | 通信量 | デバイス差対応 | LLM適用性 |
|---|---|---|---|---|
| Federated Learning | 高 | 中 | 弱い | △ |
| Split Learning | 低 | 高 | △ | ○ |
| SplitFT | 低 | 低 | 強い | ◎ |
実験結果
- 学習速度:改善
- モデル性能:向上
- 通信コスト:削減
👉 既存手法を総合的に上回る結果を達成
この論文の本質
SplitFTの本質は、
LLMを現実的な分散環境で動かせるようにした点
にあります。
- 分割位置を動的に最適化
- LoRAで通信ボトルネックを解消
実務への応用
- オンデバイスAI(スマホ・カメラ)
- プライバシー保護学習
- エッジ×クラウド連携
👉 「端末ごとに性能が違う環境」に強い
まとめ
- LLM分散学習の主要課題を包括的に解決
- adaptive分割 + LoRAで効率化
- 実用性の高いアーキテクチャ
LLMをクラウド中心から、エッジ環境へ拡張する重要な一歩となる研究です。


コメント